Adaptive Budget Optimization For Multichannel Advertising Using Combinatorial Bandits
ABSTRACT
Section titled “ABSTRACT”Effective budget allocation is crucial for optimizing the performance of digital advertising campaigns. However, the development of practical budget allocation algorithms remain limited, primarily due to the lack of public datasets and comprehensive simulation environments capable of verifying the intricacies of real-world advertising. While multi-armed bandit (MAB) algorithms have been extensively studied, their efficacy diminishes in non-stationary environments where quick adaptation to changing market dynamics is essential. In this paper, we advance the field of budget allocation in digital advertising by introducing three key contributions. First, we develop a simulation environment designed to mimic multichannel advertising campaigns over extended time horizons, incorporating logged real-world data. Second, we propose an enhanced combinatorial bandit budget allocation strategy that leverages a saturating mean function and a targeted exploration mechanism with changepoint detection. This approach dynamically adapts to changing market conditions, improving allocation efficiency by filtering target regions based on domain knowledge. Finally, we present both theoretical analysis and empirical results, demonstrating that our method consistently outperforms baseline strategies, achieving higher rewards and lower regret across multiple real-world campaigns.
KEYWORDS
Section titled “KEYWORDS”Combinatorial Bandit, Non-stationarity, Digital Advertisement
1 INTRODUCTION
Section titled “1 INTRODUCTION”Digital advertising is a fast growing area of research, with the global market size approaching $700 billion in 2024 and projected to surpass $830 billion by 2026 [3]. In 2023, the average internet user spent around 6.5 hours daily engaging with content largely driven by advertisement. In the United States, digital advertising expenditure reached $189 billion in 2021 [29], showing a significant 35% year-over-year growth, driven in part by the COVID-19 pandemic. Despite economic challenges such as high inflation and rising interest rates, digital advertising continued to expand, reaching $225 billion in 2023 [30].
As the advertising sector continues to evolve, the number of subcampaigns within a portfolio grows [16], driven by diversification
across various formats (e.g., Search, Display, Video) and platforms (e.g., Google, Meta). To ensure profitability from delivering a diverse portfolio of campaigns, it is crucial to manage digital marketing budgets effectively (Fig 1). This resource allocation problem has attracted significant interest from the machine learning community [31] as logged data can be procured from different business campaigns. The presence of rich features in this data further fuels the development of automated decision-making systems, as learning algorithms are often better equipped to interpret multidimensional tabular data than human intuition.
Figure 1: Budget allocation across multiple sub campaigns in digital advertisement
Research on budget allocation algorithms remain limited, despite its importance for advertisers. A well-planned spending strategy is crucial, as campaigns with inadequate budgets may struggle to reach high-quality traffic. Effective budget allocation can significantly boost Return on Ad Spend (ROAS) by ensuring that ads are displayed where users are most likely to engage [25]. Multiarmed bandit strategies [2, 10, 27] have proven highly effective for budget allocation due to their simplicity, ease of analysis, and practical implementation in real-world systems. However, these algorithms often suffer from inefficient exploration and may struggle to adapt to the evolving behavior of campaigns over extended periods. Non-stationarity is a frequent issue in online advertising environments [21], where detecting changes and quickly adapting to them is critical.
*Work done during internship at Sony.
A significant bottleneck in studying this important problem is the lack of rich open-source datasets and robust simulation environments. Business data is often proprietary, and the datasets used in previous research are typically not publicly accessible [9, 19, 37], making it difficult to reproduce algorithmic results or build upon prior work. Moreover, directly testing budget allocation algorithms on real-world traffic can be both expensive and risky [26].
In this work we enhance the current budget allocation research with the following contributions:
- We design a simulation environment that is capable of simulating logged data exhibiting characteristics of multichannel ad campaigns running over multiple months. To the best of our knowledge this is the first environment simulating nonstationary multichannel ad campaigns. The environment and data sets are publicly available 1 facilitating further exploration and development in this area.
- We enhance the combinatorial bandit budget allocation strategy with modified mean function and a novel exploration utility. The exploration utility accounts for campaign efficiency and filters target regions based on domain knowledge resulting in faster adaptation for long running non stationary campaigns. We also incorporate change point detection to adapt to changing market conditions.
- We theoretically show that the proposed method has sublinear regret that is upper bounded by where T is the time horizon and reduces regret compared to standard exploration techniques. We empirically evaluate the proposed method on multiple real campaign data exhibiting higher reward, efficiency and lower regret compared with current SOTA baselines.
The paper is structured as follows: Section 2 reviews related work, Section 3 introduces the problem formulation, Section 4 covers the preliminaries, Section 5 presents the simulation environment, Section 6 discusses the algorithm and provides a theoretical analysis, and Section 7 reports the empirical results.
RELATED WORK
Section titled “RELATED WORK”Budget allocation across multiple ad campaigns [10, 13] has been extensively studied in industrial research by companies like Criteo [8], Netflix [23], and Lyft [20]. A common approach is to discretize the budget and model each sub-campaign as an arm in a multi-armed bandit problem. The optimal allocation is obtained by solving a combinatorial optimization problem [38] based on the expected reward of each arm. In previous literature, domain knowledge has been used to formulate parametric models of the arms, approximating the cost-to-reward function with a power law [18] or a sigmoid [16], followed by Thompson Sampling to handle uncertainty and induce exploration. However, these methods often overlook noise in the data, a critical factor in real-world deployments. In the presence of noise, parametric models can significantly deviate from the true reward function. A more flexible alternative is to model the reward function using Gaussian Process (GP) models [27, 28], which allow for greater adaptability. These algorithms typically use Upper Confidence Bound (UCB) or Thompson Sampling (TS) to guide exploration. However, unlike our approach, they do not
incorporate domain knowledge to promote exploration, which can lead to higher regret. Additionally, these algorithms are mostly studied for budget allocation for a single day or month [28] which does not account for changing behaviours of the reward function, a characteristic often observed in campaigns running over many
Handling non-stationarity in multi-armed bandits is a well-studied problem in the literature [4, 6, 32]. Common methods include passive approaches, such as sliding windows with UCB or TS sampling [36], or using discounted rewards [15]. Active methods, such as change point detection [5, 24], offer a more dynamic approach. Passive methods either discard older data points or assign them less weight. However, in long-running campaigns where nonstationarity changes occur infrequently, these approaches are less effective. For our algorithm, we adopt an active approach to better handle reward function shifts.
PROBLEM FORMULATION
Section titled “PROBLEM FORMULATION”We follow the standard formulation of the Automatic Budget Allocation (ABA) problem from the literature [27]. Consider an advertising campaign with , where each represents a sub-campaign in the portfolio. The campaigns run over a finite time horizon of days with a budget , where denotes the maximum budget that can be spent at time . For each day and sub-campaign , the advertiser must allocate a budget , where represents the minimum budget. After setting the budget, the platform determines the cost , and the advertiser receives feedback in the form of rewards (such as clicks or conversions) from an unknown function . The goal of the advertiser is to determine the optimal budget allocation across all sub-campaigns to maximize the cumulative return on investment. Formally, the problem is formulated as the following constrained optimization problem:
(1a)
s.t.
b_t \le b_{i,t} \le \bar{b}_t \quad \forall j \tag{1c}
(1)
Here, represents the cost spent on the sub-campaign at time t. The cost-to-reward relationship is dynamic, often changing over time due to market fluctuations. In particular, we focus on settings where the reward function changes abruptly, modeled as a piece-wise constant function of time that shifts a finite number of times. Formally, in the non-stationary setting, a break-point is defined as a round where the expected reward with respect to budget set B of at least one sub-campaign undergoes a change, i.e.,
<sup>1code contribution: https://github.com/sony/ABA
(2)
Let denote the set of breakpoints, with , partitioning the rounds into a set of phases , where each phase is defined as:
\mathcal{F}_{\phi} = \{ t \in \{1, \dots, T\} \mid p_{\phi - 1} \le t < p_{\phi} \}. \tag{3}
Within each phase , the reward function for sub-campaign remains constant and is given by:
To effectively detect abrupt changes in the reward functions, we follow two standard assumptions commonly used in non-stationary multi-armed bandit (MAB) settings [33]:
Assumption 1 , known to the learner, such that for each sub campaign whose expected reward changes between consecutive phases and , we have:
This lets the learner decide on a minimum possible magnitude of change such that the learner is able to detect it.
Assumption 2 There exists a time period , unknown to the learner, such that:
This prevents the breakpoints from being too-close to one another.
Assumption 3 Based on previous literature, the reward function at any phase exhibits the following properties [17, 19]:
- (1) is continuous and smooth to at least the second order.
- (2) is monotonically increasing with the cost (more spend always yields more clicks/conversions), i.e., .
- (3) has a diminishing marginal impact, i.e., .
4 PRELIMINARIES
Section titled “4 PRELIMINARIES”In a combinatorial semi-bandit framework [7], the agent selects a subset of options, referred to as super-arms, from a finite set of available choices, known as arms. This selection is subject to combinatorial constraints, such as the knapsack constraint. In this work, the reward of each arm is modeled using Gaussian Process Regression, and the optimization is solved using a multi-choice knapsack algorithm. We briefly explain each of these concepts as follows:
4.1 Gaussian Process Regression
Section titled “4.1 Gaussian Process Regression”Gaussian Process Regression (GPR) [34] is employed to model the relationship between budget allocation and resulting reward. GPR is a non-parametric, probabilistic method that provides both predictive mean and uncertainty estimates for a given set of inputs. Formally, a GP is defined as:
where represents the unknown function that relates the input variables (e.g., budget) to the output variables (e.g., clicks). The mean function is typically assumed to be zero. The covariance or kernel function encodes the correlation between any two input points.
The predictive mean and variance at a test point are given by:
where is the vector of covariances between the test point and each training input , and K is the covariance matrix computed over the training inputs, with entries and y is the observed mean. The term represents the variance of the noise in the observations.
The budget-to-reward relationship is modeled using the Radial Basis Function (RBF) kernel. The RBF kernel assumes a smooth and continuous relationship, defined as , where is the signal variance and l is the length scale.
4.2 Multi Choice Knapsack
Section titled “4.2 Multi Choice Knapsack”The optimization problem can be cast as a modified version of the knapsack problem from [22] called Multi Choice Knapsack (MCK). Given an estimated reward model of each sub-campaign and an evenly spaced discritization of the daily budget , the optimal reward for each sub-campaign can be identified through enumeration. The solution can be efficiently computed with a dynamic programming approach. The matrix M(j,b) with and . For a particular , The matrix is iteratively filled: each element is initialized as M(j,b) = 0 for all j and . For j = 1, the value is set:
This equation represents the best budget allocation for the sub-campaign if it were the only sub-campaign to consider. For j > 1, each matrix entry is updated as follows:
Then the maximum value among all combinations is selected. At the end of the recursion, the optimal solution is found by evaluating the matrix cell corresponding to:
To retrieve the corresponding budget allocation, the matrix is traced back to store the partial assignments that maximize the total value. The time complexity of this algorithm is , where N is the number of subcampaigns and represents the cardinality of the budget set.
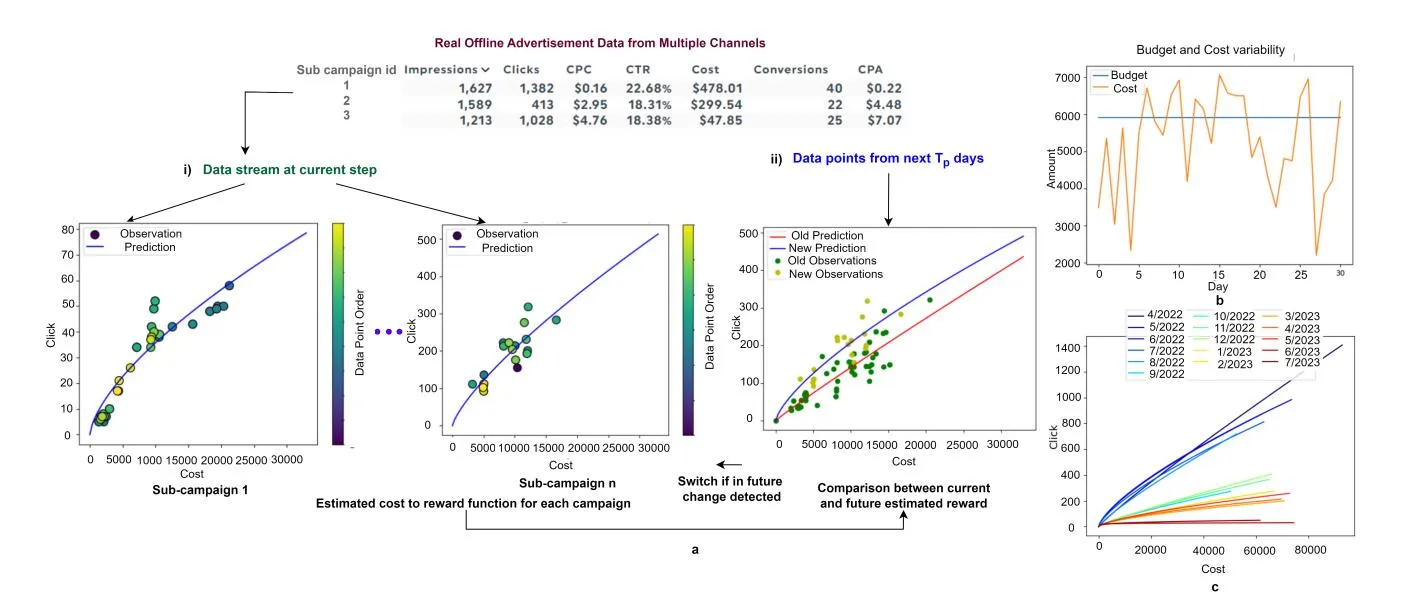
Figure 2: a) Architecture of the simulation environment where the reward function learned from the logged data b) Variability of budget to cost consumption in the environment c) Changing reward functions over different months in the environment
5 SIMULATION ENVIRONMENT
Section titled “5 SIMULATION ENVIRONMENT”A major challenge in studying budget allocation algorithms for digital ads is the lack of open-source simulation environment capable of simulating logged offline data. Previous studies have either relied on synthetic data [10, 27], which fails to fully capture realworld dynamics, or on proprietary data that is not publicly available [19, 37], rendering research results difficult to reproduce. Available real world datasets like criterio dataset [11] do not provide structured campaign groups and are limited to a time horizon of 30 days. To bridge this gap, we designed a simulation environment that mimics the behaviour of long running ad campaigns from logged data. The simulation environment and the logged data will be released publicly to facilitate reproducible research. The architecture of the simulation environment is depicted in Fig 2a.
The daily budget is set as per the total monthly cost consumed by all the campaigns of a campaign group divided by the number of days per month. In any realistic ad delivery platform the actual spent cost , is in not equivalent to the allocated budget and depends on the platforms internal learning algorithms. For example the Google Ads platform provides the following guidelines [1] : 1) The spent amount can be lower or 2 times higher than the daily budget on any particular day. 2) The total spent budget is not more than 30.4 the average daily budget. We model this variability in daily budget spent using a truncated normal distribution:
(4)
The cost variability is shown in Fig 2b. Following [19] we model the cost to reward function of each sub campaign as a power law function with noise.
n_j(x_{j,t}) = \alpha_c * x_{i,t}^{\omega_c} + \epsilon \tag{5}
Where adds a small error in observation. The simulation environment updates the reward model every day with data points from the logged data of that day. The parameters and are estimated from data using curve fitting as shown in Fig 2a i). In order to model abrupt changes between the reward functions we maintain a power law model and for the next days from the current time point in simulation (Assuming a stationary period of length ) of data. If a change is detected, i.e., when and differ more than 20%, the current model is replaced with the future model on the onset of detected change as shown in Fig 2a ii). This allows the function to change at arbitrary points during the run of the campaign as would happen in a real campaign as depicted in Fig 2c.
6 AUTOMATIC BUDGET ALLOCATION ALGORITHM
Section titled “6 AUTOMATIC BUDGET ALLOCATION ALGORITHM”The ABA algorithm is summarised in Algo 1 which involves the following broad steps:
- (1) Estimation of reward function using GP
- (2) Predicting rewards for each arm of the bandit
- (3) Allocating budget using multi-choice knapsack
- (4) Change point detection.
The algorithm enhances the automatic budget allocation strategy to cater to practical considerations. In any multichannel advertising application exploration is expensive. This means we should be selective about spending budget in regions where we expect higher gains. First we observe that a zero-mean Gaussian Process Regressor as used in [28] obtains a pessimistic prior over the budget range as depicted in Fig 3 (i). This prior restricts effective exploration to higher ranges of budget where quality traffic might be present. To address this, we modify the mean of the GP model with a saturating mean function for each sub-campaign as follows:
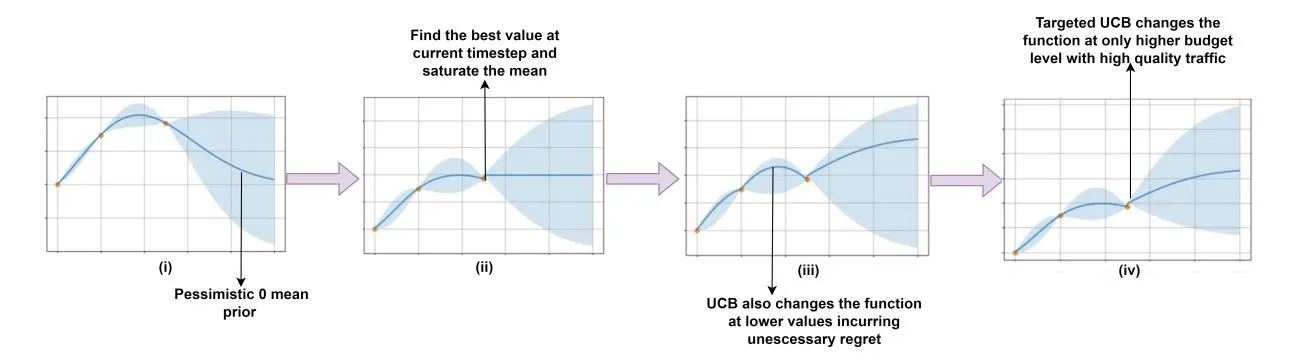
Figure 3: A simple representation of the GP estimation with saturated mean and targeted UCB exploration
(6)
Where is the GP estimate of with time subscript removed for brevity and is the current budget level with highest reward value for campaign j and . This allows the mean to saturate at the last estimated maximum observed reward for a campaign as shown in Fig 3 (ii). Next, we introduce a modified Upper Confidence Bound exploration strategy to enhance the performance of the combinatorial bandit approach. The modified exploration strategy is defined as follows:
\tilde{n}_{j}(\cdot) \leftarrow \hat{n}_{j}(\cdot) + \{\beta * (1 - \theta_{j}) * \sigma_{j}\} | \mathbb{I}_{b_{j,j} > b_{j,max}} \tag{7}
Where is the exploration factor for balancing exploration and exploitation. The proposed modified UCB promotes the following:
- represents the efficiency of arm j. For example, Cost per Click (CPC) can be used as when maximizing clicks where . is the normalized cost per click of sub campaign j. A lower cpc denotes higher efficiency of the sub-campaign. The inclusion of term incentivizes the policy to perform aggressive explorations for efficient arms. This term can be replaced by any other metric of efficiency as per advertiser’s objective. For example, the Cost per Acquisition (CPA) can be chosen as the exploration incentive during maximizing conversions.
- The term denotes and indicator function that checks whether a discritized budget level used by MCK is higher than the current observed budget level having highest predicted reward. The uncertainty based exploration is only targeted towards regions that contain more information than the current best knowledge as illustrated in Fig 3 (iv). Without this targeted exploration the algorithm may incur unnecessary regret by exploring lower budget levels as shown in Fig 3 (iii).
For the non stationary change detection we maintain two models. denotes the model which estimates the reward function for data points of phase until break-point is detected. denotes the model using data points from current .
Algorithm 1 TUCB-MAE
Section titled “Algorithm 1 TUCB-MAE”Require: Set B of discretized budget values, Initial Old Model \{\mathcal{M}_{i}^{(0)}\}_{i=1}^{N}, Current Model \{\tilde{\mathcal{M}}_{i}^{(0)}\}_{i=1}^{N}, Daily Budget limit \bar{b}_{t}, time horizon T, Memory buffer 1: for t \in \{1, ..., T\} do for j ∈ {1, . . . , N} do if t = 1 then 3: \mathcal{M}_j \leftarrow \mathcal{M}_j^{(0)}\tilde{\mathcal{M}}_j \leftarrow \tilde{\mathcal{M}}_j^{(0)} 4: 5: y_{j,t} = n_j(x_{j,t}) buffer.append(y_{j,t}, x_{j,t}) \mathcal{M}_i \leftarrow \text{Update}\left(\mathcal{M}_i, buffer\right) \tilde{\mathcal{M}}_{i} \leftarrow \text{Update}\left(\tilde{\mathcal{M}}_{i}, buffer[: window_{length}]\right) 10: 11: Check Eq 8 > \tau to detect breakpoint if breakpoint then buffer \leftarrow buffer[: window_{length}] 15 Use Eq 6 to saturate mean 16: Use Eq 7 to select the next exploration points 17: 18: \{(\hat{x}_{j,t})\}_{j=1}^N \leftarrow \text{Optimize}\left(\{(\tilde{n}_j(\cdot), B)\}_{j=1}^N, \bar{b}_t\right) Pull (\hat{x}_{1,t},\ldots,\hat{x}_{N,t})21: end forWe then perform change point detection using a Mean Average Error test over the entire budget set to check if the predictions from the models have changed beyond a threshold .
(8)
MAE is used due to its ease of implementation for practical usage. Any sophisticated change point detection strategy can be used in place of MAE. If a change is detected the data buffer is refreshed with the current data denoting the start of a new phase .
We now theoretically analyze the regret bound of the proposed method and show that the regret bound reduces for the proposed UCB utility under Assumption 3.
Lemma 6.1 (From [35]). Given the realization of a GP , the estimates of the mean and variance for the input b belonging to the input space B, for each the following condition holds:
for each .
PROPOSITION 6.2. Let us consider an ABA problem over T rounds where the function is the realization of a GP, using TUCB-MAE algorithm with the following upper bound on the reward function :
where b is a budget level,n denotes the round and j is the campaign, with probability at least , it holds:
where the notation disregards the logarithmic factors.
Proof Sketch: It can be derived regret is lower bounded by where a is the action with for campaign j. Using Lemma 5.6 of [35], the information gain provided by the observations corresponding to the actions is:
and can be bounded by
and regret can be derived as a lower bound of IG, with For every the following holds with probability at least (using Lemma 6.1),
where is the variance of the measurement noise of the reward function and is the total information gain.
Since the regret is bounded by information gain, if we explore values of , by monotonicity, we have:
Where is the budget level with maximum reward of arm j. This means that exploring in this region incurs unnecessary regret because we are not gaining new information about potentially better actions. By restricting exploration to values , the effective space of arms to explore is reduced. This reduces , which in
turn reduces the regret bound. Specifically, if we denote the restricted exploration space by , we have:
Thus, under monotonocity assumption of
detailed proof is given in supplementary material.
7 EMPIRICAL STUDIES
Section titled “7 EMPIRICAL STUDIES”We perform empirical experiments on multiple real logged campaign data obtained from different platforms. We denote the different advertisement platforms as Platform A and Platform B. The hyper-parameter choices are reported in supplementary material. For experimental analysis we choose assuming a stationary period of 20 days and days. The budget discretization granularity is 500. We simulate these campaigns in the simulation environment allowing the experiments to be conducted for long running campaigns with changing behaviour due to market dynamics. The noise is sampled from a normal distribution . The proposed algorithm is compared against the following SOTA baselines:
- (1) UCB MAE: Represents a combinatorial multi-arm bandit strategy with upper confidence bound for exploration and mean average error for change point detection. Represents the class of active approaches where the reward function is re-learned based on change point detection [33]. Comparison shows superiority of our proposed exploration utility.
- (2) UCB NCPD: Is a combinatorial bandit strategy with UCB exploration and no change point detection depicting the importance of change point detection.
- (3) UCB SW [15] : Represents a combinatorial bandit algorithm with UCB exploration and sliding window of fixed length (10 days) for non stationary adaption and same exploration parameter β as our algorithm.
- (4) TS-SW [14]: Represents a combinatorial bandit algorithm with thompson sampling exploration and sliding window of fixed length (10 days) for non stationary adaption.
- (5) UCB-DS [15]: A combinatorial bandit strategy with discounting past data using a factor 0.9 and UCB exploration strategy.
We report the results in Table 1 with respect to three metrics explained as follows:
Clicks: A higher number of clicks generally reflects increased user engagement, making it a key measure of effective budget allocation. Regret: We report the average cumulative regret compared to an oracle optimizer which has access to the parameters of the true reward function in the simulation environment.
Cost Per Click (CPC): The average cost per click for all the sub-campaigns in a campaign group. A lower CPC denotes higher ROAS and efficiency for advertisers.
Table 1: Comparison of proposed algorithm with SOTA baselines using logged campaigns for real products running on different ad delivery platforms reported for random seeds 1, 42, and 76. The reported values have been divided by 1000. Each row in the table represents the cumulative Clicks↑, Regret↓ and CPC (¥) ↓ of each method.
| Product Type | Sub cam paign Groups | Duration | Metric | TUCB MAE (Ours) | UCB-MAE | UCB-NCPD | UCB-SW | TS-SW | UCB-DS |
|---|---|---|---|---|---|---|---|---|---|
| Attendance System Platform A | Search-1 Search-2 Display | 01-07-22 - 30-07-23 | Clicks ↑ Regret ↓ CPC ↓ | 55.62 ± 1.35 14.97 ± 1.39 52.94 ± 0.83 | 44.52 ± 1.31 25.39 ± 1.40 63.80 ± 2.54 | 53.10 ± 0.60 17.59 ± 0.74 53.43 ± 0.36 | 47.27 ± 2.06 22.65 ± 2.05 59.64 ± 1.64 | 49.34 ± 2.63 20.60 ± 2.57 58.47 ± 3.01 | 29.82 ± 2.88 40.02 ± 2.68 85.72 ± 1.29 |
| Predictive Analysis Tool Platform A | Search Display Discovery | 01-04-22 - 10-09-23 | Clicks ↑ Regret ↓ CPC ↓ | 243.11±6.78 66.71 ± 5.36 32.31 ± 1.87 | 218.84 ± 7.36 78.45 ± 6.74 47.62 ± 1.47 | 220.98 ± 6.77 76.86 ± 6.72 46.62 ± 1.46 | 217.44 ± 7.24 80.95 ± 7.43 46.36 ± 1.40 | 138.75 ± 0.91 156.90 ± 0.83 119.27 ± 1.49 | 187.71 ± 7.74 1099.52±7.21 67.81 ± 1.27 |
| Internet Service Provider Platform A | Search Display Discovery | 01-04-22 - 19-10-22 | Clicks ↑ Regret ↓ CPC ↓ | 4.90 ± 0.09 226.49±0.08 35.93 ± 0.20 | 4.52 ± 0.03 227.43 ± 0.04 37.30 ± 0.22 | 4.72 ± 0.04 226.63 ± 0.03 36.41 ± 0.32 | 4.75 ± 0.09 226.61 ± 0.07 36.18 ± 0.54 | 4.65 ± 0.21 226.70 ± 0.20 37.23 ± 1.09 | 3.92 ± 0.06 227.41 ± 0.06 42.00 ± 0.32 |
| Product 17276 Platform B | 5 Display | 01-10-23 -01-07-24 | Clicks ↑ Regret ↓ CPC ↓ | 227.79±3.18 35.38 ± 3.13 9.47 ± 0.07 | 214.42 ± 4.46 48.45 ± 4.43 10.00 ± 0.08 | 215.33 ± 2.51 47.51 ± 2.56 9.92 ± 0.03 | 214.36 ± 1.72 48.53 ± 1.70 9.91 ± 0.06 | 223.01 ± 3.38 39.99 ± 3.20 9.63 ± 0.03 | 201.57 ± 2.38 61.44 ± 2.43 10.26 ± 0.06 |
| Product 15981 Platform B | 4 Display | 01-10-23 - 01-07-24 | Clicks ↑ Regret ↓ CPC ↓ | 105.92±3.06 20.35 ± 2.87 21.93 ± 0.20 | 93.97 ± 9.59 31.64 ± 9.31 26.81 ± 2.79 | 82.22 ± 10.64 43.15 ± 10.57 29.20 ± 2.57 | 92.79 ± 10.41 32.91 ± 9.93 27.07 ± 2.51 | 92.45 ± 7.80 32.96 ± 7.74 27.33 ± 2.91 | 73.23 ± 10.49 52.09 ± 10.45 31.91 ± 2.83 |
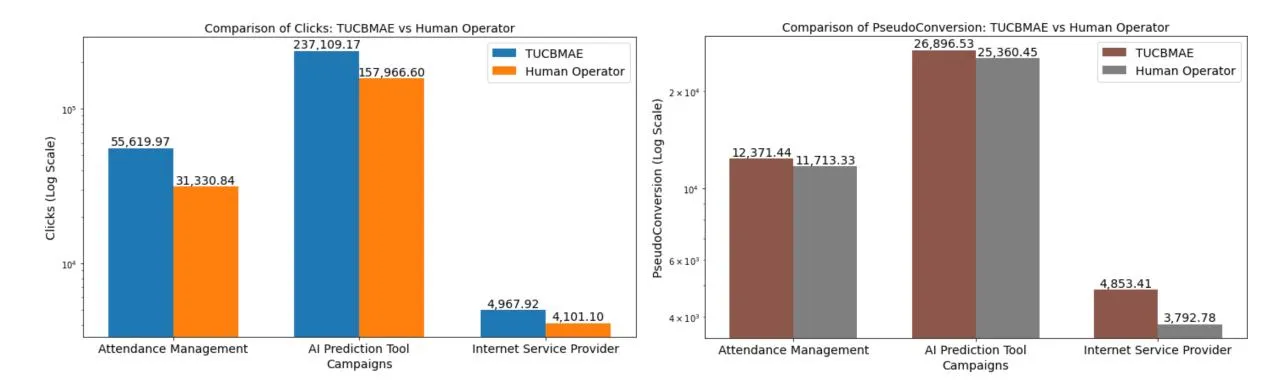
Figure 4: Comparison with respect to the human operator’s budget allocation from the logged dataset
The algorithms are tested across different types of products with varied user base as reported in Table 1. Each product contains of multiple sub-campaigns running together for more than 5 months. The sub-campaigns are distributed across multiple channels. Display advertisements visually engaging ads placed at different web-channels that a user visits. Search campaigns allows advertisements to be placed across a search engine’s network of search results. Search-1 campaigns target users searching with specific product related keywords whereas Search-2 campaigns target a wider audience with generic keywords related to the domain of the product. The results in Table 1 exhibits the effectiveness of the proposed algorithm with higher clicks, lower regret and lower cpc for all products. We also note that discounted reward based adaptation strategy renders the lowest performance as providing lower weights to past observation refrains GP from adapting to the true function. In Fig 5 we plot
the reward over entire duration of campaign for attendance management system. The plots show TUCBMAE algorithm achieves higher rewards than sliding window during stationary periods and can adapt to non stationary change faster than UCB algorithm. However, the algorithm unable to adapt to very short period of no-stationary changes as observed around day 250.
7.1 REWARD TYPES
Section titled “7.1 REWARD TYPES”We consider two kinds of reward signals for budget allocation. The first choice is maximizing clicks which has been popularly used in pay per click advertisements [17, 28]. However, in businesses advertisers often aim at maximizing the number of conversions for campaigns which drives profitability. We observe the number of conversion per day is a very sparse signal often having a low value for many days which renders this signal inefficient to be estimated
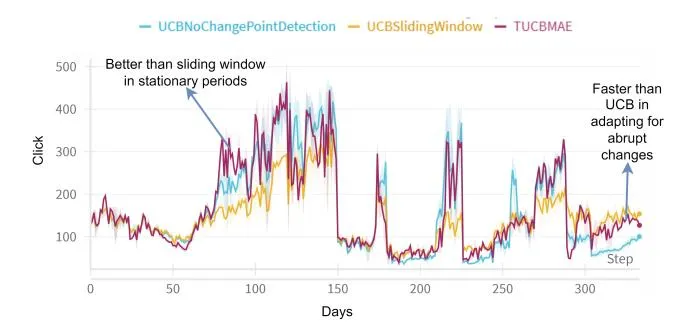
Figure 5: Reward comparison for around 300 days for attendance management campaign.
as a reward function and optimized directly. In order to optimize conversions we formulate defined as follows:
pseudoconversion calculates a weighted conversion rate based on the number of clicks for each day, scaled by the conversion rate over the past 7 days as depicted in Fig 6, capturing how effective ad campaigns are at driving conversion.
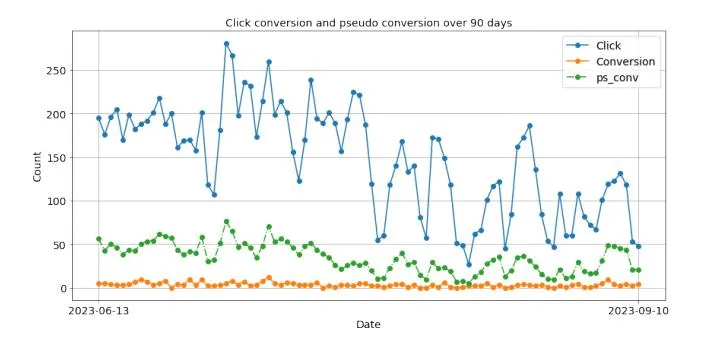
Figure 6: Click, conversions and pseudo conversion of one sub-campaign from AI Prediction Tool Campaign
We perform comparison with the logged budget allocation of the human operator from the dataset for both clicks and pseudo conversions. The results are reported in Fig 4. TUCBMAE shows a performance improvement of at least 19% compared to the human operator in terms of click and 5.8% for pseudo conversions.
7.2 Ablation Studies
Section titled “7.2 Ablation Studies”We perform ablation studies by studying the effect of different components of the proposed combinatorial bandit approach on AI Prediction Tool Campaigns with respect to clicks. TUCBMAENoSM represents a policy using Targeted UCB with CPC as efficiency but no saturating mean. TUCBMAENoCPC is a policy without efficiency incentive for exploration. NoTUCBMAEWithCPC is a policy
Table 2: Results for opensource Criterio Attribution dataset.
| Metric | TUCB | TSGP | UCBGP | |
|---|---|---|---|---|
| Click | 135784.005 ± 11836.84 | |||
| Regret | 27499.34 ± 413.94 | 46561.87 ± 11303.15 | 71035.26 ± 11836.84 | |
| CPC | 353.06 ± 15.35 | 397.71 ± 2.62 |
without targeted UCB for higher budget range but with CPC incentive for exploration along with normal UCB and saturating mean. The results are reported in Fig 7. It can be clearly interpreted from the ablation study the targeted UCB has the highest contribution to performance gain as NoTUCBMAEWithCPC has the lowest reward. Additionally we observe the efficiency incentive provides performance boost. Finally, the ablation study shows all three components contribute to the performance improvement of the algorithm.
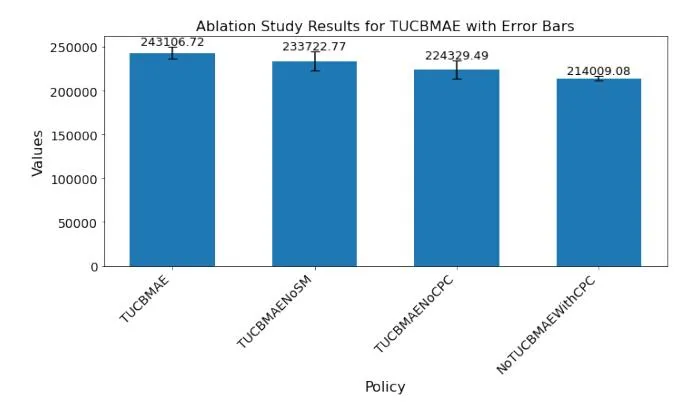
Figure 7: Ablation study for TUCBMAE algorithm
7.3 Experiments on Criterio Dataset
Section titled “7.3 Experiments on Criterio Dataset”In order to demonstrate the compatibility of simulation environment with open source data popularly utilized in budget allocation algorithms we use criterio attribution dataset [12] with our simulation environment. This dataset does not provide a campaign structure we combine four random campaigns with ids [22589171, 884761, 18975823 and 29427842] to form a campaign group as followed in [17]. Since the time horizon of this data is only 30 days and not expected to be non stationary we do not perform MAE change point detection. We compare the targeted UCB with saturating mean algorith with UCBGP (UCB with no change point detection) and TSGP (Thomson sampling with no change point detection). The results are reported in Table 2. The results demonstrate the the proposed strategy can lead to performance gain over UCB and TS exploration in stationary settings for standard dataset.
8 CONCLUSION AND FUTURE WORK
Section titled “8 CONCLUSION AND FUTURE WORK”The paper studies practical implication of deploying a combinatorial bandit algorithm for ad campaign budget management across multiple channels. We first construct a simulation environment capable of simulating real-logged data for long time horizon. We propose saturating mean and targeted UCB along with change
point detection in combinatorial bandit for faster adaptation in non stationary environments. Our preliminary findings investigate the effects of non-stationarity in long-running digital advertising campaigns and the potential for improved adaptability. In future, we plan to formalize various types of non-stationary changes, including recurrent seasonal patterns, and further refine both the simulation environment and adaptation strategies to handle these challenges more effectively.
ACKNOWLEDGMENTS
Section titled “ACKNOWLEDGMENTS”The authors thank Sony Biz Networks Corporation for providing data for the ad campaign from services NURO Biz and AKASHI.
REFERENCES
Section titled “REFERENCES”-
[1] [n.d.]. About average daily budgets - Google Ads Help — support.google.com. https://support.google.com/google-ads/answer/6385083?hl=en. [Accessed 11-09-2024].
-
[2] Vashist Avadhanula, Riccardo Colini Baldeschi, Stefano Leonardi, Karthik Abinav Sankararaman, and Okke Schrijvers. 2021. Stochastic bandits for multi-platform budget optimization in online advertising. In Proceedings of the Web Conference 2021. 2805–2817.
-
[3] Abraham Bagherjeiran, Nemanja Djuric, Kuang-Chih Lee, Linsey Pang, Vladan Radosavljevic, and Suju Rajan. 2024. AdKDD 2024. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (Barcelona, Spain) (KDD ‘24). Association for Computing Machinery, New York, NY, USA, 6706–6707. https://doi.org/10.1145/3637528.3671476
-
[4] Omar Besbes, Yonatan Gur, and Assaf Zeevi. 2014. Stochastic multi-armed-bandit problem with non-stationary rewards. Advances in neural information processing systems 27 (2014).
-
[5] Yang Cao, Zheng Wen, Branislav Kveton, and Yao Xie. 2019. Nearly optimal adaptive procedure with change detection for piecewise-stationary bandit. In The 22nd International Conference on Artificial Intelligence and Statistics. PMLR, 418–427
-
[6] Emanuele Cavenaghi, Gabriele Sottocornola, Fabio Stella, and Markus Zanker. 2021. Non stationary multi-armed bandit: Empirical evaluation of a new concept drift-aware algorithm. Entropy 23, 3 (2021), 380.
-
[7] Wei Chen, Yajun Wang, and Yang Yuan. 2013. Combinatorial Multi-Armed Bandit: General Framework and Applications. In Proceedings of the 30th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 28), Sanjoy Dasgupta and David McAllester (Eds.). PMLR, Atlanta, Georgia, USA, 151–159. https://proceedings.mlr.press/v28/chen13a.html
-
[8] Vincenzo D’Elia. 2019. On the causality of advertising. http://papers.adkdd. org/2019/invited-talks/slides-adkdd19-delia-causality.pdf. [Online; accessed September-2024].
-
[9] Qiyuan Deng, Kejia Hu, and Yun Fong Lim. 2023. Cross-Channel Marketing on E-commerce Marketplaces: Impact and Strategic Budget Allocation. Available at SSRN 4332631 (2023).
-
[10] Yuan Deng, Negin Golrezaei, Patrick Jaillet, Jason Cheuk Nam Liang, and Vahab Mirrokni. 2023. Multi-channel autobidding with budget and ROI constraints. In Proceedings of the 40th International Conference on Machine Learning (Honolulu, Hawaii, USA) (ICML’23). JMLR.org, Article 301, 28 pages.
-
[11] Eustache Diemert, Julien Meynet, Pierre Galland, and Damien Lefortier. 2017. Attribution modeling increases efficiency of bidding in display advertising. In Proceedings of the ADKDD’17. 1–6.
-
[12] Diemert Eustache, Meynet Julien, Pierre Galland, and Damien Lefortier. 2017. Attribution Modeling Increases Efficiency of Bidding in Display Advertising. In Proceedings of the AdKDD and TargetAd Workshop, KDD, Halifax, NS, Canada, August, 14, 2017. ACM, To appear.
-
[13] Paul W Farris, Dominique M Hanssens, James D Lenskold, and David J Reibstein. 2015. Marketing return on investment: Seeking clarity for concept and measurement. Applied Marketing Analytics 1, 3 (2015), 267–282.
-
[14] Marco Fiandri, Alberto Maria Metelli, and Francesco Trovò. 2024. Sliding-Window Thompson Sampling for Non-Stationary Settings. arXiv preprint arXiv:2409.05181 (2024).
-
[15] Aurélien Garivier and Eric Moulines. 2011. On upper-confidence bound policies for switching bandit problems. In International conference on algorithmic learning
-
theory. Springer, 174-188.
-
[16] Marco Gigli and Fabio Stella. 2024. Multi-armed bandits for performance marketing. International Journal of Data Science and Analytics (2024), 1–15.
-
[17] Marco Gigli and Fabio Stella. 2024. Multi-armed bandits for performance marketing. International Journal of Data Science and Analytics (2024), 1–15.
-
keting. International Journal of Data Science and Analytics (2024), 1–15. Benjamin Han and Carl Arndt. 2021. Budget allocation as a multi-agent system of contextual & continuous bandits. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining. 2937–2945.
-
[19] Benjamin Han and Jared Gabor. 2020. Contextual bandits for advertising budget allocation. Proceedings of the ADKDD 17 (2020).
-
[20] Benjamin Han and Jared Gabor. 2020. Contextual bandits for advertising budget allocation. Proceedings of the ADKDD 17 (2020).
-
[21] EM Italia, A Nuara, Francesco Trovò, Marcello Restelli, N Gatti, E Dellavalle, et al. 2017. Internet advertising for non-stationary environments. In Proceedings of the International Workshop on Agent-Mediated Electronic Commerce. 1–15.
-
[22] Hans Kellerer, Ulrich Pferschy, David Pisinger, Hans Kellerer, Ulrich Pferschy, and David Pisinger. 2004. The multiple-choice knapsack problem. Knapsack problems (2004), 317–347.
-
[23] Randall Lewis and Jeffrey Wong. 2022. Incrementality bidding and attribution. arXiv preprint arXiv:2208.12809 (2022).
-
[24] Fang Liu, Joohyun Lee, and Ness Shroff. 2018. A change-detection based framework for piecewise-stationary multi-armed bandit problem. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 32.
-
[25] Phuong Ha Nguyen, Djordje Gligorijevic, Arnab Borah, Gajanan Adalinge, and Abraham Bagherjeiran. 2023. Practical Budget Pacing Algorithms and Simulation Test Bed for eBay Marketplace Sponsored Search.. In AdKDD@ KDD.
-
[26] Phuong Ha Nguyen, Djordje Gligorijevic, Arnab Borah, Gajanan Adalinge, and Abraham Bagherjeiran. 2023. Practical Budget Pacing Algorithms and Simulation Test Bed for eBay Marketplace Sponsored Search.. In AdKDD@ KDD.
-
[27] Alessandro Nuara, Francesco Trovò, Nicola Gatti, and Marcello Restelli. 2018. A Combinatorial-Bandit Algorithm for the Online Joint Bid/Budget Optimization of Pay-per-Click Advertising Campaigns. In AAAI Conference on Artificial Intelligence. https://api.semanticscholar.org/CorpusID:19147413
-
[28] Alessandro Nuara, Francesco Trovò, Nicola Gatti, and Marcello Restelli. 2022. Online joint bid/daily budget optimization of internet advertising campaigns. Artificial Intelligence 305 (2022), 103663.
-
[29] PwC. 2021. IAB_PwC_Internet_Ad_Revenue_Report_2021. https://www.iab.com/wp-content/uploads/2022/04/IAB\_Internet\_Advertising\_Revenue\_Report\_Full\_Year\_2021.pdf. [Accessed 26-08-2024].
-
[30] PwC. 2024. IAB_PwC_Internet_Ad_Revenue_Report_2024. https://www.iab.com/wp-content/uploads/2024/04/IAB\_PwC\_Internet\_Ad\_Revenue\_Report\_2024.pdf. [Accessed 26-08-2024].
-
[31] Arvind Rangaswamy and Gerrit H Van Bruggen. 2005. Opportunities and challenges in multichannel marketing: An introduction to the special issue. Journal of interactive marketing 19, 2 (2005), 5–11.
-
[32] Gerlando Re, Fabio Chiusano, Francesco Trovò, Diego Carrera, Giacomo Boracchi, and Marcello Restelli. 2021. Exploiting history data for nonstationary multi-armed bandit. In Machine Learning and Knowledge Discovery in Databases. Research Track: European Conference, ECML PKDD 2021, Bilbao, Spain, September 13–17, 2021, Proceedings, Part I 21. Springer, 51–66.
-
[33] Gerlando Re, Fabio Chiusano, Francesco Trovò, Diego Carrera, Giacomo Boracchi, and Marcello Restelli. 2021. Exploiting History Data for Nonstationary Multiarmed Bandit. Springer-Verlag, Berlin, Heidelberg, 51–66. https://doi.org/10. 1007/978-3-030-86486-6_4
-
[34] Eric Schulz, Maarten Speekenbrink, and Andreas Krause. 2018. A tutorial on Gaussian process regression: Modelling, exploring, and exploiting functions. Journal of mathematical psychology 85 (2018), 1–16.
-
[35] Niranjan Srinivas, Andreas Krause, Sham Kakade, and Matthias Seeger. 2010. Gaussian process optimization in the bandit setting: no regret and experimental design. In Proceedings of the 27th International Conference on International Conference on Machine Learning (Haifa, Israel) (ICML’10). Omnipress, Madison, WI, USA, 1015–1022.
-
[36] Francesco Trovo, Stefano Paladino, Marcello Restelli, and Nicola Gatti. 2020. Sliding-window thompson sampling for non-stationary settings. Journal of Artificial Intelligence Research 68 (2020). 311–364.
-
[37] Xingfu wang, Pengcheng Li, and Ammar Hawbani. 2018. An Efficient Budget Allocation Algorithm for Multi-Channel Advertising. In 2018 24th International Conference on Pattern Recognition (ICPR). 886–891. https://doi.org/10.1109/ICPR. 2018.8545777
-
[38] Haifeng Zhang and Yevgeniy Vorobeychik. 2017. Multi-channel marketing with budget complementarities. In International Conference on Autonomous Agents and Multiagent Systems.
APPENDIX
Section titled “APPENDIX”8.1 Summary of Notations
Section titled “8.1 Summary of Notations”| Notation | Description |
|---|---|
| Exploration parameter for campaign at time . | |
| Regret after rounds for algorithm . | |
| Big-O notation disregarding logarithmic factors. | |
| Estimated mean of campaign at time for | |
| budget x. | |
| Estimated standard deviation of campaign j at | |
| time for budget . | |
| True reward function. | |
| Realization of the GP representing reward of cam- | |
| paign at budget . | |
| Information gain from exploring campaign j over | |
| T rounds. | |
| λ | Variance of measurement noise of the reward |
| functions . | |
| δ | Confidence parameter controlling probability |
| bounds. | |
| M | Number of possible combinations of budgets ex- |
| plored. | |
| Set of possible budgets or actions. | |
| T | Number of rounds or time steps. |
| N | Number of campaigns or arms. |
| Super-arm configuration at round t . | |
| Selected action or budget for campaign j . | |
| A stationary phase. | |
| Break-point of phase . | |
| Arm efficiency. |
Table 3: Table of Notations
8.2 Detailed Proof
Section titled “8.2 Detailed Proof”Lemma 8.1 (From [35]). Given the realization of a GP , the estimates of the mean and variance for the input x belonging to the input space X, for each the following condition holds:
for each .
PROOF. Let and , we have:
\begin{split} \mathbb{P}(r > c) &= \frac{1}{\sqrt{2\pi}} e^{-\frac{c^2}{2}} \int_c^{\infty} e^{-\frac{(r-c)^2}{2} - c(r-c)} \, dr \\ &\leq e^{-\frac{c^2}{2}} \mathbb{P}(r > 0) = \frac{1}{2} e^{-\frac{c^2}{2}}, \end{split}
since for . By the symmetry of the Gaussian distribution, we have:
Applying the above result to and concludes the proof.
PROPOSITION 8.2. Let us consider an ABA problem over T rounds where the function is the realization of a GP, using TUCB-MAE algorithm with the following upper bound on the reward function :
with probability at least , it holds:
where the notation disregards the logarithmic factors.
Proof: In ABA-UCB, we assume the number of clicks of a campaign is the realization of a GP over the budget space x. Using the selected input and the corresponding observations for each , the GP provides the estimates of the mean and variance for each x. The sampling phase is based on the upper bounds on the number of rewards formally:
u_{j,t-1}^{(n)}(x) := \hat{\mu}_{j,t-1}(x) + \sqrt{\beta_{j,t}} \hat{\sigma}_{j,t-1}(x), \tag{A.1}
where x is the cost,n denotes the round and j is the campaign. Applying Lemma 1 to Equation (A.1) for a generic arm a and we have:
In the execution of the ABA-UCB algorithm, after t-1 rounds, each arm can be chosen a number of times from 0 to t-1. Applying the union bound over the rounds , the campaigns and the available action in each campaign , and exploiting Lemma (1), we obtain:
\begin{split} \mathbb{P}\left[\bigcup_{t\in\{1,\dots,T\}}\bigcup_{j\in\{1,\dots,N\}}\bigcup_{a\in\mathcal{D}}\left(\left|\hat{n}_{j}(x)-\mu_{j,t-1}(x)\right|>\sqrt{\beta_{j,t}}\sigma_{j,t-1}(x)\right)\right]\\ \leq \sum_{t=1}^{T}\sum_{i=1}^{N}Me^{-\frac{\beta_{j,t}}{2}}. \end{split}
Where M represents the number of possible combinations of budget that the algorithm can explore. The larger the number of budget, the more difficult it becomes to explore the space effectively, hence the need for more exploration. For each time t, for each campaign j, and for each action , the probability of the event occurring is bounded by the size of the action set M times the exponential decay.
Thus, choosing , where we obtain:
\begin{split} &\sum_{t=1}^{T} \sum_{j=1}^{N} M e^{-\frac{\beta_{j,t}}{2}} = \sum_{t=1}^{T} \sum_{j=1}^{N} M (\frac{3\delta}{\pi^2 N M t^2})^{k_j} \leq \frac{\delta}{2N} \sum_{j=1}^{N} \left( \frac{6}{\pi^2} \sum_{t=1}^{\infty} \frac{1}{t^2} \right) \leq \frac{\delta}{2}. \\ &e^{alogb} = b^a \ and \ k_j \in (0,1]. \end{split}
So, the total probability of deviating significantly from the true values (across campaigns, time steps, and actions) is less than or equal to . This ensures high probability guarantee for the entire bound over all time steps, campaigns, and actions, ensuring the algorithm’s
decisions are made with a high level of confidence. Therefore, the event that at least one of the upper bounds over the actual reward does not hold has probability less than .
Assume to be in the event that all the previous bounds hold. The instantaneous pseudo-regret at round t satisfies the following inequality:
where
is the vector composed of all the upper bounds of the different actions (of dimension NM).
Let us recall that, given a generic superarm S, if all the elements of a vector are larger than the ones of , the following holds:
Let us focus on the term . The following inequality holds:
(A.3)
where is the super-arm providing the optimum expected reward when the expected rewards are . Thus, we have:
where
is the vector composed of the estimated average rewards for each arm .
\begin{split} r_{\bar{\mu}_t}(S_t) - r_{\mu_t}(S_t) &= \sum_{j=1}^N \left( u_{j,t-1}^{(n)}(a_j,t) - \hat{\mu}_{j,t-1}(a_j,t) \right) \\ &= \sum_{j=1}^N \left( \hat{\mu}_{j,t-1}(a_j,t) + \sqrt{\beta_{j,t}} \hat{\sigma}_{j,t-1}(a_j,t) - \hat{\mu}_{j,t-1}(a_j,t) \right) \\ &= \sum_{j=1}^N \sqrt{\beta_{j,t}} \hat{\sigma}_{j,t-1}(a_j,t) \\ &\leq \sum_{i=1}^N \sqrt{\beta_{j,t}} \max_{a \in \mathcal{D}} \hat{\sigma}_{j,t-1}(a) \end{split}
Let us focus on the term :
Given the UCB Gurantee.
Summing up the two terms we have:
We now need to upper bound . Using Lemma 5.3 in [35], under the Gaussian assumption we can express the information gain
provided by the observations corresponding to the sequence of actions as:
Since is non-decreasing in h, we can write:
Since Equation (A.4) holds for any , then it also holds for the action maximizing the variance in defined over . Thus, using the Cauchy-Schwarz inequality, we obtain:
\begin{split} \mathcal{R}_{T}^{2}(U) &\leq T \sum_{t=1}^{T} reg_{t}^{2} \\ &\leq T \left( 2 \sum_{j=1}^{N} \sqrt{\beta_{j,t}} \max_{a \in \mathcal{D}} \hat{\sigma}_{j,t-1}(a) \right)^{2} \\ &\leq 4T \left\{ \sum_{j=1}^{N} \sum_{t=1}^{T} \beta_{j,t} \left[ \max_{a \in \mathcal{D}} \frac{\log \left( 1 + \frac{\hat{\sigma}_{j,n-1}^{2}(a)}{\lambda} \right)}{\log \left( 1 + \frac{1}{\lambda} \right)} \right] \right\} \\ &\leq 4T \sum_{j=1}^{N} \sum_{t=1}^{T} \left[ \beta_{j,t} \max_{a \in \mathcal{D}} \frac{\log \left( 1 + \frac{\hat{\sigma}_{j,n-1}^{2}(a)}{\lambda} \right)}{\log \left( 1 + \frac{1}{\lambda} \right)} \right] \end{split}
As is between 0 and 1.
where, is variances of the measurement noise of the reward functions .
Table 5: Campaign specific hyperparameters
| Product Type | β | τ |
|---|---|---|
| Attendance Management System | 100 | 10 |
| Prediction Analysis Tool | 2 | 4 |
| Internet Service Provider | 100 | 4 |
| Product17276 | 2 | 10 |
| Product1598 | 50 | 10 |
Table 4: General Hyperparameter
| Parameter | Value |
|---|---|
| window length | 7 |
| 20 | |
| 1 | 1.0 |
| В | 500 |
Equivalently, with probability at least , it holds:
If we explore values of , by monotonicity, we have: .
This means that exploring in this region incurs unnecessary regret because we are not gaining new information about potentially better actions.
Information Gain : The information gain measures how much we learn from exploring the actions. Exploring in regions where leads to little or no information gain due to monotonicity, because it only confirms what is already known — that lower values of x will not perform better. Therefore, this exploration adds to regret without yielding useful information.
Reduced Exploration Space: By restricting exploration to values , the effective space of arms to explore is reduced. This reduces the total information gain , which in turn reduces the regret bound. Specifically, if we denote the restricted exploration space by , we have:
Thus, the regret bound becomes:
Since , this shows that the regret is already reduced by restricting exploration to values .
8.3 Hyper-parameters
Section titled “8.3 Hyper-parameters”The hyper-parameters used in our experiments are described in Table 4 and 5. We only tune two hyper-parameters per campaign group which is the exploration parameter and the change point detection threshold . The values are reported in Table 5. For criterio dataset since there is no change point detection we only tune . The other hyperparameters are reported in Table 4.