Implicit Look Alike Modelling In Display Ads Transfer Collaborative Filtering To Ctr Estimation
Abstract. User behaviour targeting is essential in online advertising. Compared with sponsored search keyword targeting and contextual advertising page content targeting, user behaviour targeting builds users’ interest profiles via tracking their online behaviour and then delivers the relevant ads according to each user’s interest, which leads to higher targeting accuracy and thus more improved advertising performance. The current user profiling methods include building keywords and topic tags or mapping users onto a hierarchical taxonomy. However, to our knowledge, there is no previous work that explicitly investigates the user online visits similarity and incorporates such similarity into their ad response prediction. In this work, we propose a general framework which learns the user profiles based on their online browsing behaviour, and transfers the learned knowledge onto prediction of their ad response. Technically, we propose a transfer learning model based on the probabilistic latent factor graphic models, where the users’ ad response profiles are generated from their online browsing profiles. The large-scale experiments based on real-world data demonstrate significant improvement of our solution over some strong baselines.
1 Introduction
Section titled “1 Introduction”Targeting technologies have been widely adopted in various online advertising paradigms during the recent decade. According to the Internet advertising revenue report from IAB in 2014 [22], 51% online advertising budget is spent on sponsored search (search keywords targeting) and contextual advertising (page content targeting), while 39% is spent on display advertising (user demographics and behaviour targeting), and the left 10% is spent on other ad formats like classifieds. With the rise of ad exchanges [19] and mobile advertising, user behaviour targeting has now become essential in online advertising.
Compared with sponsored search or contextual advertising, user behaviour targeting explicitly builds the user profiles and detects their interest segments via tracking their online behaviour, such as browsing history, search keywords and ad clicks etc. Based on user profiles, the advertisers can detect the users with similar interests to the known customers and then deliver the relevant ads to them. Such technology is referred as look-alike modelling [17], which efficiently provides higher targeting accuracy and thus brings more customers to the advertisers [29]. The current user profiling methods include building keyword and topic distributions [1] or clustering users onto a (hierarchical) taxonomy [29]. Normally, these inferred user interest segments are then used as target restriction rules or as features leveraged in predicting users’ ad response [32].
However, the two-stage profiling-and-targeting mechanism is not optimal (despite its advantages of explainability). First, there is no flexible relationship between the inferred tags or categories. Two potentially correlated interest segments are regarded as separated and independent ones. For example, the users who like cars tend to love sports as well, but these two segments are totally separated in the user targeting system. Second, the first stage, i.e., the user interest segments building, is performed independently and with little attention of its latter use of ad response prediction [29,7], which is suboptimal. Third, the effective tag system or taxonomy structure could evolve over time, which makes it much difficult to update them.
In this paper, we propose a novel framework to implicitly and jointly learn the users’ profiles on both the general web browsing behaviours and the ad response behaviours. Specifically, (i) Instead of building explicit and fixed tag system or taxonomy, we propose to directly map each user, webpage and ad into a latent space where the shape of the mapping is automatically learned. (ii) The users’ profiles on general browsing and ad response behaviour are jointly learned based on the heterogeneous data from these two scenarios (or tasks). (iii) With a maximum a posteriori framework, the knowledge from the user browsing behaviour similarity can be naturally transferred to their ad response behaviour modelling, which in turn makes an improvement over the prediction of the users’ ad response. For instance, our model could automatically discover that the users with the common behaviour on www.bbc.co.uk/sport will tend to click automobile ads. Due to its implicit nature, we call the proposed model implicit look-alike modelling.
Comprehensive experiments on a real-world large-scale dataset from a commercial display ad platform demonstrate the effectiveness of our proposed model and its superiority over other strong baselines. Additionally, with our model, it is straightforward to analyse the relationship between different features and which features are critical and cost-effective when performing transfer learning.
2 Related Work
Section titled “2 Related Work”Ad Response Prediction aims at predicting the probability that a specific user will respond (e.g., click) to an ad in a given context [4,18]. Such context can be either a search keyword [8], webpage content [2], or other kinds of real-time information related to the underlying user [31]. From the modelling perspective, many user response prediction solutions are based on linear models, such as logistic regression [24,14] and Bayesian probit regression [8]. Despite the advantage of high learning efficiency, these linear models suffer from the lack of feature interaction and combination [9]. Thus non-linear models such as tree models [9] and latent vector models [30,20] are proposed to catch the data non-linearity and interactions between features. Recently the authors in [12] proposed to first learn combination features from gradient boosting decision trees (GBDT) and, based on the tree leaves as features, learn a factorisation machine (FM) [23] to build feature interactions to improve ad click prediction performance.
Collaborative Filtering (CF) on the other hand is a technique for personalised recommendation [26]. Instead of exploring content features, it learns the user or/and item similarity based on their interactions. Besides the user(item) based approaches [25,28], latent factor models, such as probabilistic latent semantic analysis [10], matrix factorisation [13] and factorisation machines [23], are widely used model-based approaches. The key idea of the latent factor models is to learn a low-dimensional vector representation of each user and item to catch the observed user-item interaction patterns. Such latent factors have good generalisation and can be leveraged to predict the users’ preference on unobserved items [13]. In this paper, we explore latent models of collaborative filtering to model user browsing patterns and use them to infer users’ ad click behaviour.
Transfer Learning deals with the learning problem where the learning data of the target task is expensive to get, or easily outdated, via transferring the knowledge learned from other tasks [21]. It has been proven to work on a variety of problems such as classification [6], regression [16] and collaborative filtering [15]. Different from multi-task learning, where the data from different tasks are assumed to drawn from the same distribution [27], transfer learning methods may allow for arbitrary source and target tasks. In online advertising field, the authors in a recent work [7] proposed a transfer learning scheme based on logistic regression prediction models, where the parameters of ad click prediction model were restricted with a regularisation term from the ones of user web browsing prediction model. In this paper, we consider it as one of the baselines.
3 Implicit Look-alike Modelling
Section titled “3 Implicit Look-alike Modelling”In performance-driven online advertising, we commonly have two types of observations about underlying user behaviours: one from their browsing behaviours (the interaction with webpages) and one from their ad responses, e.g., conversions or clicks, towards display ads (the interactions with the ads) [7]. There are two predictions tasks for understanding the users:
- Web Browsing Prediction (CF Task). Each user’s online browsing behaviour is logged as a list containing previously visited publishers (domains or URLs). A common task of using the data is to leverage collaborative filtering (CF) [28,23] to infer the user’s profile, which is then used to predict whether the user is interested in visiting any given new publisher. Formally, we denote the dataset for CF as Dc and an observation is denoted as (x c , yc ) ∈ Dc , where x c is a feature vector containing the attributes from the user and the publisher and y c is the binary label indicating whether the user visits the publisher or not.
- Ad Response Prediction (CTR Task). Each user’s online ad feedback behaviour is logged as a list of pairs of ad impression events and their corresponding feedbacks (e.g., click or not). The task is to build a click-through rate (CTR) prediction model [5] to estimate how likely it is that the user will
click a specific ad impression in the future. Each ad impression event consists of various information, such as user data (cookie ID, location, time, device, browser, OS etc.), publisher data (domain, URL, ad slot position etc.), and advertiser data (ad creative, creative size, campaign etc.). Mathematically, we denote the ad CTR dataset as and its data instance as , where is a feature vector and is the binary label indicating whether the user clicks a given ad or not.
This paper focuses on the latter task: ad response prediction. We, however, observe that although they are different prediction tasks, the two tasks share a large proportion of users, publishers and their features. We can thus build a user-publisher interest model jointly from the two tasks. Typically we have a large number of observations about user browsing behaviours and we can use the knowledge learned from publisher CF recommendation to help infer display advertising CTR estimation.
3.1 The Joint Conditional Likelihood
Section titled “3.1 The Joint Conditional Likelihood”In our solution, the prediction models on CF task and CTR task are learned jointly. Specifically, we build a joint data discrimination framework. We denote as the parameter set of the joint model with prior , and the conditional likelihood of an observed data instance is the probability of predicting the correct binary label given the features . As such, the conditional likelihood of the two datasets are and . Maximising a posteriori (MAP) estimation gives
(1)
Just like most solutions on CF recommendation [13,10] and CTR estimation [24,14], in this discriminative framework, is only concerned with the mapping from the features to the labels (the conditional probabilities) rather than modelling the prior distribution of features [11].
The details of the conditional likelihood , and the parameter prior will be discussed in the latter subsections.
3.2 CF Prediction
Section titled “3.2 CF Prediction”For the CF task, we use a factorisation machine [23] as our prediction model. We further define the features , where is the set of features for a user and is the set of features for a publisher1. The parameter , where is the global bias term and is the weight vector of the -dimensional user features and -dimensional publisher features. Each user feature or publisher feature is associated with a K-dimensional latent vector or . Thus .
All the features studied in our work are one-hot encoded binary features.
With such setting, the conditional probability for CF in Eq. (1) can be reformulated as:
(2)
Let be the predicted probability of whether user u will be interested in visiting publisher p. With the FM model, the likelihood of observing the label given the features and parameters is
P(y^{c}|\boldsymbol{x}^{u},\boldsymbol{x}^{p};w_{0}^{c},\boldsymbol{w}^{c},\boldsymbol{V}^{c}) = (\hat{y}_{u,p}^{c})^{y^{c}} \cdot (1 - \hat{y}_{u,p}^{c})^{(1-y^{c})}, \tag{3}
where the prediction is given by an FM with a logistic function:
\hat{y}_{u,p}^{c} = \sigma \left( w_0^c + \sum_i w_i^c x_i^u + \sum_j w_j^c x_j^p + \sum_i \sum_j \langle \boldsymbol{v}_i^c, \boldsymbol{v}_j^c \rangle x_i^u x_j^p \right), \tag{4}
where is the sigmoid function and is the inner product of two vectors: , which models the interaction between a user feature i and a publisher feature j.
3.3 CTR Task Prediction Model
Section titled “3.3 CTR Task Prediction Model”For a data instance in ad CTR task dataset , its features can be divided into three categories: the user features (cookie, location, time, device, browser, OS, etc.), the publisher features (domain, URL etc.), and the ad features (ad slot position, ad creative, creative size, campaign, etc.). Each feature has potential influence to another one in a different category. For example, a mobile phone user might prefer square-sized ads instead of banner ads; users would like to click the ad on the sport websites during the afternoon etc.
By the same token as CF prediction, we leverage factorisation machine and the model parameter thus is . Specifically, is one of the -dimensional ad features is the corresponding bias weight for the feature, and the feature is also associated with a K-dimensional latent vector . Thus . Similar to CF task, the CTR data likelihood is:
(5)
Then the factorisation machine with logistic activation function is adopted to model the click probability over a specific ad impression:
(6)
where is modelled by interactions among 3-side features
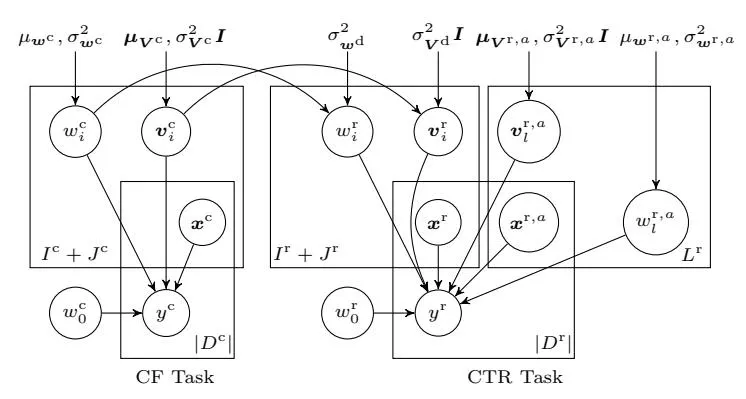
Fig. 1. Graphic model of transferred factorisation machines.
3.4 Dual-Task Bridge
Section titled “3.4 Dual-Task Bridge”To model the dependency between the two tasks, the weights of the user features and publisher features in CTR task are assumed to be generated from the counterparts in CF task (as a prior):
(8)
where is the assumed variance of the Gaussian generation process between each pair of feature weights of CF and CTR tasks and the weight generation is assumed to be independent across features. Similarly, the latent vectors of CTR task are assumed to be generated from the counterparts of CF task:
(9)
where i is the index of a user or publisher feature; is defined similarly.
The rational behind the above bridging model is that the users’ interest towards webpage content is relatively general and the displayed ad can be regarded as a special kind of webpage content. One can infer user interests from their browsing behaviours, while their interests on commercial ads can be regarded as a modification or derivative from the learned general interests.
The graphic representation for the proposed transferred factorisation machines is depicted in Figure 1. It illustrates the relationship among model parameters and observed data. The left part is for the CF task: , , and work together to infer our CF task target , i.e., whether the user would visit a specific publisher or not. The right part illustrates the CTR task. Corresponding to CF task, and here represent user and publisher features’ weights and latent vectors, while and are separately depicted to represent ad features’ weights and latent vectors. All these factors work together to predict CTR task target , i.e., whether the user would click the ad or not. On top of that, for each (user or publisher) feature i of the CF task, its weight and latent vector act as a prior of the counterparts and in CTR task while learning the model.
Considering the datasets of the two tasks might be seriously unbalanced, we choose to focus on the averaged log-likelihood of generating each data instance
from the two tasks. In addition, we add a hyperparameter for balancing the task relative importance. As such, the joint conditional likelihood in Eq. (1) is written as
(10)
and its log form is
+ \frac{1 - \alpha}{|D^{r}|} \sum_{(\boldsymbol{x}^{r}, y^{r}) \in D^{r}} \left[ y^{r} \log \hat{y}_{u,p,a}^{r} + (1 - y^{r}) \log(1 - \hat{y}_{u,p,a}^{r}) \right].$$ (11) Moreover, from the graphic model, the prior of model parameters can be specified as $$P(\Theta) = P(\boldsymbol{w}^{c})P(\boldsymbol{V}^{c})P(\boldsymbol{w}^{r}|\boldsymbol{w}^{c})P(\boldsymbol{V}^{r}|\boldsymbol{V}^{c})P(\boldsymbol{w}^{r,a})P(\boldsymbol{V}^{r,a})$$ (12) $$\log P(\Theta) = \sum_{i} \log \mathcal{N}(w_{i}^{c}; \mu_{\boldsymbol{w}^{c}}, \sigma_{\boldsymbol{w}^{c}}^{2}) + \sum_{i} \log \mathcal{N}(\boldsymbol{v}_{i}^{c}; \boldsymbol{\mu_{\boldsymbol{V}^{c}}}, \sigma_{\boldsymbol{V}^{c}}^{2}\boldsymbol{I})$$ $$+ \sum_{i} \log \mathcal{N}(w_{i}^{r}; w_{i}^{c}, \sigma_{\boldsymbol{w}^{d}}^{2}) + \sum_{i} \log \mathcal{N}(\boldsymbol{v}_{i}^{r}; \boldsymbol{v}_{i}^{c}, \sigma_{\boldsymbol{V}^{d}}^{2}\boldsymbol{I})$$ (13) $$+ \sum_{i} \log \mathcal{N}(w_{l}^{r,a}; \mu_{\boldsymbol{w}^{r,a}}, \sigma_{\boldsymbol{w}^{r,a}}^{2}) + \sum_{l} \log \mathcal{N}(\boldsymbol{v}_{l}^{r,a}; \boldsymbol{\mu_{\boldsymbol{V}^{r,a}}}, \sigma_{\boldsymbol{V}^{r,a}}^{2}\boldsymbol{I}).$$ ### 3.5 Learning the Model Given the detailed implementations of the MAP solution (Eq. (1)) components in Eqs. (11) and (13), for each data instance (x, y), the gradient update of $\Theta$ is <span id="page-6-1"></span> $$\Theta \leftarrow \Theta + \eta \left( \beta \frac{\partial}{\partial \Theta} \log P(y|\boldsymbol{x}; \Theta) + \frac{\partial}{\partial \Theta} \log P(\Theta) \right), \tag{14}$$ where $P(y|\mathbf{x}; \Theta)$ is as Eqs. (3) and (6) for $(\mathbf{x}^c, y^c) \in D^c$ and $(\mathbf{x}^r, y^r) \in D^r$ , respectively; $\eta$ is the learning rate; $\beta$ is the instance weight parameter depending on which task the instance belongs to, as given in Eq. (11). The detailed gradient for each specific parameter can be calculated routinely and thus are omitted here due to the page limit. ### 4 Experiments ### 4.1 Dataset Our experiments are conducted based on a real-world dataset provided by Adform, a global digital media advertising technology company based in Copenhagen, Denmark. It consists of two weeks of online display ad logs across different campaigns during March 2015. Specifically, there are 42.1M user domain browsing events and 154.0K ad display/click events. To fit the data into the joint model, we group useful data features into three categories: user features x u (user cookie, hour, browser, os, user agent and screen size), publisher features x p (domain, url, exchange, ad slot and slot size), ad features x a (advertiser and campaign). Detailed unique value numbers for each attribute are given as below. | | Attribute user cookie | hour | browser | os | user agent | screen size | domain | |---------------|-----------------------|------|---------|----|-----------------------------------|-------------|--------| | Unique number | 4,180,170 | 24 | 71 | 37 | 29,488 | 118 | 38,495 | | Attribute | url | | | | exchange position size advertiser | campaign | | | Unique number | 1,100,523 | 140 | 3 | 55 | 486 | 2,665 | | In order to perform stable knowledge transfer, we have down-sampled the negative instances to make the ratio of positive over negative instances as 1:5.[2](#page-7-0) ### 4.2 Experiment Protocol We conduct a two-stage experiment to verify the effectiveness of our proposed models. First, in a very clean setting, we only focus on user cookie and domain to check whether the knowledge of users' behaviour on webpage browsing can be transferred to model their behaviour on clicking the ads in these webpages. Second, we start to append various features in the first setting to observe the performance change and check which features lead to better transfer learning. Specifically, we try appending a single side feature into the baseline setting: 1. appending user feature x u , 2. appending publisher feature x p , 3. appending ad feature x a . Finally, all features are added into the model to perform the transfer learning. For each experiment stage, there are three datasets: CF dataset (D<sup>c</sup> ), CTR dataset (D<sup>r</sup> ) and Joint dataset (D<sup>c</sup> , D<sup>r</sup> ). Each dataset is split into two parts: the first week data as training data and the second one as test data. ### 4.3 Evaluation Metrics To evaluate the performance of proposed model, area under the ROC curve (AUC) [\[8\]](#page-10-3) and root mean square error (RMSE) [\[13\]](#page-11-16) are adopted as performance metrics. As we focus on ad click prediction performance improvement, we only report the performance of the CTR estimation task. #### 4.4 Compared Models We implement the following models for experimental comparison. – Base: This baseline model only considers the ad CTR task, without any transfer learning. The parameters are learned by max<sup>Θ</sup> Q (x<sup>r</sup> ,yr)∈D<sup>r</sup> P(y r |x r ; Θ)P(Θ). <span id="page-7-0"></span><sup>2</sup> It is common to perform negative down sampling to balance the labels in ad CTR estimation [\[9\]](#page-10-5). Calibration methods [\[3\]](#page-10-9) are then leveraged to eliminate the model bias.  <span id="page-8-2"></span>Fig. 2. Performance improvement with basic setting - Disjoint: This method performs a knowledge transfer in a disjoint two-stage fashion. First, we train the CF task model to get the parameters $\boldsymbol{w}^{c}$ and $\boldsymbol{V}^{c}$ by $\max_{\boldsymbol{\Theta}} \prod_{(\boldsymbol{x}^{c}, y^{c}) \in D^{c}} P(y^{c} | \boldsymbol{x}^{c}; \boldsymbol{\Theta}) P(\boldsymbol{\Theta})$ . Second, with the CF task parameters fixed, we train the CTR task using Eqs. (11) and (13). Note that $\alpha$ in Eq. (11) is still a hyperparameter for this method. - DisjointLR: The transfer learning model proposed in [7] is considered as state-of-the-art transfer learning methods in display advertising. In this work, both source and target tasks adopt logistic regression as a behaviour prediction model, which uses the linear model to minimise the logistic loss from each observation sample: <span id="page-8-1"></span><span id="page-8-0"></span> $$\mathcal{L}_{\boldsymbol{w}}(\boldsymbol{x}, y) = -y \log \sigma(\langle \boldsymbol{w}, \boldsymbol{x} \rangle) - (1 - y) \log(1 - \sigma(\langle \boldsymbol{w}, \boldsymbol{x} \rangle)). \tag{15}$$ In our context of regarding the CF task as source task and CTR task as target task, the learning objectives are listed below: CF TASK: $$\mathbf{w}^{c} = \arg\min_{\mathbf{w}^{c}} \sum_{(\mathbf{x}^{c}, y^{c}) \in D^{c}} \mathcal{L}_{\mathbf{w}^{c}}(\mathbf{x}^{c}, y^{c}) + \lambda ||\mathbf{w}^{c}||_{2}^{2}$$ (16) $$\text{CTR TASK}: \overset{*}{\boldsymbol{w}^{r}} = \arg\min_{\boldsymbol{w}^{r}} \sum_{(\boldsymbol{x}^{r}, y^{r}) \in D^{r}} \mathcal{L}_{\boldsymbol{w}^{r}}(\boldsymbol{x}^{r}, y^{r}) + \lambda ||\boldsymbol{w}^{r} - \overset{*}{\boldsymbol{w}^{c}}||_{2}^{2}.$$ (17) Besides the difference between the linear LR and non-linear FM, this method is a two-stage learning scheme, where the first stage Eq. (16) is disjoint with the second stage Eq. (17). Thus we denoted it as DisjointLR. - Joint: Our proposed model, as summarised in Eq. (1), which performs the transfer learning when jointly learning the parameters on the two tasks. ### 4.5 Result Basic Setting Performance. Figure 2 presents the AUC and RMSE performance of Base, Disjoint and Joint and the improvement of Joint against the hyperparameter $\alpha$ in Eq. (11) based on the basic experiment setting. As can be observed clearly, for a large region of $\alpha$ , i.e., [0.1,0.7], Joint consistently outperforms the baselines Base and Disjoint on both AUC and RMSE, which demonstrates the effectiveness of our model to transfer knowledge from webpage browsing data to ad click data. Note that when $\alpha = 0$ , the CF side model $\boldsymbol{w}^c$ does not learn but Joint still outperforms Disjoint and Base. This is due to the different prior of $\boldsymbol{w}^r$ and $\boldsymbol{V}^r$ in Joint compared with those of Disjoint and Base. Table 1. Overall AUC performance: DisjointLR vs Joint. <span id="page-9-0"></span> <span id="page-9-1"></span>Table 2. CTR task performance | | Joint vs Disjoint | | | | Joint vs Base | | | | | |------------------------------------------------|---------------------|-------|--------|----------|---------------------|--------|--------|--------|--| | | $\overset{*}{lpha}$ | AUC | Joint | Disjoint | $\overset{*}{lpha}$ | AUC | Joint | Base | | | | | Lift | AUC | AUC | | Lift | AUC | AUC(%) | | | Basic Setting | 0.5 | 3.43% | 72.18% | 68.75% | 0.2 | 1.41% | 72.24% | 70.83% | | | $+ \boldsymbol{x}^u$ : hour | 0.8 | 2.44% | 89.35% | 86.91% | 0.6 | 1.99% | 89.35% | 87.36% | | | $+ ~m{x}^u$ : browser | 0.0 | 7.92% | 76.36% | 68.44% | 0.2 | 8.08% | 76.52% | 68.44% | | | $+ \ oldsymbol{x}^u$ : os | 0.1 | 6.66% | 76.86% | 70.2% | 0.1 | 6.71% | 76.86% | 70.15% | | | $+ \ m{x}^u$ : user_agent | 0.0 | 2.57% | 67.12% | 64.55% | 8.0 | 4.31% | 68.86% | 64.55% | | | $+ \ m{x}^u$ : screen_size | 0.0 | 9.39% | 76.43% | 67.04% | 0.0 | 9.39% | 76.43% | 67.04% | | | $+ \ m{x}^p$ : exchange | 0.6 | 1.56% | 66.80% | 65.24% | 0.0 | 0.64% | 68.49% | 67.85% | | | $+ \ m{x}^p \colon \mathtt{url}$ | 0.3 | 11.9% | 66.56% | 54.66% | 0.0 | 11.55% | 69.36% | 57.81% | | | $+ \; oldsymbol{x}^p \colon \mathtt{position}$ | 0.6 | 2.63% | 66.89% | 64.26% | 0.4 | 0.69% | 67.14% | 66.45% | | | $+ \ m{x}^a$ : advertiser | 0.4 | 2.39% | 84.98% | 82.59% | 0.5 | 0.87% | 85.07% | 84.20% | | | $+ \; oldsymbol{x}^a$ : campaign | 0.2 | 1.29% | 85.81% | 84.52% | 0.1 | 0.48% | 85.91% | 85.43% | | | $+ \; oldsymbol{x}^a \colon \mathtt{size}$ | 0.0 | 0.59% | 69.16% | 68.57% | 0.0 | 0.59% | 69.16% | 68.57% | | | + ALL FEATURES | 0.5 | 6.91% | 88.32% | 81.41% | 0.6 | 6.91% | 88.32% | 81.41% | | In addition, when $\alpha = 1$ , i.e., no learning on CTR task, the performance of Joint reasonably gets back to initial guess, i.e., both AUC and RMSE are 0.5. Table 1 shows the transfer learning performance comparison between Joint and the state-of-the-art DisjointLR with both models setting optimal hyperparameters. The improvement of Joint over DisjointLR indicates the success of 1) the joint optimisation on the two tasks to perform knowledge transfer and 2) the non-linear factorisation machine relevance model on catching feature interactions Appending Side Information Performance. From the Joint model as in Eq. (11) we see when $\alpha$ is large, e.g., 0.8, the larger weight is allocated on the CF task to optimise the joint likelihood. As such, if a large-value $\alpha$ leads to the optimal CTR estimation performance, it means the transfer learning takes effect. With such method, we try adding different features into the Joint model to obtain the optimal hyperparameter $\alpha$ leading to the highest AUC to check whether a certain feature helps transfer learning. On the contrary, if a low-value or 0 $\alpha$ leads to the optimal performance of Joint model when adding a certain feature, it means such feature has no effect of performing transfer learning. Table 2 collects the AUC improvement of the Joint model for the conducted experiments. We observe that user browsing hour, ad slot position in the webpage are the most valuable features that help transfer learning, while the user screen size does not bring any transfer value. When adding all these features into Joint model, the optimal $\alpha$ is around 0.5 for AUC improvement and 0.6 for RMSE drop (see Figure 3), which means these features along with the basic user, webpage IDs provide an overall positive value of knowledge transfer from webpage browsing behaviour to ad click behaviour. #### 5 Conclusion In this paper, we proposed a transfer learning framework with factorisation machines to build implicit look-alike models on user ad click behaviour prediction  <span id="page-10-10"></span>Fig. 3. Performance improvement with different side information. task with the knowledge successfully transferred from the rich data of user webpage browsing behaviour. The major novelty of this work lies in the joint training on the two tasks and making knowledge transfer based on the non-linear factorisation machine model to build the user and other feature profiles. Comprehensive experiments on a large-scale real-world dataset demonstrated the effectiveness of our model as well as some insights of detecting which specific features help transfer learning. In the future work, we plan to explore on the user profiling utilisation based on the learned latent vector for each user. We also plan to extend our model to cross-domain recommendation problems. # Acknowledgement We would like to thank Adform for allowing us to use their data in experiments. We would also like to thank Thomas Furmston for his feedback on the paper. Weinan thanks Chinese Scholarship Council for the research support. # References - <span id="page-10-0"></span>1. Ahmed, A., Low, Y., Aly, M., Josifovski, V., Smola, A.J.: Scalable distributed inference of dynamic user interests for behavioral targeting. In: KDD (2011) - <span id="page-10-4"></span>2. Broder, A., Fontoura, M., Josifovski, V., Riedel, L.: A semantic approach to contextual advertising. In: SIGIR. pp. 559–566. ACM (2007) - <span id="page-10-9"></span>3. Caruana, R., Niculescu-Mizil, A.: An empirical comparison of supervised learning algorithms. In: ICML. pp. 161–168. ACM (2006) - <span id="page-10-2"></span>4. Chapelle, O.: Modeling delayed feedback in display advertising. In: KDD. pp. 1097– 1105. ACM (2014) - <span id="page-10-8"></span>5. Chapelle, O., et al.: A simple and scalable response prediction for display advertising (2013) - <span id="page-10-7"></span>6. Dai, W., Xue, G.R., Yang, Q., Yu, Y.: Transferring naive bayes classifiers for text classification. In: AAAI (2007) - <span id="page-10-1"></span>7. Dalessandro, B., Chen, D., Raeder, T., Perlich, C., Han Williams, M., Provost, F.: Scalable hands-free transfer learning for online advertising. In: KDD (2014) - <span id="page-10-3"></span>8. Graepel, T., Candela, J.Q., Borchert, T., Herbrich, R.: Web-scale bayesian clickthrough rate prediction for sponsored search advertising in microsoft's bing search engine. In: ICML. pp. 13–20 (2010) - <span id="page-10-5"></span>9. He, X., Pan, J., Jin, O., Xu, T., Liu, B., Xu, T., Shi, Y., Atallah, A., Herbrich, R., Bowers, S., et al.: Practical lessons from predicting clicks on ads at facebook. In: ADKDD. pp. 1–9. ACM (2014) - <span id="page-10-6"></span>10. Hofmann, T.: Collaborative filtering via gaussian probabilistic latent semantic analysis. In: SIGIR. pp. 259–266. ACM (2003) - <span id="page-11-21"></span>11. Jebara, T.: Machine learning: discriminative and generative, vol. 755. Springer Science & Business Media (2012) - <span id="page-11-11"></span>12. Juan, Y.C., Zhuang, Y., Chin, W.S.: 3 idiots approach for display advertising challenge. In: Internet and Network Economics, pp. 254–265. Springer (2011) - <span id="page-11-16"></span><span id="page-11-8"></span>13. Koren, Y., Bell, R., Volinsky, C.: Matrix factorization techniques for recommender systems. Computer (8), 30–37 (2009) - 14. Lee, K.c., Orten, B., Dasdan, A., Li, W.: Estimating conversion rate in display advertising from past performance data. In: KDD. pp. 768–776. ACM (2012) - <span id="page-11-19"></span>15. Li, B., Yang, Q., Xue, X.: Transfer learning for collaborative filtering via a ratingmatrix generative model. In: ICML. pp. 617–624. ACM (2009) - <span id="page-11-18"></span>16. Liao, X., Xue, Y., Carin, L.: Logistic regression with an auxiliary data source. In: ICML. pp. 505–512. ACM (2005) - <span id="page-11-2"></span>17. Mangalampalli, A., Ratnaparkhi, A., Hatch, A.O., Bagherjeiran, A., Parekh, R., Pudi, V.: A feature-pair-based associative classification approach to look-alike modeling for conversion-oriented user-targeting in tail campaigns. In: WWW. pp. 85–86. ACM (2011) - <span id="page-11-5"></span>18. McAfee, R.P.: The design of advertising exchanges. Review of Industrial Organization 39(3), 169–185 (2011) - <span id="page-11-1"></span>19. Muthukrishnan, S.: Ad exchanges: Research issues. In: Internet and network economics, pp. 1–12. Springer (2009) - <span id="page-11-10"></span>20. Oentaryo, R.J., Lim, E.P., Low, D.J.W., Lo, D., Finegold, M.: Predicting response in mobile advertising with hierarchical importance-aware factorization machine. In: WSDM (2014) - <span id="page-11-17"></span>21. Pan, S.J., Yang, Q.: A survey on transfer learning. Knowledge and Data Engineering, IEEE Transactions on 22(10), 1345–1359 (2010) - <span id="page-11-0"></span>22. PricewaterhouseCoopers: IAB internet advertising revenue report. [http://www.iab.net/media/file/PwC\\_IAB\\_Webinar\\_Presentation\\_HY2014.pdf](http://www.iab.net/media/file/PwC_IAB_Webinar_Presentation_HY2014.pdf) (2014), accessed: 2015-07-29 - <span id="page-11-12"></span><span id="page-11-7"></span>23. Rendle, S.: Factorization machines. In: ICDM. pp. 995–1000. IEEE (2010) - 24. Richardson, M., Dominowska, E., Ragno, R.: Predicting clicks: estimating the clickthrough rate for new ads. In: WWW. pp. 521–530. ACM (2007) - <span id="page-11-14"></span>25. Sarwar, B., Karypis, G., Konstan, J., Riedl, J.: Item-based collaborative filtering recommendation algorithms. In: WWW. pp. 285–295. ACM (2001) - <span id="page-11-13"></span>26. Schafer, J.B., Frankowski, D., Herlocker, J., Sen, S.: Collaborative filtering recommender systems. In: The adaptive web, pp. 291–324. Springer (2007) - <span id="page-11-20"></span>27. Taylor, M.E., Stone, P.: Transfer learning for reinforcement learning domains: A survey. J. Mach. Learn. Res. 10, 1633–1685 (Dec 2009) - <span id="page-11-15"></span>28. Wang, J., De Vries, A.P., Reinders, M.J.: Unifying user-based and item-based collaborative filtering approaches by similarity fusion. In: SIGIR (2006) - <span id="page-11-3"></span>29. Yan, J., Liu, N., Wang, G., Zhang, W., Jiang, Y., Chen, Z.: How much can behavioral targeting help online advertising? In: WWW. pp. 261–270. ACM (2009) - <span id="page-11-9"></span>30. Yan, L., Li, W.J., Xue, G.R., Han, D.: Coupled group lasso for web-scale ctr prediction in display advertising. In: ICML. pp. 802–810 (2014) - <span id="page-11-6"></span>31. Yuan, S., Wang, J., Zhao, X.: Real-time bidding for online advertising: measurement and analysis. In: ADKDD. p. 3. ACM (2013) - <span id="page-11-4"></span>32. Zhang, W., Yuan, S., Wang, J.: Real-time bidding benchmarking with ipinyou dataset. arXiv preprint arXiv:1407.7073 (2014)