Broadgen A Framework For Generating Effective And Efficient Advertiser Broad Match Keyphrase Recommendations
Abstract—In the domain of sponsored search advertising, the focus of Keyphrase recommendation has largely been on exact match types, which pose issues such as high management expenses, limited targeting scope, and evolving search query patterns. Alternatives like Broad match types can alleviate certain drawbacks of exact matches but present challenges like poor targeting accuracy and minimal supervisory signals owing to limited advertiser usage. This research defines the criteria for an ideal broad match, emphasizing on both efficiency and effectiveness, ensuring that a significant portion of matched queries are relevant. We propose BroadGen, an innovative framework that recommends efficient and effective broad match keyphrases by utilizing historical search query data. Additionally, we demonstrate that BroadGen, through token correspondence modeling, maintains better query stability over time. BroadGen’s capabilities allow it to serve daily, millions of sellers at eBay with over 2.5 billion items.
Index Terms—Information Retrieval, Sponsored search advertising, Keyword Recommendation
I. INTRODUCTION
Section titled “I. INTRODUCTION”Advertisers or sellers on e-commerce platforms are recommended keyphrases by the platform to increase their item visibility depending on buyer searches as shown in Figure 1a. The sellers bid on relevant recommended keyphrases as well as their own custom keyphrases to increase their sales (Figure 1b). Keyphrase recommendation is the subject of a lot of research and well studied in several works [1], [2], [3], [4], [5], [6], [7], due to their challenging research and industrial importance. We term the recommendation to the seller as Keyphrase and the buyer search text as Query. Additionally, the platform matches the (recommended) keyphrases bid by the sellers to the buyer search queries [8].
Each keyphrase is also tagged with a Match Type, which is used during the matching process; for this work we define them as:
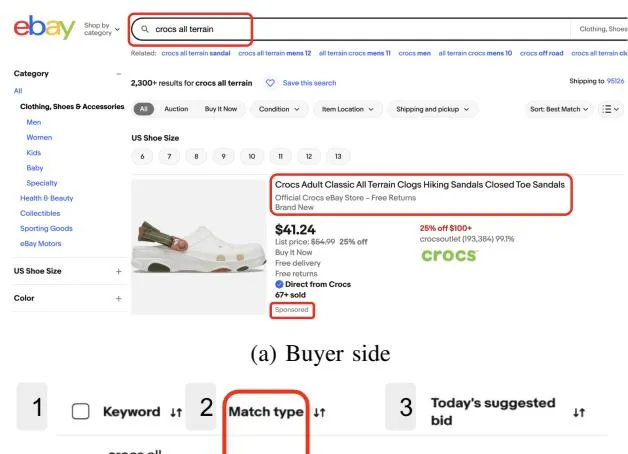
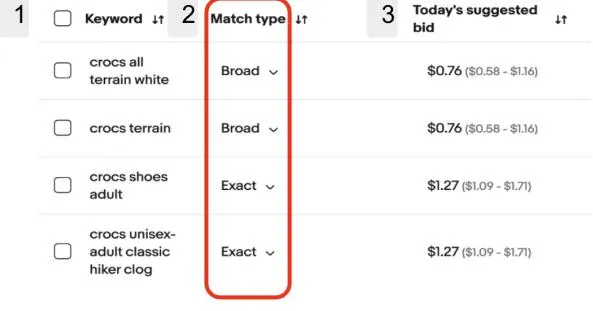
(b) Seller Side
Fig. 1: Screenshot of keyphrases for manual targeting in Promoted Listings Priority for eBay Advertising.
- Exact match type The keyphrase is matched exactly to the query accommodating different cases, plurals, contractions, and similar substitutions handled by tokenization.
- Phrase match type It is more flexible by allowing modification to the keyphrase by in-position token expansion
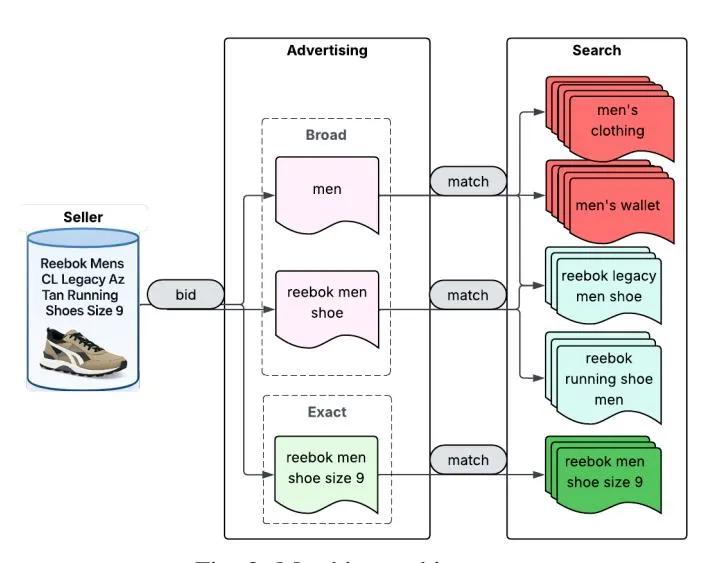
Fig. 2: Matching architecture
but maintaining the token order.
• Broad match type - In addition to the criteria of phrase match it is more flexible by disregarding order constraints.
For example, if a query is ”reebok men’s shoes size 9”, then the exact matching keyphrases can be ”reebok men shoes size 9” or ”Reebok men’s shoe size 9”. The phrase match can be ”reebok men shoe” while broad match can be ”reebok shoe men”. More examples of how different match types keyphrases for an item are matched to queries are shown in Figure 2. The platform can recommend a keyphrase with different match types to the sellers.
Previous research has focused on recommending exact match type keyphrases, popularly framing it as an Extreme Multi-Label Classification (XMC) [9], [10], where given an input item, they determine relevance to the labels which in this case are the buyer queries or keyphrases. Match types such as phrase and broad match keyphrases can alleviate problems associated with exact match type recommendations (see Section I-A). However, their recommendation strategies are under-researched as they are unlike exact match recommendations. Therefore, in this paper, we focus on other match type keyphrases by formulating the problem, designing solutions and providing insights learned in production.
A. Problems with Exact Match Type
Section titled “A. Problems with Exact Match Type”1) Shifting label distributions: Analysis reveals that in sponsored search, queries adhere to the 80/20 rule where 20% of queries generate 80% of search volume leaving 80% as long-tail queries [11], which is prominent even in ecommerce platforms like eBay. These long-tail queries are low in volume, transient, and rarely reappearing monthly. This transient nature limits the effectiveness of traditional exact match algorithms [1], [2], [3], [4], [12], as most labels won’t have future search volume. Due to the shifting dynamics of long-tail queries, predicting them individually as exact match keywords is nearly infeasible at time of inference. Instead, using other match types addresses this issue without explicit demand forecasting. Broad match keyphrases inherently address this challenge by capturing a wider set of related queries, thus effectively mitigating the unpredictability and transient nature of long-tail search patterns.
2) Management costs and Sales: Managing sponsored search campaigns demands substantial effort from sellers, compounded by the extensive set of keyphrases requiring bids [11], [13], [14]. Sellers prefer concise recommendations due to their perception and business demands [2], [12]. Other match type keyphrases are beneficial for targeting a wide array of exact queries, thereby reducing seller costs and involvement. Research suggests that when curation accuracy is high and seller bids remain competitive, broad match keyphrases yield higher sales [14].
B. Challenges for Other Match Types
Section titled “B. Challenges for Other Match Types”Though non-exact match types are lucrative there are several challenges associated with recommending them.
1) Ground Truth Hurdles: Exact match keyphrases can be directly recommended by modeling on click data logs, since they correspond precisely to buyer queries. In contrast, phrase and broad match keyphrases are more difficult to model due to the sparsity and bias of available training signals. It suffers from sparsity as the performance information of phrase/broad match types are only collected when the seller manually chooses them. Although the sellers’ previous picks of successful broad match keyphrases could seem like a good basis for ground truth, they can be heavily affected by the seller set bid amounts and auctioning dynamics [15], thus making seller-based preference data a bad choice for modeling keyphrase recommendations [12].
Several biases with click data have been well studied [2], [16], [17], [18], [8], these impact any form of supervised training for recommendation. The limited availability of ground truth data leaves a significant portion of the feature space unmarked, requiring the incorporation of counterfactual data so models can learn significant patterns. Moreover, missing label biases [19] affects substantial counterfactual negative signals, as the absence of impressions or clicks doesn’t mean that the match type keyphrases are irrelevant.
Consequently, the validity and dependability of historical performance metrics for assessing these recommendations become dubious. So, unlike exact match recommendations, which can be easily evaluated using classification metrics such as precision and recall score in a traditional setting (using ground truths), evaluating other match types presents significant challenges.
2) Active Targeting: Match type keyphrases recommended to sellers should be reachable to queries that are searched by buyers. Generated broad/phrase match keyphrases which are open vocabulary cannot reach such queries, though relevant to the item are considered futile leading to wastage of seller bids.1 This is exacerbated by the transient queries mentioned
1See discussion of Out-of-Vocabulary models [20], [21], [22], [5] and targeting in Graphex [2].
in Section I-A1 that require keyphrases to target queries that buyers search for over time. Thus, there should a way of evaluating performance of broad matches on transient queries.
3) Complexity of Reach: If a phrase/broad match keyphrase can be extended to a query using the definition in Section I, then we term it as Reach. Theoretically, a keyphrase can reach a larger set of queries, assuming there is a finite number of actively buyer search queries. The broader the keyphrase the larger the reach. For example as shown in Figure 2, a generic broad type keyphrase ”men” can reach thousands of queries pertaining to shoes, clothing, or accessories. Whereas a more specific ”reebok men shoe” can reach only queries related to the specific brand, gender and accessory.
Although the broader keyphrase is beneficial to the seller by reaching a larger query set, it can lead to inefficient curation by flooding the matching platform illustrated in Figure 2. The matching for the more generic ”men” keyphrase will include a larger number of queries which are mostly irrelevant and increase computational costs for the platform. Also, due to the matching complexity of larger reach for the generic keyphrase, there is a high possibility of mismatching the seller’s item to an unprofitable buyer search query. This suboptimal targeting not only reduces the platform’s revenue, but also diminishes the seller’s return on ad spend (ROAS). Ideally, we want the broad match keyphrase to be closely matched with the reachable queries so that it takes less modifications to match the queries exactly.
4) Execution Requirements: Executing billions of item and query inferences within a few hours is paramount for the timely completion of daily tasks. Given the high memory demands, single-node data aggregation for inference poses a failure risk, while multi-node management elevates engineering expenses. Models need frequent updates for continuous integration of new data points, as discussed in Section I-B2. Deep learning networks like Large Language Models (LLMs) face scrutiny for high execution costs, notably due to their training and inference latency [23], [2], [24], [25]. Leading LLMs often rely on GPUs, raising acquisition costs and affecting both advertisers’ and platforms’ profit margins.
C. Scope and Contributions
Section titled “C. Scope and Contributions”In this work we only focus on Broad matches instead of Phrase matches [26], [27] due to their wide applicability. We use our definition in Section I to streamline the evaluation; the actual implementation of the matching is platform-specific. We aim to tackle the challenges mentioned in Section I-B, which we briefly describe here. We present a novel framework BroadGen for recommending broad match keyphrases to sellers and evaluate its performance. Due to the lack of ground truths per item (see Challenge I-B1), we incorporate relevant buyer queries as input (see Section IV-A) to determine the effective keyphrases for an item. This also helps us target active queries for Challenge I-B2. The Challenge I-B3 implies that a good broad match keyphrase should be neither too generic nor too specific, so that it can achieve a balance between reach and effectiveness. A “too specific” broad match
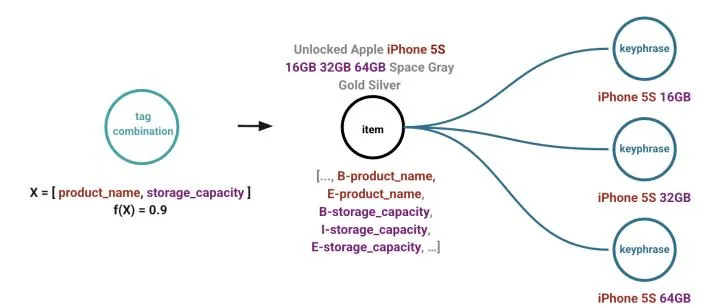
Fig. 3: Transfusion Algorithm Explained
keyphrase will behave like an exact match keyphrase which defeats the purpose. Our approach emphasizes avoiding overly broad suggestions, particularly in Section III-E, with the aim of mitigating inefficiencies within both our systems and the business metrics of sellers. Our framework has been designed to be light and fast with minimal infrastructure costs and is easily deployable in a distributed manner (Challenge I-B4) to cater to millions of sellers with an inventory of over 2.5 billion items daily. We also develop a unique evaluation methodology described in Sections IV-A and IV-B that enables us to calculate the balance in effectiveness and efficiency of the recommended broad match keyphrases in relation to the search queries it will be matched to. It allows for absence of ground truths and assesses performance over time, emphasizing their adaptability and temporal resilience (Challenge I-B2).
II. RELATED WORK
Section titled “II. RELATED WORK”Although broad match keyphrases are a crucial component, the research dedicated to specifically recommending novel broad match keyphrases is sparse. Traditionally, sellers have been responsible for selecting match types, with prior studies [28] concentrating on creating keyphrases suitable for exact matches. A simplistic recommendation strategy has involved a rule-based Match Type Curation, which applies heuristics to assess whether an exact match type keyphrase, obtained through the current recall mechanism, has historically succeeded as a broad match keyphrase. This approach, however, faces intrinsic challenges: without historical data indicating that a seller has previously chosen the keyphrase as a broad match type — this method is unable to suggest the keyphrase due to a lack of pertinent performance indicators. Note that in this method the keyphrase is a query in itself.
Some studies have focused on optimizing the matching of key-phrases to queries rather than effecting the sellers/advertiser’s selection of keyphrases. The BB-KSM model [29] is a stochastic model that utilizes Markov Chain Monte Carlo (MCMC) to initially estimate keyphrase metrics such as impressions and CTR across match types, filling in incomplete data. Subsequently, it designates a match type to each keyphrase based on these metrics with the aim of maximizing a profit objective under budgetary constraints, employing a branch-and-bound algorithm for efficient decision space exploration. Similar optimization strategies have been documented for match types [30], which recommend using buyer search queries as broad match keyphrases rather than introducing new broad keyphrases. However, with the increasing variety of items and queries in e-commerce, this approach may be inefficient and expensive. The introduction of new queries and changing distributions (refer to Section I-A1) further reduces profitability. Studies like [31] apply query substitution methods [32], [33] to connect broad keyphrases with buyer queries by preprocessing frequently searched queries and utilizing predefined substitution mappings.
Transfusion is an eBay’s match type generative model developed based on its in-house NER (Named Entity Recognition) model [34], [35] to recommend broad match type keyphrases especially for cold start items. The model generates keyphrases for a specified item utilizing the tokens present in its title. It ensures that these keyphrases align with popular and historically high-performing NER tag combinations within a particular meta category. For instance, as shown in Figure 3, the model identifies that the NER tag combination of product_name and storage_capacity is popular in this category based on the scoring function f(X). The algorithm then construct 3 keyphrases: ”iPhone 5S 16GB”, ”iPhone 5S 32GB”, ”iPhone 5S 64GB” based on the tokens corresponding to this NER tag combination from the item title. In this work, for comparison, we use a proxy for the rulebased match type curation and the Transfusion model against our model BroadGen.
III. METHODOLOGY
Section titled “III. METHODOLOGY”A. Terms, Notations and Formulation
Section titled “A. Terms, Notations and Formulation”Our framework requires a set of existing (buyer search) queries denoted as Q and the item title t for each item to recommend a set of keyphrases denoted as K. The goal is for the keyphrase set K to be broad matched to the queries Q. Each query , each keyphrase and the title t are in the form a list of tokens.2 We formulate the problem as String Clustering on the set of query strings (Q), to exploit the commonality within a cluster of queries and generate a representation for each cluster. The underlying intuition is that the cluster representation serves as the broad match keyphrase capable of addressing both the queries within the set and prospective queries beyond it. Our framework has three cores, Input generation (III-B) which generates the input matrix from the set of input queries. The Clustering core (III-C) which groups the queries using the input matrix. The Representation generation (III-D) constructs a representative ordered string for each cluster.
B. Input Generation
Section titled “B. Input Generation”Two input matrices are constructed, Anchor Similarity Matrix and Query-Query Similarity Matrix , where determines cardinality. In constructing A, a |t|-dimensional vector is generated for each query. This vector comprises of binary values, where 1s and 0s indicate the
Algorithm 1 Retrieve clusters generated by
Section titled “Algorithm 1 Retrieve clusters generated by R(⋅,⋅)R(\cdot, \cdot)R(⋅,⋅)”Input: Input matrix , threshold and required number of clusters |K|
Output: List of clusters
1: function RETRIEVE(R, \hat{Z}, \tilde{r}, |K|)
2: C \leftarrow R(\tilde{Z}, \tilde{r})
3: for |C| < |K| do
4: \tilde{r} \leftarrow \tilde{r} - \epsilon
5: C \leftarrow R(\tilde{Z}, \tilde{r})
6: if |C| > |K| then
7: C \leftarrow pick(C, |K|) \triangleright Pick largest clusters.
8: return Cquery token’s presence in the title. The construction of S is done by computing the common token count between each pair of queries in Q. Each row of S can be considered as a |Q|-dimensional vector that represents each query depending on similarity with other queries. Each vector of matrix S is normalized by dividing by its maximum, while each vector of the matrix A is normalized by its sum. The Query-Query Similarity matrix S is transformed into a distance matrix by .
(1)
The core combines both the matrices A and S as shown in Equation 1. The normalized augmented matrix , provides a vector representation for each query anchoring in relation to the title and acts as a query distance vector when there is insufficient information in the anchor representation.
C. Clustering Core
Section titled “C. Clustering Core”The core functionality starts with computing the pairwise distance between each pair of vectors as demonstrated in Equation 2. Now, with the pairwise distance matrix , the core performs agglomerative clustering [36] by constructing linkage distances with ward variance minimization [37] and optimal leaf ordering [38]. We denote the clustering function as .
\tilde{Z} = 1 - \frac{z_i \cdot z_j}{||z_i||_2 \cdot ||z_j||_2} \tag{2}
outputs a set of clusters , where each cluster groups similar queries. While, is a crucial hyperparameter called as the threshold ratio that determines how many clusters are formed.3 A fixed value of can lead to more or less number of clusters |C| than the requirement |K|. The Algorithm 1 shows how the required number of clusters is retrieved, through decreasing the threshold by epsilon (line 4) when there are less clusters. If there are more clusters than required, it picks the top |K| clusters (line 7) in decreasing order of the cluster size.
3We use the inconsistent criterion that compares the linkage distance of current and previous levels of the hierarchy.
<sup>2A proprietary tokenization scheme handles normalization and stop word removal
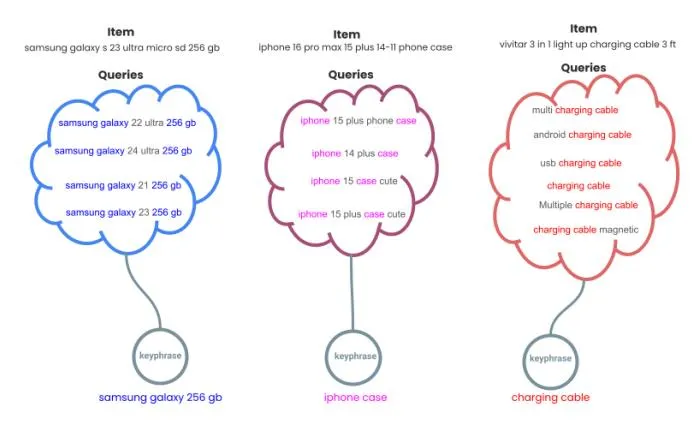
Fig. 4: Illustration of BroadGen.
D. Representation Generation
Section titled “D. Representation Generation”A representation for each cluster in C depicts a keyphrase that can be extended to queries in the cluster. In the final core, the representation is determined as the set of tokens common among the tokenized queries within each cluster. At times, clusters can be large leading to single or no tokens (in absence of commonality). In these situations, an optimal subset of the cluster is identified whose representation is more than one token. The common tokens from each cluster need to be ordered before concatenating into a string. We employ a graph-based approach to infer an ordering of the common tokens based on their relative positions across the queries. A graph is constructed with all tokens as the vertices; for each co-occurring pair of tokens a directed edge is added indicating local precedence. A topological sort [39] of the graph using a depth-first search algorithm produces a consistent global ordering of the tokens. This method of determining precedence is rooted in prior work, such as sentence ordering task [40]. For each cluster, the common tokens are arranged following the global order and represented as a string.
E. Implementation Details
Section titled “E. Implementation Details”We show an example of our model on three different items in Figure 4. For each item, only one cluster of queries is shown along with the keyphrases that are generated. 4 Aligning with our goals described in Section I-B4, we develop the framework in Python to enable its integration into eBay’s in-house Spark system. This off-loads the overhead of data transfer and parallelism to the spark system, making it feasible to scale for billions of items while mitigating engineering costs. The cores of the framework are designed to be fast and efficient. The asymptotic time complexity of all the cores is O(|Q| 2 ) which might seem large but Q is per item which is typically in the thousands.
The framework’s recommendations are adaptive to the input queries — depending on number and quality of queries, the recommendations change significantly. Clustering the queries helps us optimize the reach of a particular keyphrase by
| Category | # Items | # Unique Queries | #Queries/#Items | |||
|---|---|---|---|---|---|---|
| CAT 1 | 210M | 17.2M | 15.12 | |||
| CAT 2 | 13.8M | 12.2M | 40.60 | |||
| CAT 3 | 14.9M | 7.5M | 21.52 | |||
| CAT 4 | 4.3M | 2.8M | 29.80 |
TABLE I: Details of meta categories from eBay.
limiting it’s tokens to emerge from the cluster which assists to some extent in identifying relevant reach (to be discussed later in Section IV-B2). To obtain the cluster representation, we impose specific constraints to prevent the inclusion of generic broad keyphrases from the cluster. If the retrieved representation consists of a single token, we instead use a subset of the cluster for retrieval. The subset is chosen from all possible combinations of size |C| − 1 where the retrieved representation is more than a single token.
F. Explainability
Section titled “F. Explainability”Since BroadGen is based on token correspondence between candidate exact match keyphrases (queries) with an underlying pre-query population coming from historical buyer interaction, it is explainable. Given a BroadGen keyphrase we would be able to provide the exact clustering of the input pre-queries that were considered and the token distribution within the cluster, summarizing the differences between the queries as illustrated in Figure 4.
IV. EXPERIMENTATION
Section titled “IV. EXPERIMENTATION”A. Setup
Section titled “A. Setup”- 1) OOT Formulation: To evaluate the effectiveness of broad match keyphrases in addressing the challenge of shifting label distribution, we assess their generalized performance in an Out-of-Time (OOT) [20] setting. 5 Specifically, the algorithms for generating broad match keyphrases use as input the historical queries searched by buyers prior to time T, termed as Prequeries and evaluated against the query distribution observed in the subsequent T + 30 day period called as Post-queries.
- 2) Data Augmentation: The primary limitation of Broad-Gen’s methodology lies in its dependency on historical interaction data between items and queries for the generation of keyphrases. Although the algorithm functions effectively under warm start scenarios, it encounters difficulties with new or “cold” items that have limited interaction data available. To address this shortcoming, our approach incorporates input from state-of-the-art models deployed at eBay to provide precise keyphrase recommendations for cold-start items [3], [2], thereby bolstering the performance of our algorithm when dealing with cold-start conditions.6
- 3) Datasets: We present results on 4 meta-categories of eBay, CAT 1 to CAT 4, each representing a group whose size is based on number of items and queries. The category sizes are largest from CAT 1 to CAT 4, the detailed statistics for each category is presented in Table I. For each category, each
4This is just for illustration, there can be multiple clusters per item depending on the number of input queries.
5Commonly referred to as out-of-distribution generalization [41], [42], [43]. 6This kind of data augmentation has been studied in [20].
item’s future query distribution Q is limited to 1000 queries. Each of these 1000 queries has at least 1 token overlap with the item’s title.
B. Evaluation Framework
Section titled “B. Evaluation Framework”1) Defining Relevance: In eBay’s Advertising ecosystem, a downstream relevance model filters the queries matched by broad match keyphrases, which is done by eBay Search. Hence, it is crucial to avoid unnecessary recommendations that are too generic which impacts the downstream efficiency and focus on passing the subsequent filtering processes by Search on the matched queries. In addition, the queries have to be relevant to the item in terms of human judgment, or else it will not be engaged by the buyers. To assess the relevance between item and query, we employ a BERT [44] cross-encoder model [45] that has been fine-tuned using judgment data derived from Large Language Models (LLMs) at eBay [12]. This model’s relevance judgment emulates human judgment while still aligning with eBay Search’s definition of relevance. We use this relevance judgment to check whether a query is relevant to an item for our evaluation. Employing this cross-encoder’s judgment also captures the semantic nuances of relevance that traditional lexical scoring methods generally overlook [8].
A wider reach for broad match keyphrases will lead to sufficient advertising impressions provided they have a competitive bid value. A good accuracy for broad match keyphrases in terms of relevant targeting will lead to better efficiency metrics like Search relevance filter pass rate for its Advertising auctions while still maintaining a healthy margin for sellers with an increased buyer engagement as a consequence. We describe achieving this desired property as maximizing the ‘relevant reach’ — A good broad match keyphrase is generally characterized by a high proportion of relevant queries in relation to the item that it reaches. In order to quantify and measure this, we design the following two evaluation metrics.
2) Relevant Reach Estimation (RRE): The relevant reach of a broad match keyphrase is subject to the distribution of buyers’ search queries, the broad matching mechanism and sellers’ advertising bids and budget. Although it’s infeasible to compute this metric offline, we can approximate it through sampling from the Post-query distribution. In addition, we define a relevance function based on the definition relevance explicated in IV-B1 and a broad match function B(k, q) as followed:
(3)
(4)
\tag{5}
, where k is a keyphrase and q is a query. For broad match keywords at time T, the future search query distribution Q is estimated by computing the search volumes of each queries from time T to T+30 in practice. We can now define the precision/recall type of metrics as:
(6)
In practice, we choose the broad match criterion for B(k,q) to be 1 if the tokens of k are a subset of the tokens of q. We relax this criterion when k contains N tokens (N >= 3) where we require q to contain at least N-1 tokens from k.
3) Proportional Token Reach (PTR): While the previous metrics take care of estimating the relevant reach, a very generic broad match, by definition, can achieve the highest scores on the metrics. Hence, we also need to evaluate how specific the broad match is relative to the queries. Considering keyphrase k and query q as set of tokens, we define Proportional Token Reach as:
(7)
The PTR computes how similar two sets of tokens are while penalizing missing tokens and additional tokens that are regulated by the scalars and , respectively. For each item, the PTR is computed for each of its recommended keyphrases and the maximum is chosen. This is averaged over all items to report the final score.
C. Offline Performance
Section titled “C. Offline Performance”We compare with the Transfusion and the Match Type Curation models from Section II. As a proxy for the match type curation strategy, we use the top pre-queries (used as input for BroadGen) as the recommended broad match type keyphrases and term it as the Prequery model. We generate 5 broad match type keyphrases for each model. BroadGen(Aug) indicates BroadGen with the data augmentation.
- RRE Results: We show here the RRE’s precision and recall scores as defined in Section IV-B2 relative to the prequery model on the 4 categories of eBay in Table II. We use the traditional definition of F1 on top our precision and recall scores from Equation 6. BroadGen(Aug) achieves the highest recall and F1 scores, despite having precision similar to the pre-query model. While generally exhibiting high precision, Transfusion has the lowest recall and F1 scores. Intuitively, recall represents the effectiveness of broad match keyphrases by measuring their ability to capture a comprehensive set of queries relevant to the seed item. Precision, on the other hand, reflects the accuracy of these broad keyphrases, indicating the overall relevance of the buyer queries matched by Search.
| Models | Precision | Recall | F1 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CAT 1 | CAT 2 | CAT 3 | CAT 4 | CAT 1 | CAT 2 | CAT 3 | CAT 4 | CAT 1 | CAT 2 | CAT 3 | CAT 4 | |
| PreQuery Model | 0.48 | 0.52 | 0.50 | 0.63 | 0.32 | 0.38 | 0.32 | 0.34 | 0.38 | 0.44 | 0.39 | 0.44 |
| Transfusion | 0.54 | 0.56 | 0.53 | 0.63 | 0.19 | 0.21 | 0.18 | 0.20 | 0.29 | 0.31 | 0.27 | 0.38 |
| BroadGen | 0.47 | 0.53 | 0.54 | 0.72 | 0.15 | 0.30 | 0.21 | 0.37 | 0.22 | 0.38 | 0.30 | 0.49 |
| BroadGen(Aug) | 0.49 | 0.51 | 0.50 | 0.72 | 0.38 | 0.54 | 0.44 | 0.63 | 0.43 | 0.52 | 0.47 | 0.67 |
| Oracle | 0.32 | 0.46 | 0.44 | 0.78 | 1.00 | 1.00 | 1.00 | 1.00 | 0.48 | 0.63 | 0.61 | 0.88 |
TABLE II: Precision, recall and F1 metrics for all the models. Darker hues represent more favorable outcomes.
To better understand how does RRE fairs when there is a perfect baseline, we design an Oracle that reports all the 1000 queries for any item as broad matched (B(·) = 1), which includes both BERT relevant and non-relevant queries leading to a 100% recall model. Although the recall of this model is 100%, as seen in Table II, the precision is generally the lowest. This is due to the large number of queries the Oracle covers while the numerator is limited to the BERT relevant queries for each item. In essence, not every query reachable by a keyphrase is relevant to the item thus a balance between the precision and recall is essential.
2) PTR Results: Table III shows the average PTR scores as defined in Section IV-B3 of the BroadGen(Aug) model relative to the Prequery model. A higher PTR score indicates how the keyphrases lexically resemble the queries — it takes few modifications to a keyphrase to match a relevant query. The observations are shown with two values of α and β that control the penalty for dissimilarity. For both values of α and β, BroadGen(Aug) performs better in all categories. When α = 1.0 and β = 1.5, PTR penalizes extra words in the keyphrases more than missing words in the queries and when α = 1.5, β = 1.0 it does vice-versa. Our model performs relatively better in the first case indicating that it requires less deletion of tokens to match the query. This is crucial as many platform’s implementation of broad matching prefer not to delete tokens. BroadGen and Prequery models’ similar performance in the second case suggests that our recommendations are not too generic. Transfusion being generative and not informed by any historical precedence, many of its keyphrases’ tokens do not match that of the queries resulting in lower PTR.
| Model | α | Params β | CAT 1 | CAT 2 | CAT 3 | CAT 4 | ||
|---|---|---|---|---|---|---|---|---|
| BroadGen | 1.0 | 1.5 | 1.16× | 1.08× | 1.18× | 1.19× | ||
| (Aug) | 1.5 | 1.0 | 1.08× | 1.01× | 1.12× | 1.12× | ||
| Transfusion | 1.0 | 1.5 | 0.64× | 0.71× | 0.43× | 0.55× | ||
| 1.5 | 1.0 | 0.61× | 0.67× | 0.40× | 0.52× |
TABLE III: Average PTR relative to the prequery model. Darker hues show more favorable outcomes.
D. Ablation Studies
Section titled “D. Ablation Studies”1) Dependency on Input Queries: The performance of BroadGen(Aug) in contrast to BroadGen in Table II indicates the importance of data augmentation for the quality of recommendations. Across all categories, recall and F1 scores experience a sharp decline, while precision changes minimally. Although precision improves for CAT 2 and CAT 3, it does not significantly compensate for the drop in recall.
To enhance our understanding, we examine the percentage change in BroadGen’s scores when relying solely on prequeries. Table IV illustrates a notable decline in recall and F1 scores for items with fewer than 10 input pre-queries. This situation is akin to dealing with cold items, where enough related queries are not available. With a limited number of input queries, there is insufficient data to effectively cluster and generate keyphrases. The improved performance of items with more than 10 pre-queries highlights the importance of increasing the number of queries, aided by recommendations from other recall models, which proved to be transformative for BroadGen(Aug).
| Cats. | # Pre-queries >= 10 | # Pre-queries < 10 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Precision | Recall | F1 | Precision | Recall | F1 | |||||
| CAT 1 | +1.8% | +72% | +60.6% | -0.7% | -28.2% | -23.7% | ||||
| CAT 2 | +0.2% | +23.3% | +20.3% | -0.4% | -47.6% | -41.3% | ||||
| CAT 3 | -2.2% | +39.1% | +33.4% | +2.3% | -40.3% | -34.3% | ||||
| CAT 4 | +1.9% | +40.1% | +33.3% | -1.9% | -39.2% | -32.5% |
TABLE IV: Effect of number of pre-queries on BroadGen.
- 2) Various Clustering Algorithms: Different clustering algorithms can replace the BroadGen clustering core outlined in Section III-C. Algorithms like HDBSCAN [46] are unsuitable for BroadGen due to its requirement for a minimum cluster size, which can lead to grouping dissimilar queries. Table V compares BroadGen’s performance when its agglomerative core is replaced with Affinity Propagation [47] and Bayesian Gaussian Mixture [48]. We present F1 scores based on the RRE metric alongside PTR scores. The Agglomerative method shows superior F1 scores in CAT 1-3, albeit slightly lower in CAT 4. Its PTR scores are notably higher than the other algorithms, as it offers greater flexibility in clustering, enabling extraction of longer keyphrases beneficial for match-type keyword recommendations. KMeans and Spectral Clustering were also evaluated, but their excessive runtime of over 140ms and 190ms per input on average impedes daily batch processing.
- 3) Number of Keyphrases: Achieving a good balance with recall and precision for high F1 is difficult due to the limitation on the number of broad match recommendations (see Section I-A2) — fewer keyphrases lead to fewer queries being reached. BroadGen(Aug) also maintains balance when increasing the number of broad match recommendations. This is evident from Figure 5 where the recall as well as precision
| Model - Clustering algorithm | F1 (I | RRE) | PTR | |||||
|---|---|---|---|---|---|---|---|---|
| Wioder - Clustering algorithm | CAT_1 | CAT_2 | CAT_3 | CAT_4 | CAT_1 | CAT_2 | CAT_3 | CAT_4 |
| BroadGen(Aug) - Affinity Propagation | 0.39 | 0.49 | 0.42 | 0.69 | 0.20 | 0.24 | 0.22 | 0.28 |
| BroadGen(Aug) - Bayesian Gaussian Mixture | 0.36 | 0.45 | 0.43 | 0.64 | 0.18 | 0.20 | 0.18 | 0.25 |
| BroadGen(Aug) - Agglomerative | 0.42 | 0.53 | 0.47 | 0.67 | 0.25 | 0.32 | 0.28 | 0.36 |
TABLE V: Comparing F1 (RRE) and PTR scores of BroadGen(Aug), when the clustering core is replaced with different algorithms. and was used for PTR.
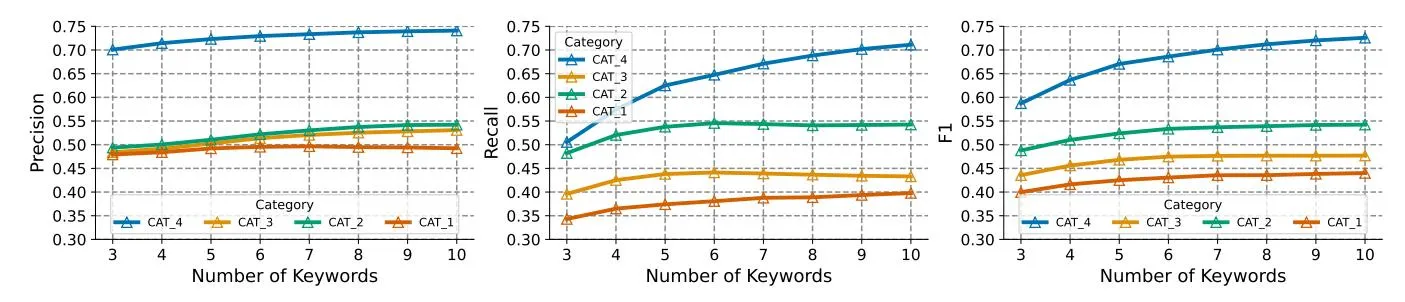
Fig. 5: Comparison of Precision, Recall and F1 for BroadGen(Aug) across keyword counts and categories.
increase with the number of recommendations. The trend is notably elevated for CAT_4, as its ambiguous characteristics lead to item diversity, resulting in a sparse distribution of relevant queries.
E. Online Deployment
Section titled “E. Online Deployment”-
- Production Implementation: The daily recommendations of BroadGen(Aug) is made possible through eBay’s PySparkbased [49] batch inference system. The speed of our model is considerable — with 1000 Spark executors and 4 cores, it only takes 45 minutes to finish the whole batch inference on a space of 1.5 billion items and their corresponding Oueries. The inputs of the production model are pre-queries with at least 5 impressions in the past 30 days augmented with exact keyphrases that pass the Bert relevance filter [12] from two of our recall models — fastText [50], [51] and Graphite [3]. These two recall models are trained as Extreme Multi-Label Classifiers [52] with relevant past queries as labels for exact keyphrase recommendations. With BroadGen’s processing ability, we can incorporate newer queries on a daily basis accounting for shifting label distributions (see Section I-A1) thus solving Challenge I-B4.
-
- Impact: BroadGen(Aug) was released as an additional broad match keyphrase recall for English-speaking countries over a 15-day A/B test, the treatment group received Broad-Gen(Aug) recommendations, while the control group did not. BroadGen(Aug) achieved a boost in broad match impressions and clicks per item by 21.73% and 16.71% respectively, without affecting other metrics like CTR, CVR, or ROAS showcasing it’s effectiveness. Furthermore, BroadGen(Aug) increased the number of auctions that passed the search relevance filter for new broad keyphrases by 16.87%, reflecting the improvement in efficiency of our broad match recommendations.
-
- Sensitivity Analysis: As noted in Section I-A1, exactmatch keyphrases are vulnerable to changes in buyer search
behavior, while broad-match keyphrases offer some adaptability by utilizing a flexible matching mechanism. Broad-Gen(Aug) advances this strategy by incorporating past queries to adjust to shifting query distributions. To evaluate its performance, we monitored BroadGen over 30 consecutive days post-advertising campaign initiation. Figure 6 illustrates that BroadGen keyphrases consistently improve beyond the initial 10 days, encountering a minor dip after three weeks, but ultimately achieving an average daily performance increase of 0.46%. This indicates enhanced effectiveness and stability against query drift. Conversely, in the control set, exactmatch and broad-match keyphrases both exhibit a continual decline, though broad-match keyphrases fare slightly better, declining at -1.02% daily, compared to -1.11% for exactmatch keyphrases.
V. CONCLUSION AND FUTURE WORK
Section titled “V. CONCLUSION AND FUTURE WORK”We introduce a new framework for advancing non-exact match type recommendations, addressing the challenges associated with exact keyphrase suggestions in sponsored search advertising. Our distributed model, BroadGen, employs a
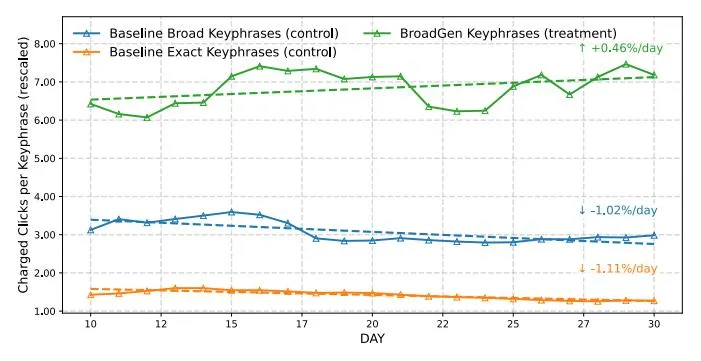
Fig. 6: Performance drift over time for the BroadGen keyphrases in the treatment group vs baseline exact match and broad match keyphrases from the control group
string clustering approach to offer broad match recommendations, efficiently handling up to a billion items in under an hour. Without access to ground truth match type keyphrases, we construct keyphrases by modeling the underlying token correspondence in historical queries. We also propose a unique evaluation methodology and metrics to evaluate broad match performance when real-world impressions and clicks are not available. In the future, we aim to expand our approach by implementing neural network equivalents to the cores of our framework. Such as, using text embeddings for input matrix generation while using a k-means or similar clustering algorithm for grouping the queries. Text summarization for the cluster representation core can be tricky as they tend to generate too generic or specific keyphrases. With the adoption of more complex cores based on LLMs we can subsequently cater to broader definitions of semantic broad match [26], [27], [53] and extend beyond token-based broad match in the future. Training different aspects of such a model will be difficult due to the absence of concrete supervised signals and the constraints of broad/phrase match recommendation. Moreover, the latency and infrastructure costs of these models will also be a concern due to growing number of items and queries.
REFERENCES
Section titled “REFERENCES”-
[1] S. Kharbanda, D. Gupta, G. K, P. Malhotra, A. Singh, C.-J. Hsieh, and R. Babbar, “Unidec: Unified dual encoder and classifier training for extreme multi-label classification,” in Proceedings of the ACM on Web Conference 2025, ser. WWW ‘25. New York, NY, USA: Association for Computing Machinery, 2025, p. 4124–4133. [Online]. Available: https://doi.org/10.1145/3696410.3714704
-
[2] A. Mishra, S. Dey, H. Wu, J. Zhao, H. Yu, K. Ni, B. Li, and K. Madduri, ” GraphEx: A Graph-Based Extraction Method for Advertiser Keyphrase Recommendation ,” in 2025 IEEE 41st International Conference on Data Engineering (ICDE). Los Alamitos, CA, USA: IEEE Computer Society, May 2025, pp. 4400–4413. [Online]. Available: https://doi.ieeecomputersociety.org/10.1109/ICDE65448.2025.00330
-
[3] A. Mishra, S. Dey, J. Zhao, M. Wu, B. Li, and K. Madduri, “Graphite: A graph-based extreme multi-label short text classifier for keyphrase recommendation,” in Frontiers in Artificial Intelligence and Applications. IOS Press, Oct. 2024, pp. 4657–4664. [Online]. Available:http://dx.doi.org/10.3233/FAIA241061
-
[4] K. Dahiya, D. Saini, A. Mittal, A. Shaw, K. Dave, A. Soni, H. Jain, S. Agarwal, and M. Varma, “Deepxml: A deep extreme multi-label learning framework applied to short text documents,” in Proceedings of the 14th ACM International Conference on Web Search and Data Mining (WSDM ‘21). Association for Computing Machinery, 2021, p. 31–39. [Online]. Available:https://doi.org/10.1145/3437963.3441810
-
[5] Z. Song, J. Chen, H. Zhou, and L. Li, “Triangular bidword generation for sponsored search auction,” in Proceedings of the 14th ACM International Conference on Web Search and Data Mining, ser. WSDM ‘21. New York, NY, USA: Association for Computing Machinery, 2021, p. 707–715. [Online]. Available: https://doi.org/10.1145/3437963.3441819
-
[6] V. Jain, J. Prakash, D. Saini, J. Jiao, R. Ramjee, and M. Varma, “Renee: End-to-end training of extreme classification models,” Proceedings of Machine Learning and Systems (MLSys ‘23’), 2023. [Online]. Available: https://proceedings.mlsys.org/paper files/paper/ 2023/file/c62748872b8c4c49799fc0fa0878515f-Paper-mlsys2023.pdf
-
[7] K. Dahiya, S. Yadav, S. Sondhi, D. Saini, S. Mehta, J. Jiao, S. Agarwal, P. Kar, and M. Varma, “Deep encoders with auxiliary parameters for extreme classification,” in Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD ‘23). Association for Computing Machinery, 2023, p. 358–367. [Online]. Available:https://doi.org/10.1145/3580305.3599301
-
[8] S. Dey, W. Zhang, H. Wu, B. Dong, and B. Li, “Middleman bias in advertising: Aligning relevance of keyphrase recommendations with search,” in Companion Proceedings of the ACM on Web Conference 2025, ser. WWW ‘25. New York, NY, USA: Association for Computing Machinery, 2025, p. 2701–2705. [Online]. Available: https://doi.org/10.1145/3701716.3717858
-
[9] K. Bhatia, K. Dahiya, H. Jain, P. Kar, A. Mittal, Y. Prabhu, and M. Varma, “The extreme classification repository: Multi-label datasets and code,” 2016. [Online]. Available: http://manikvarma.org/downloads/ XC/XMLRepository.html
-
[10] R. Agrawal, A. Gupta, Y. Prabhu, and M. Varma, “Multi-label learning with millions of labels: Recommending advertiser bid phrases for web pages,” in Proceedings of the 22nd International Conference on World Wide Web (WWW ‘13), 2013, pp. 13–24.
-
[11] Y. Zhang, W. Zhang, B. Gao, X. Yuan, and T.-Y. Liu, “Bid keyword suggestion in sponsored search based on competitiveness and relevance,” Information Processing & Management, vol. 50, no. 4, pp. 508–523, 2014. [Online]. Available: https://www.sciencedirect.com/ science/article/pii/S0306457314000144
-
[12] S. Dey, H. Wu, and B. Li, “To judge or not to judge: Using llm judgements for advertiser keyphrase relevance at ebay,” 2025. [Online]. Available:https://arxiv.org/abs/2505.04209
-
[13] W. Amaldoss, K. Jerath, and A. Sayedi, “Keyword management costs and “broad match” in sponsored search advertising,” Marketing Science, vol. 35, no. 2, pp. 259–274, 2016. [Online]. Available: http://www.jstor.org/stable/44012149
-
[14] S. Yang, J. Pancras, and Y. A. Song, “Broad or exact? search ad matching decisions with keyword specificity and position,” Decision Support Systems, vol. 143, p. 113491, 2021. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S0167923621000014
-
[15] B. Edelman, M. Ostrovsky, and M. Schwarz, “Internet advertising and the generalized second-price auction: Selling billions of dollars worth of keywords,” American Economic Review, vol. 97, no. 1, p. 242–259, March 2007. [Online]. Available: https://www.aeaweb.org/articles?id= 10.1257/aer.97.1.242
-
[16] J. Chen, H. Dong, X. Wang, F. Feng, M. Wang, and X. He, “Bias and debias in recommender system: A survey and future directions,” ACM Trans. Inf. Syst., vol. 41, no. 3, Feb. 2023. [Online]. Available: https://doi.org/10.1145/3564284
-
[17] F. Vella, “Estimating models with sample selection bias: A survey,” The Journal of Human Resources, vol. 33, no. 1, pp. 127–169, 1998. [Online]. Available:http://www.jstor.org/stable/146317
-
[18] J. Gao, S. Han, H. Zhu, S. Yang, Y. Jiang, J. Xu, and B. Zheng, “Rec4ad: A free lunch to mitigate sample selection bias for ads ctr prediction in taobao,” in Proceedings of the 32nd ACM International Conference on Information and Knowledge Management, ser. CIKM ‘23. New York, NY, USA: Association for Computing Machinery, 2023, p. 4574–4580. [Online]. Available:https://doi.org/10.1145/3583780.3615496
-
[19] H. Steck, “Training and testing of recommender systems on data missing not at random,” in Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, ser. KDD ‘10. New York, NY, USA: Association for Computing Machinery, 2010, p. 713–722. [Online]. Available:https://doi.org/10.1145/1835804.1835895
-
[20] R. H. Zhang, B. Uc¸ar, S. Dey, H. Wu, B. Li, and R. Zhang, “From lazy to prolific: Tackling missing labels in open vocabulary extreme classification by positive-unlabeled sequence learning,” in Findings of the Association for Computational Linguistics: NAACL 2025, L. Chiruzzo, A. Ritter, and L. Wang, Eds. Albuquerque, New Mexico: Association for Computational Linguistics, Apr. 2025, pp. 1–16. [Online]. Available:https://aclanthology.org/2025.findings-naacl.1/
-
[21] D. Simig, F. Petroni, P. Yanki, K. Popat, C. Du, S. Riedel, and M. Yazdani, “Open vocabulary extreme classification using generative models,” in Findings of the Association for Computational Linguistics: ACL 2022, S. Muresan, P. Nakov, and A. Villavicencio, Eds. Dublin, Ireland: Association for Computational Linguistics, May 2022, pp. 1561–1583. [Online]. Available: https://aclanthology.org/ 2022.findings-acl.123
-
[22] N. Gupta, S. Bohra, Y. Prabhu, S. Purohit, and M. Varma, “Generalized zero-shot extreme multi-label learning,” in Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, ser. KDD ‘21. New York, NY, USA: Association for Computing Machinery, 2021, p. 527–535. [Online]. Available: https://doi.org/10.1145/3447548.3467426
-
[23] J. Kaddour, J. Harris, M. Mozes, H. Bradley, R. Raileanu, and R. McHardy, “Challenges and applications of large language models,” 2023. [Online]. Available:https://arxiv.org/abs/2307.10169
-
[24] A. Sharma, V. M. Bhasi, S. Singh, R. Jain, J. R. Gunasekaran, S. Mitra, M. T. Kandemir, G. Kesidis, and C. R. Das, “Stash: A comprehensive stall-centric characterization of public cloud vms for distributed deep learning,” in 2023 IEEE 43rd International Conference on Distributed Computing Systems (ICDCS), 2023, pp. 1–12.
-
[25] R. Pope, S. Douglas, A. Chowdhery, J. Devlin, J. Bradbury, J. Heek, K. Xiao, S. Agrawal, and J. Dean, “Efficiently scaling transformer inference,” in Proceedings of Machine Learning and Systems, D. Song, M. Carbin, and T. Chen, Eds., vol. 5. Curan, 2023, pp. 606–624. [Online]. Available: https://proceedings.mlsys.org/paper files/paper/ 2023/file/c4be71ab8d24cdfb45e3d06dbfca2780-Paper-mlsys2023.pdf
-
[26] eBay Inc., “Priority campaign strategy — ebay.com,” https://www.ebay.com/help/selling/ebay-advertising/promoted-listings/ priority-campaign-strategy?id=5299, 2025, [Accessed 28-04-2025].
-
[27] G. Inc., “About keyword matching options - Google Ads Help — support.google.com,” https://support.google.com/google-ads/answer/ 7478529?hl=en, 2025, [Accessed 28-04-2025].
-
[28] M. Scholz, C. Brenner, and O. Hinz, “Akegis: automatic keyword generation for sponsored search advertising in online retailing,” Decision Support Systems, vol. 119, pp. 96–106, 2019. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S0167923619300168
-
[29] H. Li and Y. Yang, “Keyword targeting optimization in sponsored search advertising: Combining selection and matching,” Electronic Commerce Research and Applications, vol. 56, p. 101209, 2022. [Online]. Available: https://www.sciencedirect.com/science/article/pii/ S1567422322000928
-
[30] E. Even Dar, V. S. Mirrokni, S. Muthukrishnan, Y. Mansour, and U. Nadav, “Bid optimization for broad match ad auctions,” in Proceedings of the 18th International Conference on World Wide Web, ser. WWW ‘09. New York, NY, USA: Association for Computing Machinery, 2009, p. 231–240. [Online]. Available: https://doi.org/10.1145/1526709.1526741
-
[31] F. Radlinski, A. Broder, P. Ciccolo, E. Gabrilovich, V. Josifovski, and L. Riedel, “Optimizing relevance and revenue in ad search: a query substitution approach,” in Proceedings of the 31st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, ser. SIGIR ‘08. New York, NY, USA: Association for Computing Machinery, 2008, p. 403–410. [Online]. Available:https://doi.org/10.1145/1390334.1390404
-
[32] R. Jones and D. C. Fain, “Query word deletion prediction,” in Proceedings of the 26th Annual International ACM SIGIR Conference on Research and Development in Informaion Retrieval, ser. SIGIR ‘03. New York, NY, USA: Association for Computing Machinery, 2003, p. 435–436. [Online]. Available:https://doi.org/10.1145/860435.860538
-
[33] R. Jones, B. Rey, O. Madani, and W. Greiner, “Generating query substitutions,” in Proceedings of the 15th International Conference on World Wide Web, ser. WWW ‘06. New York, NY, USA: Association for Computing Machinery, 2006, p. 387–396. [Online]. Available: https://doi.org/10.1145/1135777.1135835
-
[34] Y. Xin, E. Hart, V. Mahajan, and J.-D. Ruvini, “Learning better internal structure of words for sequence labeling,” in Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, E. Riloff, D. Chiang, J. Hockenmaier, and J. Tsujii, Eds. Brussels, Belgium: Association for Computational Linguistics, Oct.-Nov. 2018, pp. 2584–2593. [Online]. Available:https://aclanthology.org/D18-1279/
-
[35] C. Palen-Michel, L. Liang, Z. Wu, and C. Lignos, “QueryNER: Segmentation of E-commerce queries,” in Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), N. Calzolari, M.-Y. Kan, V. Hoste, A. Lenci, S. Sakti, and N. Xue, Eds. Torino, Italia: ELRA and ICCL, May 2024, pp. 13 455–13 470. [Online]. Available: https://aclanthology.org/2024.lrec-main.1178/
-
[36] D. Mullner, “Modern hierarchical, agglomerative clustering algorithms,” ¨ 2011. [Online]. Available:https://arxiv.org/abs/1109.2378
-
[37] J. H. W. Jr., “Hierarchical grouping to optimize an objective function,” Journal of the American Statistical Association, vol. 58, no. 301, pp. 236–244, 1963. [Online]. Available: https://www.tandfonline.com/doi/ abs/10.1080/01621459.1963.10500845
-
[38] Z. Bar-Joseph, D. K. Gifford, and T. S. Jaakkola, “Fast optimal leaf ordering for hierarchical clustering,” Bioinformatics, vol. 17,
-
no. suppl 1, pp. S22–S29, 06 2001. [Online]. Available: https: //doi.org/10.1093/bioinformatics/17.suppl 1.S22
-
[39] R. E. Tarjan, “Edge-disjoint spanning trees and depth-first search,” p. 171–185, 1976. [Online]. Available: http://dx.doi.org/10.1007/ BF00268499
-
[40] S. Prabhumoye, R. Salakhutdinov, and A. W. Black, “Topological sort for sentence ordering,” in Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, D. Jurafsky, J. Chai, N. Schluter, and J. Tetreault, Eds. Online: Association for Computational Linguistics, Jul. 2020, pp. 2783–2792. [Online]. Available:https://aclanthology.org/2020.acl-main.248/
-
[41] X. Li, M. Liu, S. Gao, and W. Buntine, “A survey on out-of-distribution evaluation of neural nlp models,” in Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence, IJCAI-23, E. Elkind, Ed. International Joint Conferences on Artificial Intelligence Organization, 8 2023, pp. 6683–6691, survey Track. [Online]. Available: https://doi.org/10.24963/ijcai.2023/749
-
[42] H. Yu, J. Liu, X. Zhang, J. Wu, and P. Cui, “A survey on evaluation of out-of-distribution generalization,” 2024. [Online]. Available:https://arxiv.org/abs/2403.01874
-
[43] Y.-A. Liu, R. Zhang, J. Guo, C. Zhou, M. de Rijke, and X. Cheng, “On the robustness of generative information retrieval models: An out-of-distribution perspective,” in Advances in Information Retrieval, C. Hauff, C. Macdonald, D. Jannach, G. Kazai, F. M. Nardini, F. Pinelli, F. Silvestri, and N. Tonellotto, Eds. Cham: Springer Nature Switzerland, 2025, pp. 407–423.
-
[44] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pretraining of deep bidirectional transformers for language understanding,” in Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), 2019, pp. 4171–4186.
-
[45] T. Wolf, L. Debut, V. Sanh, J. Chaumond, C. Delangue, A. Moi, P. Cistac, T. Rault, R. Louf, M. Funtowicz, J. Davison, S. Shleifer, P. von Platen, C. Ma, Y. Jernite, J. Plu, C. Xu, T. L. Scao, S. Gugger, M. Drame, Q. Lhoest, and A. M. Rush, “Transformers: State-ofthe-art natural language processing,” in Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. Online: Association for Computational Linguistics, Oct. 2020, pp. 38–45. [Online]. Available: https: //www.aclweb.org/anthology/2020.emnlp-demos.6
-
[46] R. J. G. B. Campello, D. Moulavi, A. Zimek, and J. Sander, “Hierarchical density estimates for data clustering, visualization, and outlier detection,” ACM Trans. Knowl. Discov. Data, vol. 10, no. 1, Jul. 2015. [Online]. Available:https://doi.org/10.1145/2733381
-
[47] B. J. Frey and D. Dueck, “Clustering by passing messages between data points,” Science, vol. 315, no. 5814, pp. 972–976, 2007. [Online]. Available:https://www.science.org/doi/abs/10.1126/science.1136800
-
[48] C. M. Bishop, “Pattern recognition and machine learning,” Journal of Electronic Imaging, vol. 16, no. 4, p. 049901, 1 2007. [Online]. Available:https://doi.org/10.1117/1.2819119
-
[49] T. A. S. Foundation, “Apache spark,” 2025, version 3.1. [Online]. Available:https://spark.apache.org/
-
[50] P. Bojanowski, E. Grave, A. Joulin, and T. Mikolov, “Enriching Word Vectors with Subword Information,” Transactions of the Association for Computational Linguistics (TACL’ 17), pp. 135–146, 2017. [Online]. Available: https://doi.org/10.1162/tacl a 00051
-
[51] A. Joulin, E. Grave, P. Bojanowski, and T. Mikolov, “Bag of tricks for efficient text classification,” in Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 2, Short Papers. Association for Computational Linguistics, 2017, pp. 427–431. [Online]. Available: https://aclanthology.org/E17-2068
-
[52] R. Agrawal, A. Gupta, Y. Prabhu, and M. Varma, “Multi-label learning with millions of labels: recommending advertiser bid phrases for web pages,” in Proceedings of the 22nd International Conference on World Wide Web, ser. WWW ‘13. New York, NY, USA: Association for Computing Machinery, 2013, p. 13–24. [Online]. Available: https://doi.org/10.1145/2488388.2488391
-
[53] A. Broder, M. Fontoura, V. Josifovski, and L. Riedel, “A semantic approach to contextual advertising,” in Proceedings of the 30th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, ser. SIGIR ‘07. New York, NY, USA: Association for Computing Machinery, 2007, p. 559–566. [Online]. Available:https://doi.org/10.1145/1277741.1277837