Bandits For Sponsored Search Auctions Under Unknown Valuation Model Case Study In E Commerce Advertising
Abstract. This paper presents a bidding system for sponsored search auctions under an unknown valuation model. This formulation assumes that the bidder’s value is unknown, evolving arbitrarily, and observed only upon winning an auction. Unlike previous studies, we do not impose any assumptions on the nature of feedback and consider the problem of bidding in sponsored search auctions in its full generality. Our system is based on a bandit framework that is resilient to the black-box auction structure and delayed and batched feedback. To validate our proposed solution, we conducted a case study at Zalando, a leading fashion ecommerce company. We outline the development process and describe the promising outcomes of our bandits-based approach to increase profitability in sponsored search auctions. We discuss in detail the technical challenges that were overcome during the implementation, shedding light on the mechanisms that led to increased profitability.
Keywords: Sponsored search auctions · Adversarial bandits · Unknown valuation model · Batched and delayed feedback.
1 Introduction
Section titled “1 Introduction”Search engine advertising is one of the central topics of the modern literature on e-commerce advertising. Typically, advertising opportunities are sold in search engines through sponsored search auctions (SSA), run separately for each search query and offering ad slots as the entity being sold. Advertisers participating in these auctions repeatedly bid for slots on a search engine, aiming to maximize their profitability from the ads they show.
SSAs present a unique interplay of challenges, including black-box auction mechanisms, batched and delayed feedback, click attribution, etc. These complexities are further compounded by the common challenge that advertisers often lack a clear assessment of the valuation for the slots being sold at the auctions [11]. Therefore, learning in SSA becomes exceptionally demanding, requiring solutions that can adeptly navigate through a spectrum of real-life challenges. However, prevailing solutions often resort to simplifications and restrictive assumptions, limiting their effectiveness in practical applications.
This work aims to address these challenges by proposing a comprehensive solution for bidding in SSAs within an industrial context. We consider the bidding problem in its full generality, i.e., we do not impose any assumptions on the nature of feedback or underlying auction mechanisms and consider the value of a good at sale unknown.
In contrast, a standard assumption in the literature on auction theory is that participants arriving in the market have a clear assessment of their valuation for the goods at sale (see, e.g., [13, 15, 16]). However, this assumption is severely violated in online advertising, where the high-frequency auction mechanism is subject to changing market conditions and user behavior. Additionally, numerous studies assume a structured underlying auction mechanism, with some positing a second-price auction lying at the heart of the allocation process (see, e.g., [7,8,12, 29,33]), while others suggest a first-price auction (see, e.g., [15,16,34]). In reality, the underlying auction mechanism often remains a black box, as exchanges do not disclose the type of auction mechanism being used. In fact, there has been a surge in the popularity of deep learning-based auction designs in recent years. These designs involve learning an approximation of an allocation function that satisfies specific properties [22, 35].
Further, a list of challenges faced by practitioners in present-day advertising scenarios arises from the interactive nature of SSA. While clicks can be observed shortly after an ad is displayed, it may take hours or even days for the corresponding sale to occur. This delay in feedback can make it challenging to optimize bids or other decisions in online advertising, as the true value of action may take time to be apparent [28]. Furthermore, since conversion rates are typically low in online advertisement, the signal provided to the learner is infrequent, and observational data might not capture behavioral patterns. This scarcity of information makes it difficult for bidders to make informed decisions, complicating the optimization process. Finally, a large volume of multiple-item auctions takes place per iteration, and bidders typically submit a batch of bids. Consequently, bidders have access only to information aggregated over a certain period, leading to batched feedback - where the rewards for a group of actions are revealed together and observed at the end of the batch. While, these challenges are well-studied in the online learning literature, to the best of our knowledge, we are not aware of any studies that address them from an auction perspective.
To address these challenges, we employ online learning in adversarial bandits [2]. The adversarial setting is advantageous for this problem as it does not rely on any structural assumptions regarding the reward components, which is perfectly combined with the black-box nature of SSAs. Next, we introduce the BatchEXP3 algorithm, an extension of the EXP3 algorithm, which is capable of batch update and prone to delayed feedback, and develop a simple yet effective and practical bid placement system.
To validate the effectiveness of the proposed approach, we deployed our bidding system and conducted a three-month live test. The evaluation of our system shows a notable increase in profit during the test duration, suggesting that our approach offers a practical solution to addressing common real-life challenges.
In summary, the paper makes the following contributions:
- We formulate a learning-to-bid problem under an unknown valuation model as a bandit learning task, illustrating how real-life challenges can be adeptly formalized (Section 3).
- We introduce the Batch EXP3 algorithm an extension of the EXP3 algorithm designed to handle batched feedback (Section 4).
- We develop an effective bid placement system capable of learning in the black-box auction and handling batch and delayed feedback (Section 5).
- We apply our methodology to a real-world SSA problem, showcasing empirical results that not only highlight the effectiveness of our system but also reveal valuable insights for bidding system designers (Section 6).
- We reflect on the practical difficulties we encountered and elaborate on gaps that prevent a seamless transition from theory to practice. (Section 7).
2 Related work
Section titled “2 Related work”Auctions The majority of auction theory research has focused on designing truthful auction mechanisms to maximize the seller’s revenue by optimizing a reserve price (a price below which no transaction occurs) [23, 27, 31]. A more traditional approach takes a game-theoretic view, where the seller has perfect or partial knowledge of bidders’ private valuations modeled as probability distributions [32]. This approach is limited as it relies on perfect knowledge of the bidders’ value distribution, which is unlikely to be known in practice [13].
The ubiquitous collection of data has presented new opportunities where previously unknown quantities, such as the bidders’ value distributions, can potentially be learned from past observations [29]. In recent years, data-driven efforts have emerged that aim at learning auction mechanisms to optimize the seller’s or bidder’s profit [1,6,8], or multiple performance metrics simultaneously, including social welfare and revenue [22, 35]. In particular, this line of research has triggered the development of various reinforcement learning (RL) and bandit approaches, which we describe below in more detail.
RL and bandits for bid optimization. The existing research to optimize bidding strategy falls into two main categories: methods based on the bandits framework and methods based on the full RL framework.
The origin of the full RL methods in application to auctions can be traced back to [7]. In this paper, the authors modeled a budget-constrained bidding problem as a finite Markov Decision Process (MDP). The authors utilize a modelbased RL setting for the optimal action selection, assuming the perfect knowledge of the MDP. This work led to various improvements, such as proposing model-free RL algorithms [33], where the learner cannot obtain perfect information, considering continuous action space using policy gradient methods [21], and modeling the mutual influence between bidders using multi-agent RL framework [17, 30]. We refer to [25] for a comprehensive survey of related works.
One practical downside of RL approaches is that they are known to be sample-inefficient. Moreover, their high complexity renders them challenging to deploy in real-life scenarios due to their limited debuggability. Conversely, bandit-based methods have demonstrated effectiveness in optimizing bidding strategies across various contexts. A substantial body of literature on optimal bidding strategies focuses on efficient budget optimization utilizing bandits and online optimization techniques [3, 4, 14]. Particularly, in [3], the focus is on the problem of online advertising without knowing the value of showing an ad to the users on the platform. However, it is noteworthy that the existing works heavily depend on the assumption of a known pricing mechanism and do not generalize to black-box auction mechanisms.
Numerous bandit-based methods have been proposed without budget constraints (see, e.g., [8,12,29] for the second-price auctions, [15,16,34] for the first-price auctions, and [11] for generalized auction mechanisms). Notably, due to the truthfulness of second-price auctions, methods developed for such a mechanism are based on optimism in the face of uncertainty principle [8, 12, 29], whereas first-price and generalized auction mechanisms leverage the adversarial nature of the problem 3 and use exponential weighting methods [11, 15, 16, 34].
One paper we found particularly relevant to our approach is [11]. In this paper, a general auction mechanism is considered, where the product valuation is unknown, evolving in an arbitrary manner and observed only if the bidder wins the auction. The authors decompose the reward of placing bid at iteration t as , where is the allocation function and is the revenue function. Consequently, they assume that while is subject to bandit feedback, is subject to online feedback, i.e., the learner gets to observe for each bid b and not only for the placed bid . Based on this, they develop an exponentially faster algorithm (in action space) than a generic bandit algorithm. As we will discuss in the next section, our setting is more complex, and a similar assumption does not apply to us.
3 Problem formulation
Section titled “3 Problem formulation”We focus on a single bidder in a large population of bidders. At the beginning of each round , the bidder has a value per unit of a good and, based on the past observations, submits a bid , where B is a finite set of bids (will be specified later). The outcome of the auction is as follows: if (click occurred), the bidder gets a good and pays ; if (no click occurred) the bidder does not get a good and pays nothing.
In reality, the sponsored search engine runs multiple auction rounds per iteration and reveals only aggregated information over a set of auctions. Formally, every iteration t, t = 1, …, T, where T is unknown and possibly infinite horizon,
<sup>3 First-price and generalized auctions are known to be untruthful, making the environment from the bidders’ perspective adversarial.
is associated with a set of reward contests . The bidder picks a bid , which is used at all reward contests. 4 At the end of iteration t, the bidder observes aggregated values of revenue , payment , and click-through-rate in the reward contest .
We denote , and define the instantaneous profit as follows:
and the bidder’s goal is to maximize the total profit .
Remark 1. is a random variable whose distribution is unknown to the learner. Moreover, different allocation and payment functions might be used for different auctions, i.e., and depend on as opposed to [11].
Next, bidders are rarely presented with a single item, and in real life, they strive to optimize bids for multiple items simultaneously. Let be a finite set of possible contexts. Every iteration t is associated with a unique set of contexts . Given , the bidder selects a vector of bids , one for each context, and observes vectors of and , where is vector functions from to . The instantaneous profit, in this case, is defined as the inner product between the vector of profits and vector of ones 1:
(1)
and the goal becomes to maximize the total profit for multiple items
\max_{\boldsymbol{b}_t \in B^{|C_t|}} \sum_{t=1}^{T} r(\boldsymbol{b}_t, \boldsymbol{v}_t; p_t). \tag{2}
Finally, the bidder does not observe the outcome of bid immediately after reward contest ends. Instead, the outcomes are batched in groups and observed after some delay. Formally, let be a grid of integers such that , where M is number of batches. It defines a partition where and for . The set is the k-th batch. Next, for each , let be the index of the current batch . Then, for each , the bidder observes the outcome of reward contest only after batch ends, for some positive integer .
Although the bidder’s goal (2) remains unchanged in the batched feedback setting, we emphasize that the complexity of the problem increases greatly, as the decision at round t can only depend on observations from batches ago. In fact, [26] shows that, in the worst case, the performance of the batch learning deteriorates linearly in the batch size for stochastic linear bandits.
The instantaneous profitability (1) and the goal (2) correspond to the most general setting of learning in sponsored search auction when the bidder aims
<sup>4 Note, changing a bid within the reward contest would not make any sense, as the bidder does not have access to granular information about every single auction.
to optimize bids for multiple items simultaneously under the batched feedback. This is the problem that we are addressing in this paper.
Assumption 1 (Independence of goods at sale). A set of possible contexts is represented by n unit vectors, for every t = 1, …, T.
Such context set definition corresponds to the situation when the bidder is presented with n items to bid for and treats these items independently. Alternatively, [16] and [34] propose to use valuation or its estimate as a context. However, we consider a stricter setting, assuming that is unknown for the bidder, nor data is available for its estimation.
Assumption 2 (Fixed batch size and delay). Grid divides the horizon T in equal partitions, i.e., , for some q > 0, and delay is fixed for all rounds. Moreover, values of q and are known to the bidder in advance.
Although restrictive from the problem formulation perspective, the batch size and delay are controlled by our bidding system and can be wholly justified in practice (see Section 5). Moreover, our algorithm, which we introduce in Section 4, is adaptable to unknown and random batch sizes and delays.
3.1 Learning in sponsored search auctions
Section titled “3.1 Learning in sponsored search auctions”Due to the unique characteristics of the problem described above, we take an online learning perspective and formalize the goal in Eq. (2) employing the adversarial bandits setting. Specifically, we assume that the bidder (learner) is presented with a discrete set of bids (actions) B. At each auction (round) t, the learner picks an action and the adversary constructs reward by secretly choosing reward components , payment functions , and allocation functions , which is further observed by the learner. 5
The advantage of the adversarial setting is that it avoids imposing any assumptions on the reward components (except that ), which is perfectly combined with the black-box nature of sponsored search auctions. Moreover, as we mentioned in Section 2, the adversarial setting allows accounting for the untruthfulness of the underlying auction mechanism.
The goal of the learner, in this case, becomes minimizing regret, the difference between the learner’s total reward and reward obtained by any fixed vector of bids in hindsight, which is equivalent to maximizing the total profit in Eq. (2):
4 BATCHEXP3: Algorithm for learning in SSA
Section titled “4 BATCHEXP3: Algorithm for learning in SSA”We introduce an adaptation of the EXP3 algorithm to the batch setting, which we call Batch EXP3. Batch EXP3 enables strong theoretical guarantees by building on top of the basic algorithm and extensions to more complex settings with
<sup>5 In the subsequent sections, we will use pairs bidder-learner, bid-action, and outcomereward interchangeably, depending on the context.
batched and delayed feedback. Specifically, Batch EXP3 maintains n instances of the learner, each instance for a separate item, and performs -steps delayed update at the end of each batch. Importantly, the update mechanism of Batch EXP3 preserves the importance-weighted unbiased estimator of rewards, thus, making our adaptation resilient to batch and delayed feedback. Algorithm 1 formalizes the description above.
Theoretical guarantees of the Batch EXP3 follow from a classical analysis of the EXP3 algorithm (see, e.g., [2]). For completeness and theoretical rigor, we formulate a separate statement on Batch EXP3 theoretical performance.
Theorem. The regret of BatchEXP3 Algorithm 1 BATCHEXP3 algorithmalgorithm with learning rate \sqrt{\frac{\log |B|}{T|B|}} is: \mathcal{O}\left(n\sqrt{qT|B|\log|B|}+n\Delta\right). Require: bid set B, learning rate \eta, num- ber of items n, grid \mathcal{T}, delay \Delta 1: Set X_{0,i}^j = 0 for all i \in [B] and j \in [n] 2: Set t \leftarrow 1Proof. We start analysis with n = 1: 3: for t = 1, 2, ... do (Policy update)R(T,1) = \sup_{b \in B} \mathbb{E} \left[ \sum_{t=1}^{T} \left( r_t(b) - r_t(b_t) \right) \right] \quad \begin{array}{c} \text{5: Compute} \\ \pi_t = (\pi_t^j)_{j=1}^n \text{:} \end{array} Compute sampling distribution \leq \sup_{b \in B} \mathbb{E} \left[ \sum_{t=1}^{M} \sum_{t=0}^{M} \left( r_t(b) - r_t(b_t) \right) \right] + \Delta \pi_t^j(b_i) = \frac{\exp(\eta X_{t-1,i}^j)}{\sum_{l \in [R]} \exp(\eta X_{t-1,l}^j)} (Bid generation) 6:7:8: \stackrel{(a)}{\leq} q \sup_{b \in B} \mathbb{E} \left[ \sum_{k=1}^{M} \left( r_t(b) - r(b_t) \right) \right] + \Delta Sample \boldsymbol{b}_t \sim \pi_t(\cdot) X_{t,i}^j \leftarrow X_{t-1,i}^j if t \in \mathcal{T} and J(t) > \Delta then \overset{(b)}{\leq} 2q\sqrt{M|B|\log|B|} + \Delta for s \in S_{J(t)-\Delta} do = 2\sqrt{qT|B|\log|B|} + \Delta. 11: Observe \boldsymbol{v}_s, p_s(\boldsymbol{b}_s) Calculate r(\boldsymbol{b}_s) Calculate X_{t,i}^j:where (a) is because of Assumption 2,(b) follows from standard analysis of X_{t,i}^j = X_{t,i}^j {+} 1 {-} \frac{\mathbb{I}\{b_s^j = b_i\}(1 - r^j(\pmb{b}_s))}{\pi_t^j(b_i)}EXP3, and r_t(\cdot) = r(\cdot, v_t; p_t). Then,summing R(T,1) over n items gives\mathcal{O}\left(n\sqrt{qT|B|\log|B|}+n\Delta\right). □ 14: t \leftarrow t + 15 Deployment
Section titled “5 Deployment”While our methodology accounts for the black box auction mechanism, unknown valuation of the goods at the sale, and batch update, it takes system support to fully address click attribution and the data collection issues caused by delayed feedback. For example, Algorithm 1 simply assumes data is correctly provided as input, but this is nontrivial in practice. To provide a systematic solution, we fill these gaps on the deployment side. Subsequently, we describe the live test design for our bidding system.
5.1 Bidding system architecture
Section titled “5.1 Bidding system architecture”Clicks attribution It is rarely the case when a single click leads to a desired outcome. Usually, a customer journey starts with a single click, but it is a chain of clicks that results in a conversion event. Identifying click chains and attributing credit to a single click in each click chain is a complex independent task that requires great engineering efforts. At Zalando, the performance measurement pipeline takes up these challenges and measures the performance of online marketing at scale. In short, the pipeline sources all marketing clicks, sales, as well as more complex conversion events such as customer acquisitions, and creates the customers’ journeys across all their devices, from first ad interaction to conversion. Then, it determines how much incremental value was created by every ad click based on a large number of parallel randomized experiments. We refer the interested reader to [10] for more details.
Bidding system Our bidding system is designed to match the modularity of the bandit methodology in an efficient way, including the bid generation and policy update components and the performance measurement pipeline. The bidding system contains two streams [19]: the first stream is responsible for bid placement in the ad exchange; the second stream unifies the performance measurement pipeline and the policy update component.
Ideally, both streams are to be synchronized and run as frequently as possible, one right after the other. However, the performance measurement pipeline is subject to daily exe-
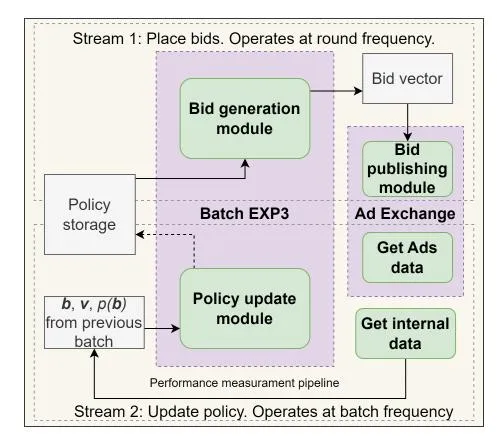 Fig. 1: Bidding system architecture
Fig. 1: Bidding system architecture
cution due to its compoundness and complexity, making any attempt to increase the frequency of the second stream meaningless. Keeping the same frequency for the first stream would admit placing one bid a day, which slows down the learning process considerably.
To account for this limitation, we desynchronize two streams and execute the first stream with a higher frequency, updating bids every 3 hours. Such improvement allowed us to speed up the learning process substantially. Therefore, the first stream runs every 3 hours and samples bids from the latest policy (3-hour time period corresponds to round t), while the second stream is subject to daily execution and performs an update based on batched feedback (scheduled by grid T ). 6 The architecture is illustrated in Figure 1.
6 The first stream runs at 12am, 3am, 6am, etc. The second stream runs at 12am.
5.2 Live test design and unfolding
Section titled “5.2 Live test design and unfolding”Test scope A subset of 180 (n = 180) clothing products was selected to be steered by the bandits algorithm. Because of the data sparsity, we chose to focus for this test on products for which the traffic was deemed high enough. The selection criterion was that they should meet a threshold of ten average daily clicks over a period of six months. The products selected for the test were randomly sampled amongst those satisfying this traffic threshold.
Profit metric In Section 3, we defined the reward as the aggregated difference between valuation vt and costs pt. While costs pt cause no problems and correspond to the expenditure during the round t (which is (almost) immediately available to the bidder), the valuation vt is abstract and requires special attention.
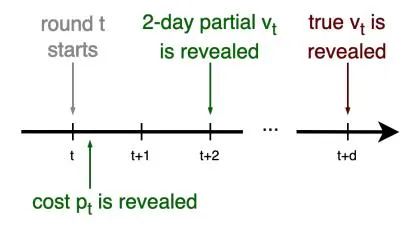
We consider valuation vt unknown to the bidder before auction t starts. In fact, it is difficult to evaluate vt even when auction
Fig. 2: A timeline of a single round.
t is over. Typically, the ground truth of valuation vt is assumed to be the revenue auction t has generated over d days, where d might correspond to several months due to return and cancellation policies (see Fig. 2 for illustration). Therefore, learning a bidding system when d is too big is impractical.
Although a vast literature on bandits with delayed feedback provides solutions with delay-corrected estimations, these solutions are not infallible and cannot completely eliminate delay. Therefore, two practical ways of dealing with delays are shortening the feedback loop by decreasing d or developing a delayfree method by substituting vt with some approximation. Due to the lack of historical data, we have taken a more pragmatic approach and shortened the delay to 2 days. As a result, we focus on maximizing the 2 days partial profit, i.e., profit attributed within the 2-day conversion window after the bid placement.
Profit metric normalization We apply two normalization steps to the 2 days partial profit. The first normalization step is a naive yet pragmatic way of incorporating side information into the modeling, and it eliminates the difference between time periods. Since users’ activity is different during the nighttime and daytime, rewards that we observe from 3am - 6am are incomparable to rewards that we observe from 3pm - 6pm. We reduce rewards to a common medium of expression by normalization:
where t − qSJ(t) is the time period number within the batch SJ(t) , and αl is the ratio of average traffic during time period l to the average traffic of the most active time period, l = 1, … , q.
Next, the bandit formulation requires rewards to be in the [0, 1] range, which is far from the truth in a real-life application. In order to account for that, we apply minimax normalization to rewards by
where rmin and rmax are the 5-th and 95-th quantities of the historical 2 days partial profit. The coefficients αl were calculated on the market level and remain constant for all products i = 1, … , n; whereas the coefficients rmin and rmax are product-dependent and were calculated individually for each product based on the limited historical data available.
Bid space The bandit formulation described in Section 3.1 supports a discrete and finite set of bids. The conducted analysis of historical data demonstrated that bids higher than 40 cents are unprofitable, which narrows the potential bid space values to range from 1 cent to 40 cents. To trade off the total number of bids and coverage of the bid space, we decided to include more options for lower bids (with step 2 cents) and fewer options for higher bids (with steps 3-5 cents). The final bid space B consists of 14 possible bids and is
Test reset We started the experiment with a generic value of the learning rate η = 1. After we rolled out the solution, we spotted unstable learning behavior in the bidding system. Two weeks later, we decided to reset the test with the learning rate η = 0.1, which corresponds to less aggressive exploitation by the learner. While this adjustment did not resolve the issue completely, it mitigated the level of instability and facilitated the learning process. We will detail this phenomenon in the next section.
6 Experimental results and discussion
Section titled “6 Experimental results and discussion”The test took place from December 16th, 2022 (date of deployment) to March 25th, 2023, in a large European country. Figure (3a) illustrates the aggregated dynamics of partial profit (top), revenue (middle), and costs (bottom) for a subset of 180 products. To protect business-sensitive information, we have concealed the y-axis and only report the relative behavior. As we can see, beginning in January, the system displays a robust positive trend in profit. Notably, there are two peaks in costs that conclude in mid-January, corresponding to exploration periods within our system. Following January 25, the revenue maintains relative stability, while costs continue to decrease, resulting in an upswing in profitability.
These observations suggest that the increased profitability can be attributed to two mechanisms. Firstly, there is a significant reduction in costs during the initial part of January (until January 25) and the ensuing decline in revenue, which marks the conclusion of the (aggressive) exploration phase. The second
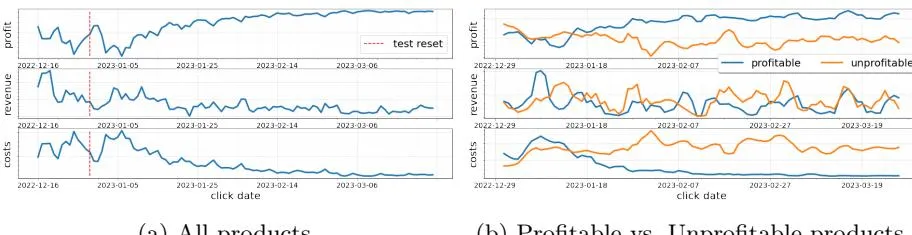
- (a) All products.
- (b) Profitable vs. Unprofitable products.
Fig. 3: Dynamics of the profit (top), revenue (middle), and costs (bottom).
mechanism involves a further reduction in costs while sustaining a relatively stable revenue, which suggests bids steering toward more profitable values.
To better understand when the increased profitability is due to selecting bids to increase revenue and when it is the case due to decreased costs, we provide a closer look at business metric behavior on a group level.
Group level analysis 6.1
Section titled “Group level analysis 6.1”For identifying product groups, we focus on profit behavior during which the revenue is relatively stable between February 1 and March 25. Most of the products (100 products) align with the general trend illustrated in Figure 3a, placing them into either “profitable” or “emerging” groups. A subset of 67 products are categorized as “low-traffic” due to their minimal associated activity. Finally, there are 13 products that exhibit a counterintuitive behavior, characterized by decreasing profits over time. Table 1 summarizes statistics on the group level.
It is essential to address the characteristics of the unprofitable group. Among these products, 7 exhibited an excessively large range of and coefficients, resulting in reduced system sensitivity to environmental signals. Conversely, for 6 products, and coefficients were too
Table 1: Percentage of clicks, costs, and gain partitioned by product groups
| Product group | # | products | % clicks | % costs | % revenue | average bid value |
|---|---|---|---|---|---|---|
| profitable | 14 | (8%) | 4.0% | 2.5% | 14.7% | 5.8¢ |
| emerging | 86 | (48%) | 73.6% | 69.8% | 62.4% | 8.3¢ |
| low-traffic | 67 | (37%) | 4.1% | 3.2% | 3.9% | 6.1¢ |
| unprofitable | 13 | (7%) | 18.4% | 24.6% | 19.1% | 17.9¢ |
narrow, causing the system to be overly sensitive to environmental signals. This disparity in coefficient ranges with respect to each product led to a discrepancy between the original signals from the environment and the rewards observed by the agent. Consequently, this misalignment resulted in confounding updates and an inaccurate valuation of bid values.
Profitable vs Unprofitable product groups Although the unprofitable group primarily results from technical issues within our system, it offers valuable insights when compared to the profitable group. Figure (3b) presents the profit, revenue, and cost dynamics for profitable and unprofitable product groups. Notably, the
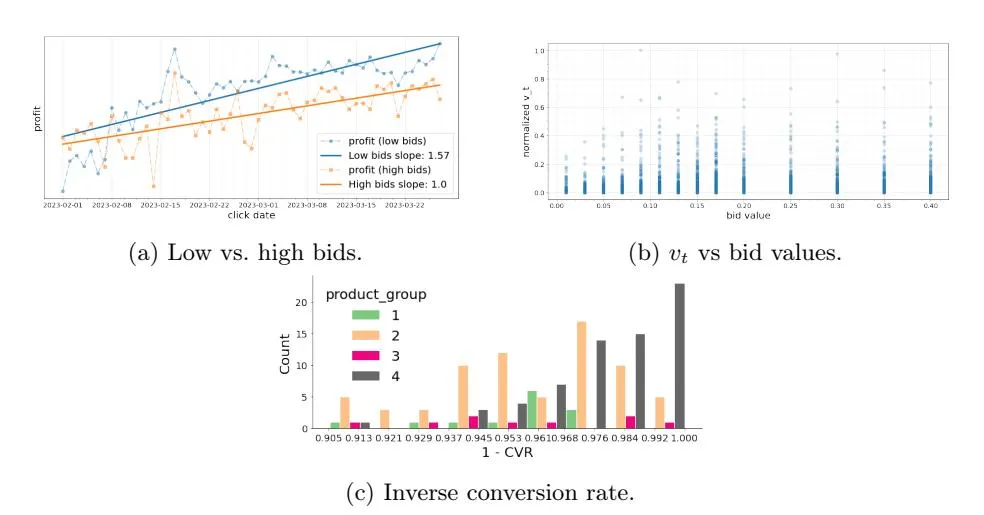
Fig. 4: (4a) Profit dynamics for products with higher (than 10 cents) and lower (than 10 cents) bid values, aggregated over highly profitable and profitable product groups. To preserve business-sensitive information, regression slopes represent the normalized linear regression fit. (4b) Distribution of normalized vt across the bid values.. (4c) Distribution of inverse conversion rate categorized by product group: 1 – profitable, 2 – emerging, 3 – unprofitable, 4 – low-traffic.
profitable group shows a consistent increase in profit, accompanied by a continual decrease in costs. In contrast, the unprofitable group exhibits a stable or even declining trend in profit, with costs remaining relatively stable.
This evidence suggests that the system optimized bids towards higher profitability due to decreased costs rather than increased revenue. In fact, it was spending almost 10 times less on profitable products than on unprofitable products to accumulate a comparable amount of revenue (14.7% vs 19.1%). Nevertheless, it is important to emphasize that, due to the auction nature of the problem, revenue is inherently monotonic to costs, and we cannot expect an increase in revenue with decreasing costs. At the same time, we can see that keeping costs unchanged did not result in a positive outcome for the unprofitable group.
Takeaway 1 The increasing profitability of our system primarily stems from cost reduction rather than revenue growth.
Low vs high bid values To better understand if our system’s reduction in costs was a rational reaction, we provide further insights on revenue growth for different bid values, aiming to compare products that converged to lower bid values and those that converged to higher bid values. We focus on profitable and emerging product groups (100 products) and disregard unprofitable (as those are deemed erroneous) and low-traffic (due to unperceptive behavior) groups.
Figure 4a illustrates the profit dynamics for products with lower bid values (lower than 10 cents) and products with higher bid values (higher than 10 cents). The lower bid values group encounters 75 products, and the higher bid values group encounters 25 products. We can see an upward trend in profit dynamics for both groups, consistent with the observation from Figure 3a. Notably, the lower bid value group grows 1.5 times faster than the higher bid value group, as can be seen from regression slopes. Thus, we can conjecture that the system steers bids towards more optimal values by decreasing the costs.
Takeaway 2 The decrease in costs is a rational behavior of our system.
6.2 Risk of decreasing costs
Section titled “6.2 Risk of decreasing costs”While we have seen that reduced costs is a justified behavior, taking a closer look at the low-traffic product group in Table 1 shows the opposite side of low costs. Specifically, we can see that spending a similar amount of money for a profitable group barely generates any revenue for the low-traffic group. In this part, we discuss the risks associated with the decreasing costs of our system.
Figure 4b demonstrates the distribution of normalized vt across bid values. Specifically, while we observe a slight positive dependence on bid value, values of vt mostly concentrate around 0 with rare positive signals for all bids. In situations when conversions are rare events, costs become the dominating term in the update rule (3), and bids with higher costs are depreciated. This incentivizes the system to spend less rather than earn more, making exploration of higher bid values improbable. As a result, after a certain amount of exploration, the system has “killed” 1/3 of products, which could have shrunk marketing opportunities.7
Somewhat surprisingly, this observation goes against one line of research that exploits an assumption of action space structure in the auction problem. This assumption is referred to as the censored feedback structure and says “Once we know the payoff under a certain bid, then irrespective of whether this bid wins or not, we know the payoff of any larger bid.” [15].
Takeaway 3 Sparse feedback might create asymmetry in the exploration process and make it more intricate to explore bids equally.
7 From practice back to theory: Additional insights
Section titled “7 From practice back to theory: Additional insights”Our work presents an adaptation of (theoretically) well-studied results to the industry application. While doing so, we have encountered certain problem-specific difficulties (such as decreasing costs and asymmetric exploration) that are usually overlooked in common theoretical formulations. We believe it is important to understand the roots of these difficulties in order to (1) mitigate them as much as possible with the current theoretical advancements and (2) identify gaps that prevent a seamless transition from theory to practice.
7 We emphasize that the loss-based update rule (3) is an inseparable part of the auction problem, and defining a reward-based estimator (instead of loss-based), first, might not make any sense for the auction problem (as trivially bidding the highest value would correspond to the highest revenue), and, second, would lead to similar issues.
There are three common assumptions in the bandit literature: (i) bounded rewards, often with support in [0, 1]; (ii) a “nice” shape of reward distribution, e.g., sub-Gaussian or Bernoulli; (iii) specific hyperparameters values, optimized in a way to achieve the best theoretical performance.
While these assumptions are not secret, theoretical papers usually focus on “nicer” settings and do not explicitly describe the consequences of their violation. However, none of these assumptions are met in the real-world auction problem, and we have encountered difficulties with all of them. Below, we make some observations about what did not work in practice and share some of our learnings.
Bounded rewards One limitation of many bandit algorithms is that they are typically analyzed assuming rewards fall within the [0, 1] range. Our approach employed a direct and practical method to scale the rewards (as outlined in 5.2). However, due to the sparsity of rewards and limited data, we encountered challenges in determining the correct rmin and rmax coefficients for some products. Consequently, this resulted in 7% of products being unprofitable in our experiment due to the disparity of rmin, rmax coefficients ranges.
Such practical matters are rarely the main focus of theoretical studies [9], and no definitive solutions are widely acknowledged. As a practical approach, we recommend adaptive computation of rmin and rmax for more accurate scaling.
Reward distribution Beyond reward scaling, theoretical performance guarantees usually require the reward to be “nicely” distributed. However, this is far from the reality we face in marketing applications. As we can see from Figure (4c), which reports the inverse conversion rate (1 − CV R) categorized by groups, the extreme values mostly correspond to low-traffic or unprofitable products, which suggests that striking the right balance between exploration and exploitation becomes even more acute when the inverse conversion rate tends to 1.
In sparse feedback, the EXP3-based update rule (3) risks assigning very small probabilities to bids with high losses. This is the main reason of decreasing costs, which led to the formation of the low-traffic product group. One way to mitigate this issue is the Exp3-IX-based update rule [18,24]. However, this would lead to tuning one additional parameter, which, as we discuss later, is highly non-trivial.
Hyperparameters The EXP3 family of algorithms requires knowledge of horizon T to get the optimal learning rate value (which is η = p log(k)/T k for classical EXP3 [20]). In cases when T is unknown, theoretical approaches propose either using a doubling trick [5] or decreasing the learning rate. However, the doubling trick is primarily a technical component designed to overcome specific constraints in proofs rather than serving as a practical tool. Decreasing the learning rate, on the other hand, is a more elegant solution [36], but choosing the right schedule for this parameter is not a straightforward task, especially with the sparse reward.
A slight misspecification of the learning rate can disrupt the entire learning process. At the beginning of the live test, the learning rate was inaccurately set at a generic value of 1, overlooking the sparsity of rewards. This caused heightened sensitivity in the learning system, where omitting to place a bid for 1-2 days resulted in a massive degeneration of policies around this bid value (with probabilities of other bids being compressed towards zero). Consequently, we reset the test and adjusted the learning rate to 0.1. To further address this issue, we would use the decreasing learning rate ηt = 1/ √ t suggested by [36], but we emphasize that it has not been studied from a practical standpoint.
8 Conclusion
Section titled “8 Conclusion”In this paper, we introduced a systematic solution to learning optimal bidding strategies in black-box sponsored search auctions. Doing so, we have presented how many real-life challenges can be addressed by a synthesis of the bandit framework and our bidding architecture. Live experiment results show the effectiveness of our system in increasing the partial profit, highlighting that the bandit framework is a promising approach to tackle the complex auction problem. Further, our insights highlight the practical difficulties that lurk around this problem, providing practical guidance for bidding system designers.
Naturally, the simplicity of our system has its limitations. We acknowledge that in its current form, our system has no leverage to hinder the diminishing cost effect that primarily arises due to the long-standing problem of sparse reward signals. Exploring this direction further is a promising avenue for future work.
Acknowledgments
Section titled “Acknowledgments”We wish to thank Joshua Hendinata and Aleksandr Borisov for their engineering support. Furthermore, we would like to thank Amin Jamalzadeh, head of the Traffic Platform Applied Science and Analytics at Zalando, for guidance, support with administrative processes related to the project, and the review of the final draft. Danil Provodin would like to thank Maurits Kaptein and Mykola Pechenizkiy, whose thoughts influenced his ideas.
References
Section titled “References”-
1. Amin, K., Rostamizadeh, A., Syed, U.: Repeated contextual auctions with strategic buyers. In: Advances in Neural Information Processing Systems (2014)
-
2. Auer, P., Cesa-Bianchi, N., Freund, Y., Schapire, R.E.: The nonstochastic multiarmed bandit problem. SIAM Journal on Computing (2002)
-
3. Avadhanula, V., Colini Baldeschi, R., Leonardi, S., Sankararaman, K.A., Schrijvers, O.: Stochastic bandits for multi-platform budget optimization in online advertising. In: Proceedings of the Web Conference 2021. WWW ‘21 (2021)
-
4. Balseiro, S.R., Lu, H., Mirrokni, V., Sivan, B.: Analysis of dual-based pid controllers through convolutional mirror descent (2023)
-
5. Besson, L., Kaufmann, E.: What doubling tricks can and can’t do for multi-armed bandits (2018)
-
6. Blum, A., Mansour, Y., Morgenstern, J.: Learning valuation distributions from partial observations. AAAI’15 (2015)
-
7. Cai, H., Ren, K., Zhang, W., Malialis, K., Wang, J., Yu, Y., Guo, D.: Real-time bidding by reinforcement learning in display advertising. WSDM ‘17 (2017)
-
8. Cesa-Bianchi, N., Gentile, C., Mansour, Y.: Regret minimization for reserve prices in second-price auctions. IEEE Transactions on Information Theory (2015)
-
9. Cowan, W., Honda, J., Katehakis, M.N.: Normal bandits of unknown means and variances. J. Mach. Learn. Res. (2017)
-
10. Deschamps, M., Quevrin, A., Haase, S.: On the effectiveness of online marketing (2019)
-
11. Feng, Z., Podimata, C., Syrgkanis, V.: Learning to bid without knowing your value. Proceedings of the 2018 ACM Conference on Economics and Computation (2018)
-
12. Flajolet, A., Jaillet, P.: Real-time bidding with side information. In: Advances in Neural Information Processing Systems (2017)
-
13. Fu, H., Hartline, J., Hoy, D.: Prior-independent auctions for risk-averse agents. EC ‘13 (2018)
-
14. Gao, Y., Yang, K., Chen, Y., Liu, M., Karoui, N.E.: Bidding agent design in the linkedin ad marketplace (2022)
-
15. Han, Y., Zhou, Z., Flores, A., Ordentlich, E., Weissman, T.: Learning to bid optimally and efficiently in adversarial first-price auctions (2020)
-
16. Han, Y., Zhou, Z., Weissman, T.: Optimal no-regret learning in repeated first-price auctions (2020)
-
17. Jin, J., Song, C., Li, H., Gai, K., Wang, J., Zhang, W.: Real-time bidding with multi-agent reinforcement learning in display advertising. CIKM ‘18 (2018)
-
18. Kocák, T., Neu, G., Valko, M., Munos, R.: Efficient learning by implicit exploration in bandit problems with side observations. NeurIPS’14 (2014)
-
19. Kruijswijk, J., van Emden, R., Parvinen, P., Kaptein, M.: Streamingbandit: Experimenting with bandit policies. Journal of Statistical Software (2020)
-
20. Lattimore, T., Szepesvári, C.: Bandit Algorithms (2020)
-
21. Liu, M., Jiaxing, L., Hu, Z., Liu, J., Nie, X.: A dynamic bidding strategy based on model-free reinforcement learning in display advertising. IEEE Access (2020)
-
22. Liu, X., Yu, C., Zhang, Z., Zheng, Z., Rong, Y., Lv, H., Huo, D., Wang, Y., Chen, D., Xu, J., Wu, F., Chen, G., Zhu, X.: Neural auction: End-to-end learning of auction mechanisms for e-commerce advertising. KDD ‘21 (2021)
-
23. Myerson, R.B.: Optimal auction design. Mathematics of Operations Research (1981)
-
24. Neu, G.: Explore no more: Improved high-probability regret bounds for nonstochastic bandits. Advances in Neural Information Processing Systems 28 (2015)
-
25. Ou, W., Chen, B., Dai, X., Zhang, W., Liu, W., Tang, R., Yu, Y.: A survey on bid optimization in real-time bidding display advertising. ACM Trans. Knowl. Discov. Data (2023)
-
26. Provodin, D., Gajane, P., Pechenizkiy, M., Kaptein, M.: The impact of batch learning in stochastic linear bandits. ICDM ‘22’ (2022)
-
27. Riley, J.G., Samuelson, W.F.: Optimal auctions. The American Economic Review (1981)
-
28. Vernade, C., Cappé, O., Perchet, V.: Stochastic bandit models for delayed conversions. UAI’17 (2017)
-
29. Weed, J., Perchet, V., Rigollet, P.: Online learning in repeated auctions. In: 29th Annual Conference on Learning Theory (2016)
-
30. Wen, C., Xu, M., Zhang, Z., Zheng, Z., Wang, Y., Liu, X., Rong, Y., Xie, D., Tan, X., Yu, C., Xu, J., Wu, F., Chen, G., Zhu, X., Zheng, B.: A cooperative-competitive multi-agent framework for auto-bidding in online advertising. WSDM ‘22 (2022)
-
31. Wilson, R.B.: Competitive bidding with disparate information. Management Science (1969)
-
32. Wilson, R.B.: Game-theoretic analysis of trading processes. (1985)
-
33. Wu, D., Chen, X., Yang, X., Wang, H., Tan, Q., Zhang, X., Xu, J., Gai, K.: Budget constrained bidding by model-free reinforcement learning in display advertising. CIKM ‘18 (2018)
-
34. Zhang, W., Han, Y., Zhou, Z., Flores, A., Weissman, T.: Leveraging the hints: Adaptive bidding in repeated first-price auctions (2022)
-
35. Zhang, Z., Liu, X., Zheng, Z., Zhang, C., Xu, M., Pan, J., Yu, C., Wu, F., Xu, J., Gai, K.: Optimizing multiple performance metrics with deep gsp auctions for e-commerce advertising. WSDM ‘21 (2021)
-
36. Zimmert, J., Seldin, Y.: Tsallis-inf: An optimal algorithm for stochastic and adversarial bandits (2022)