Keyword Decisions In Sponsored Search Advertising
Keyword Decisions in Sponsored Search Advertising: A Literature Review
Abstract. In sponsored search advertising (SSA), keywords serve as the basic unit of business model, linking three stakeholders: consumers, advertisers and search engines. This paper presents an overarching framework for keyword decisions that highlights the touchpoints in search advertising management, including four levels of keyword decisions, i.e., domain-specific keyword pool generation, keyword targeting, keyword assignment and grouping, and keyword adjustment. Using this framework, we review the state-of-the-art research literature on keyword decisions with respect to techniques, input features and evaluation metrics. Finally, we discuss evolving issues and identify potential gaps that exist in the literature and outline novel research perspectives for future exploration.
Keyword: keyword decisions, sponsored search advertising, keyword generation, keyword targeting,
1. Introduction
Section titled “1. Introduction”Sponsored search advertising (SSA) has become one of the most successful business models of online advertising. Millions of advertisers spent a large amount of advertising budgets in SSA to promote their products and services (Yang et al., 2018). According to a recent IAB report (Interactive Advertising Bureau, 2022), in the United States alone, the annual internet advertising revenue of 2021 reached $189.3 billion where SSA accounts for around 41.4% of that pie.
In SSA, firms need to choose suitable keywords to describe their products or services efficiently, and organize these keywords following certain advertising structures (e.g., account, ad-campaign, and ad-group) defined by major search engines. Once a user submits a query to a search engine which is related to one or several of these keywords, it triggers an auction process that determines which advertisements and their rankings to be displayed on search engine result pages (SERPs), together with a set of organic search results. In the SSA ecosystem, keywords are the unique carriers connecting advertisers, potential consumers, and search engines. Moreover, keywords are the basic units for advertisers to conduct online market research, design and evaluate marketing strategies. Keywords play a crucially important role in business competition for companies in online platforms. In practice, advertisers have to make various keyword decisions throughout the entire lifecycle of SSA campaigns (Yang et al., 2019). Therefore, it becomes a critical issue for search advertisers to make a series of effective keyword decisions in SSA.
Since the advent of SSA, keyword decisions have increasingly attracted research interests from both academia and industries. As far as we knew, on one hand, it is apparent that there are no commonly agreed definitions for related concepts identified in the extant literature on keyword decisions; on the other hand, prior research on keyword decisions has been conducted either separately on an individual keyword decision or without consideration of search advertising structures. There is a need for developing an integrated review of the state-of-the-art knowledge about keyword decisions in SSA. Our objectives for this paper are to examine what has been done in the literature on keyword decisions, uncover the potential gaps, and figure out novel research perspectives for future exploration.
This review complements recent review articles on online advertising and advertising selection. Ha (2008) conducted a review of online advertising published in major advertising journals from 1996 to 2007, which focuses on analyzing conceptual foundations, theories, and state-of-the-art practices of online advertising. Shatnawi & Mohamed (2012) presented an overview of online advertising selection, which focuses on investigating existing approaches, comparing and classifying these approaches. Our review focuses on keyword decisions in SSA from the system perspective, by taking into account search advertising structures and the entire lifecycle of advertising campaigns.
The contribution of our review can be summarized in the following ways. First, to the best of our knowledge, this review is the first effort focusing on keyword decisions in SSA, which has not been systematically explored before. We present an overarching framework for keyword decisions based on practical decision scenarios throughout the entire lifecycle of SSA campaigns, and conduct a systematic review of the state-of-the-art literature with respect to techniques, input features and evaluation metrics. Second, we find that a lot of practical issues remain unaddressed in this field, although plenty of research efforts have been involved in the last two decades. In particular, few research efforts reported on practical keyword decisions such as keyword targeting, keyword assignment and grouping, and keyword adjustment. In addition, our review will provide foundations for continuing studies on keyword decisions in SSA and other advertising forms.
2. Survey Scope and Structure
Section titled “2. Survey Scope and Structure”2.1 Survey Scope
Section titled “2.1 Survey Scope”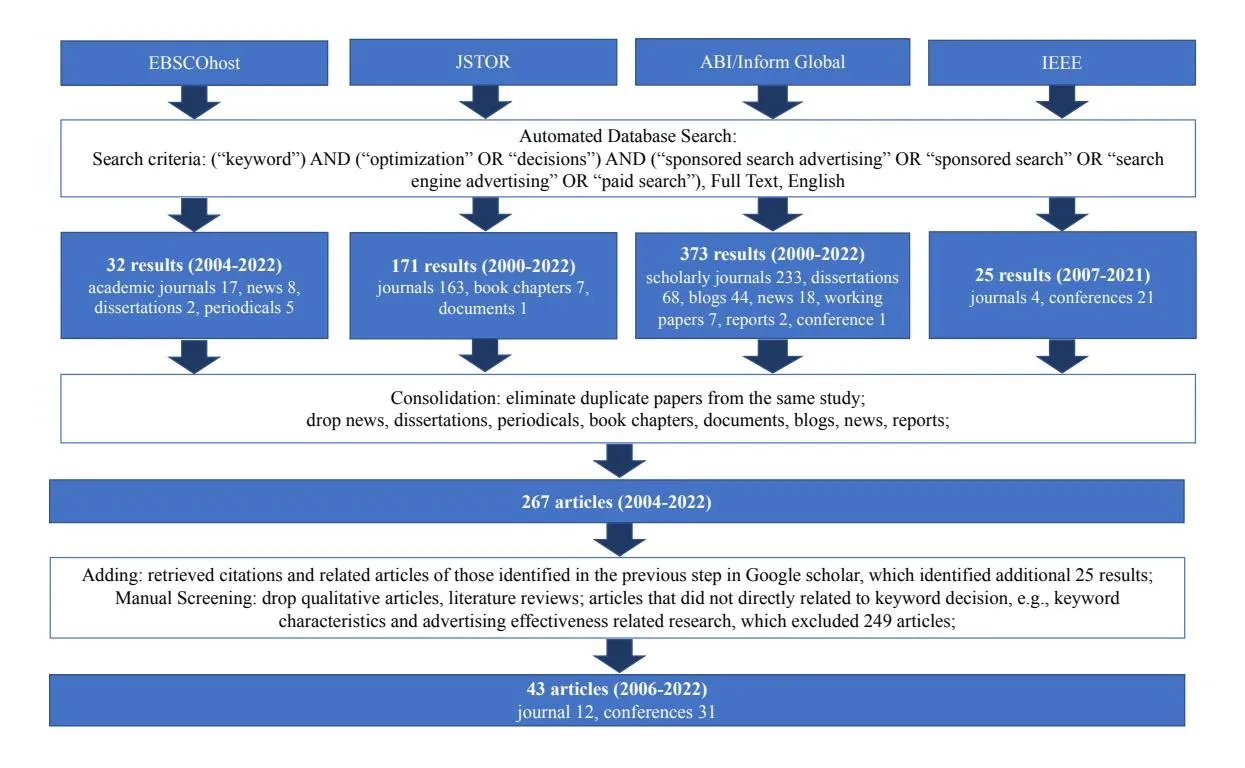 Figure 1. Study Search and Selection
Figure 1. Study Search and Selection
Due to the interdisciplinary nature of keyword decisions topics, research articles covered in this review were published in major IT-oriented (e.g., computer science, artificial intelligence and information retrieval) and/or business-oriented (e.g., management information systems, advertising and marketing) journals and conferences. Our review includes articles retrieved mainly from four academic databases: EBSCOhost, JSTOR, ABI-Inform and IEEE using full text search of (“keyword”) AND (“optimization” OR “decisions”) AND (“sponsored search advertising” OR “sponsored search” OR “search engine advertising” OR “paid search”). We restricted our selected studies in English. The search resulted in 32 results from EBSCOhost, 171 results from JSTOR, 373 results from ABI/Inform Global and 25 results from IEEE. We manually screened the results to eliminate duplicate articles, news, dissertations, periodicals, book chapters, documents, blogs, news and reports. This process led to 267 articles. Moreover, we expanded the literature by retrieving citations of the articles obtained in the previous step in Google scholar, which yielded additional 25 results. Furthermore, we dropped qualitative articles, literature reviews and empirical articles on keyword research, by going through title, abstract, full-text of each article, which excluded 249 articles. Finally, this literature search resulted in a selection of 43 research publications, including 12 peer-reviewed journal articles and 31 conference articles, covering the period from 2006 to 2022. Our search process is illustrated in Fig. 1.
2.2 Survey Structure
Section titled “2.2 Survey Structure”In SSA, a general advertising structure employed by major search engines (e.g., Google, Bing) can be described as: under a SSA account of an advertiser, there are one or several campaigns that are run simultaneously in order to fulfill a promotional goal; in the meanwhile, one or several ad-groups comprise a campaign, and each ad-group consists of one or more ad-copies and a set of keywords. Fig. 2 presents an illustration of the search advertising structure. In this sense, SSA is essentially distinct from traditional advertising (e.g., print ads and TV ads) due to its hierarchical advertising structure. Thus, advertising decisions in SSA are essentially structured, rather than flatted as in traditional advertising (Yang et al., 2012, 2019).
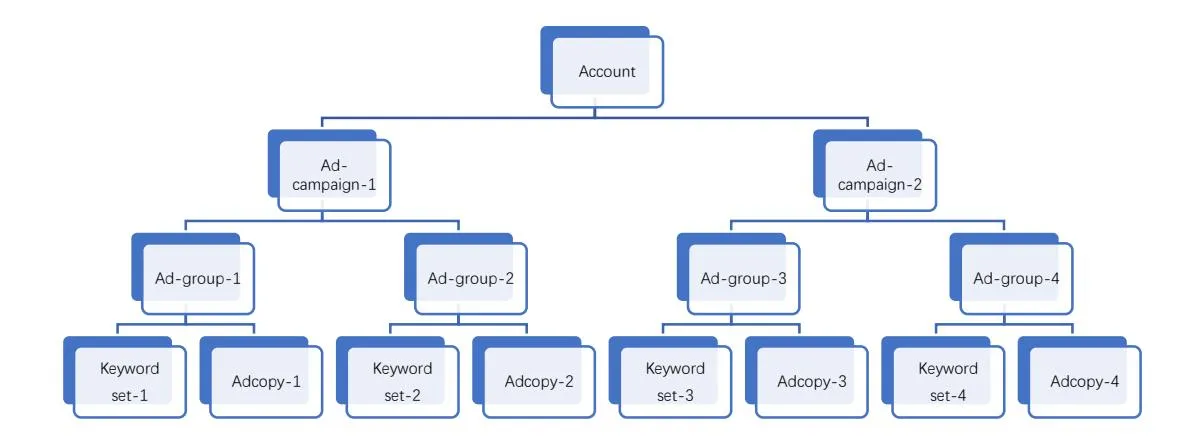
Figure 2. An Illustration of Sponsored Search Advertising Structure
Throughout the entire lifecycle of SSA campaigns, advertisers have to make a series of keyword related decisions at different levels, namely keyword generation at the domain level, keyword targeting at the market level, keyword assignment and grouping at the campaign and ad-group level, and dynamical keyword adjustment, forming a closed-loop decision cycle (Yang et al., 2019). In thisreview, we organize the extant literature on keyword decisions within a research framework, as presented in Fig. 3.
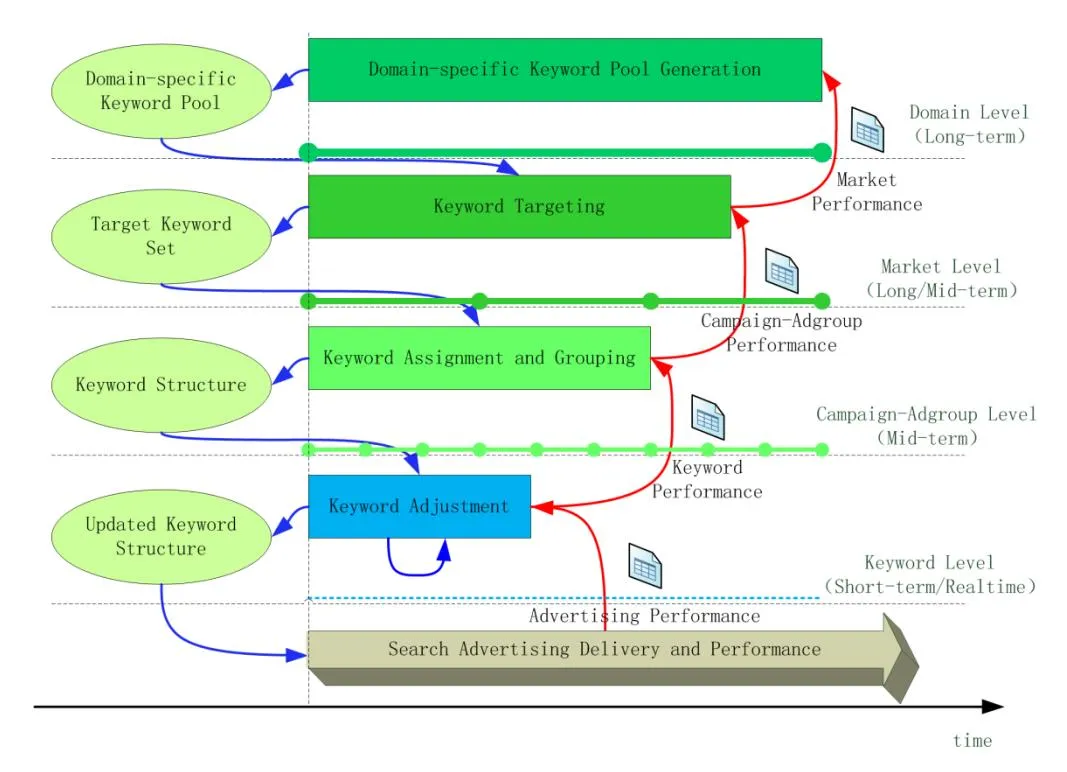
Figure 3. The Framework of Our Literature Review on Keyword Decisions
Section 3 centers on keyword generation, which is also known as the domain-level keyword optimization, aiming to generate a domain-specific keyword pool. In this section, after defining the keyword generation problem, we go over techniques, features and evaluation metrics used in the literature on keyword generation.
Section 4 discusses keyword targeting, which is also known as the market-level keyword optimization, aiming to obtain a more targeted set of keywords from the domain-specific keyword pool and choose appropriate match types for selected keywords in order to reach the right population of potential consumers. In this section, we first define the keyword targeting problem, and then review techniques, features and evaluation metrics for keyword selection and keyword match.
Section 5 focuses on keyword assignment and grouping, which is also known as the campaign and ad-group level keyword optimization, aiming to yield an effective keyword structure by following the advertising structure of SSA. In this section, we first define the problem of keyword assignment and grouping, and then introduce techniques, features and evaluation metrics used in this area.
Section 6 concerns keyword adjustment, i.e., advertisers have to dynamically adjust their keyword structures and associated strategies according to the realtime advertising performance of SSA campaigns. In this section, we first define the keyword adjustment problem in more detail, and then we discuss the status of this area.
Section 7 summarizes the state-of-the-art keyword decisions, uncovers the gaps that exist in the literature, and suggests promising research perspectives for future exploration. Finally, we conclude our review in Section 8.
Notations used in problem definitions for keyword decisions are presented in Table 1.
Table 1. Notations in problem definitions for keyword decisions
| Terms | Definition |
|---|---|
| (𝐺𝑁𝑇) 𝑓 | The keyword generation function |
| (𝐺𝑁𝑇) 𝑆 | Information source for keyword generation |
| (𝐺𝑁𝑇) 𝐾 | A set of generated keywords |
| 𝑘𝑖 | The 𝑖-th keyword in a set |
| (𝐺𝑁𝑇) 𝑛 | The number of generated keywords |
| (𝑇𝐺𝑇) 𝑓 | The keyword targeting function |
| (𝑇𝐺𝑇) 𝑛 | The number of targeting keywords |
| (𝑇𝐺𝑇) 𝐾 | A set of selected keywords |
| (𝑇𝐺𝑇) 𝑥𝑖,𝑚̅ | A binary decision variable of keyword targeting, indicating whether the 𝑖-th |
| keyword in match type 𝑚̅ is selected | |
| 𝑚̅ | Keyword match type |
| (𝐴𝑆𝑀) 𝑓 | The keyword assignment function |
| (𝐴𝑆𝑀) 𝐾𝑗 | A set of keywords assigned to the 𝑗-th campaign |
| A binary decision variable of keyword assignment, indicating whether the 𝑖-th | |||
|---|---|---|---|
| (𝐴𝑆𝑀) 𝑥𝑖,𝑗 | keyword is assigned to the 𝑗-th campaign | ||
| 𝑛𝑐𝑎𝑚𝑝𝑎𝑖𝑔𝑛 | The number of ad campaigns | ||
| (𝐺𝑅𝑃) 𝑓 | The keyword grouping function | ||
| (𝐺𝑅𝑃) 𝐾𝑗,𝑙 | A set of keywords for the 𝑙-th ad-group of the 𝑗-th campaign | ||
| (𝐺𝑅𝑃) | A binary decision variable of keyword grouping, indicating whether the 𝑖-th keyword | ||
| 𝑥𝑖,𝑗,𝑙 | is grouped into the 𝑙-th ad-group of the 𝑗-th campaign | ||
| 𝑛𝑔𝑟𝑜𝑢𝑝 | The number of ad-groups | ||
| (𝐴𝐷𝐽) 𝑓 | The keyword adjustment function | ||
| (𝐴𝐷𝐽) | A binary decision vector of keyword adjustment, indicating whether the 𝑖-th keyword | ||
| 𝑥𝑖,𝑗,𝑙,𝑡 | is grouped into the 𝑙-th ad-group of the 𝑗-th campaign at time 𝑡 | ||
| (𝐴𝐷𝐽) 𝐾𝑗,𝑙,𝑡 | A set of keywords grouped into the 𝑙-th ad-group of the 𝑗-th campaign at time 𝑡 |
3. Domain-Specific Keyword Pool Generation
Section titled “3. Domain-Specific Keyword Pool Generation”3.1 Problem Description
Section titled “3.1 Problem Description”For advertisers in an application domain, they need to build a pool of relevant keywords over which they can conduct marketing research and from which a more accurate set of keywords can be determined for their search advertising campaigns. This step is called keyword generation, and its output is the domain-specific keyword pool.
Formally, the keyword generation problem can be defined as follows. Let () denote information sources for keyword generation such as a corpus of Web pages, query logs, search results, advertising database, domain-specific semantics and concept hierarchy, the keyword generation process can be given as
(1)
where () denotes the keyword generation function, () denotes a set of generated keywords and denotes the -th keyword in the set.
Generally, keyword pool generation aims to obtain a set of keywords that represents the domainspecific knowledge and information of the targeted market as comprehensive and relevant as possible (Nie et al., 2019), starting with websites (or Web pages) or a set of seed keywords provided by advertisers. In this sense, keyword generation is also known as keyword expansion in that it expands from one or several seed keywords. The generated set of keywords can be viewed as an extended business description for advertisers.
A plethora of academic efforts have been devoted to keyword generation, in order to help advertisers reach potential consumers (e.g., Yih et al., 2006; Thomaidou and Vazirgiannis, 2011; Nie et al., 2019; Scholz et al., 2019; Yang et al., 2019). Note that the keyword generation problem of SSA is essentially similar to that of online contextual advertising in that both are intended to obtain a set of keywords of interest to consumers. Thereby, prior research in this direction did not make a distinction between them. Hence, we follow such a convention in this paper by reviewing keyword generation for the two advertising contexts within a same framework. A related research stream to keyword generation is query expansion in the field of information retrieval. For an extensive review on query expansion, refer to see Carpineto & Romano (2012) and Azad & Deepak (2019).
In the following, we present major techniques, and then discuss input features and evaluation metrics used in the literature.
3.2 Techniques for Keyword Generation
Section titled “3.2 Techniques for Keyword Generation”State-of-the-art keyword generation techniques reported in the SSA literature can be categorized into five groups: (1) co-occurrence statistics, (2) similarity measures, (3) multivariate models, (4) linguistics processing models, and (5) machine learning models. Table 2 presents categories of state-of-the-art keyword generation techniques and the distribution of selected studies in this section. In the following, we will go over the specific keyword generation techniques in each category, and analyze their advantages and disadvantages.
Table 2. Techniques for Keyword Generation
| Category | Approach | Reference | Sources |
|---|---|---|---|
| Co-occurrence | / | Zhou et al. (2007) | Websites and Web pages |
| statistics | |||
| Similarity | The Jaccard similarity | Joshi & Motwani (2006) | Search result snippets |
| measures | Mirizzi et al. (2010) | Semantics and concept hierarchy, | |
| search result snippets | |||
| Chen et al. (2008) | Semantics and concept hierarchy | ||
| The cosine similarity | Abhishek & Hosanagar | Websites and Web pages, search | |
| (2007) | result snippets | ||
| Chang et al. (2009); | Advertising databases | ||
| Sarmento et al. (2009) | |||
| Thomaidou & Vazirgiannis | Search result snippets, websites | ||
| (2011) | and Web pages |
| Semantic similarity between terms | Amiri et al. (2008) | Semantics and concept hierarchy, search result snippets, query logs | |
|---|---|---|---|
| Multivariate models | Logistic regression | Yih et al. (2006); Wu &Bolivar (2008); Lee et al. (2009) | Websites and Web pages |
| Berlt et al. (2011) | Advertising databases | ||
| Bartz et al. (2006) | Query logs, advertising databases | ||
| Collaborative filtering | Bartz et al. (2006) | Query logs, advertising databases | |
| Topic-sensitive PageRank | Zhang et al. (2012a) | Semantics and concept hierarchy, websites and Web pages | |
| Latent Dirichlet | Qiao et al. (2017) | Query logs | |
| allocation | Welch et al. (2010) | Semantics and concept hierarchy, search result snippets | |
| Hierarchical Bayesian | Nie et al. (2019) | Semantics and concept hierarchy | |
| Linguistics processing | Translation model | Ravi et al. (2010) | Advertising databases, websites and Web pages, query logs |
| Word sense | Scaiano &Inkpen (2011) | Semantics and concept hierarchy | |
| disambiguation | |||
| The relevance-based language model | Jadidinejad &Mahmoudi (2014) | Semantics and concept hierarchy | |
| Heuristics-based method | Scholz et al. (2019) | Query logs | |
| Machine | Random walk | Fuxman et al. (2008) | Query logs |
| learning | Decision tree | GM et al. (2011) | Websites and Web pages |
| Sequential pattern mining | Li et al. (2007) | Websites and Web pages | |
| Active learning | Wu et al. (2009) | Search result snippets | |
| Bayesian online learning | Schwaighofer et al. (2009) | Advertising databases | |
| Multi-step semantic | Zhang &Qiao (2018); | Semantics and concept hierarchy, | |
| transfer analysis | Zhang et al. (2021) | query logs | |
| Sequence-to-sequence learning | Zhou et al. (2019) | Query logs |
3.2.1 Co-occurrence Statistics
Section titled “3.2.1 Co-occurrence Statistics”Co-occurrence statistics count paired terms within a collection such as Web pages, taking Web advertising as an information retrieval problem. Notations used in co-occurrence statistics for keyword generation are presented in Table 3a.
Table 3a. Notations used in co-occurrence statistics for keyword generation
| Terms | Definition |
|---|---|
| 𝐾, 𝐾′ | A finite set of keywords/terms |
| ′ 𝑘, 𝑘 | A keyword/term |
| 𝑓𝑟𝑒𝑞(𝑘𝑖 , 𝑘𝑗) | The co-occurrence frequency of 𝑘𝑖 and 𝑘𝑗 |
| 𝐾(𝑡𝑓) | The top frequent keywords/terms |
| The current keyword/term | |
|---|---|
| ratio(k) | The ratio of the sum of the total number of terms in sentences including to the |
| total number of terms in the document | |
| The total number of keywords/terms in sentences including |
In keyword generation, the word co-occurrence matrix is constructed to get weighted keywords. The general setting of co-occurrence statistics is as follows. Given two finite sets of keywords K and K’, , , let denote the Cartesian product of K and K’, the co-occurrence statistics of a keyword pair is given by , which measures the frequency of co-occurrence of and .
Zhou et al. (2007) proposed a keyword extraction model where Web pages and advertisements are represented in a same data structure to support a retrieval process. In their model, nouns and verbs are extracted from the text of Web pages and the co-occurrence frequency between each term and top frequent terms is counted. Specifically, the term weight is calculated as
where K(tf) is the top frequent terms; k and are a term in K(tf) and the current term, respectively; is the co-occurrence frequency of k and ; is the total number of terms in sentences including ; ratio(k) is the ratio of the sum of the total number of terms in sentences including k to the total number of terms in the document.
A higher indicates that the current term (i.e., ) is more important in representing the document. Generally, co-occurrence statistics is used as a baseline in the research on keyword generation.
3.2.2 Similarity Measures
Section titled “3.2.2 Similarity Measures”In cases where two relevant keywords do not occur together, co-occurrence statistics may fail to generate right keywords. Moreover, a keyword may have more than one meaning (Chen et al., 2008), which makes it difficult to filter out generated keywords. Thus, similarity measures are developed to explore the characteristic of keywords. Notations used in similarity measures for keyword generation are presented in Table 3b.
Table 3b. Notations used in similarity measures for keyword generation
| Terms | Definition |
|---|---|
| A characteristic keyword vector | |
| W | A feature weighting function |
| The similarity between and | |
|---|---|
| doc | A document |
| DOC | A set of documents |
| quality(k’,k) | The quality of suggesting keyword for query |
| The TFIDF keyword vector for | |
| TF | The term frequency |
| IDF | The inverse document frequency |
| PMI(k) | A point-wise mutual information feature vector for keyword k |
| The pointwise mutual information between and a given keyword |
Specifically, each candidate keyword is represented as a characteristic keyword vector . Similarity between each pair of keywords is given as
(3)
where is a similarity measure, and one of the most popular possible instantiations of is the cosine; W is the feature weighting function. Term frequency-inverse document frequency (TFIDF) is commonly used as a weighting statistic, which is calculated as , where term frequency (TF) is the relative frequency of keyword k within document doc, i.e., , and the inverse document frequency (IDF) is the logarithmically scaled inverse fraction of DOC that contains k, i.e., .
A similarity graph can be constructed on the basis of the similarity between each pair of keywords, where nodes are keywords and the edges indicate similarities between keywords. Through traversing the similarity graph, a set of relevant but cheaper keywords can be generated (Joshi & Motwani, 2006; Abhishek & Hosanagar, 2007; Amiri et al., 2008; Thomaidou & Vazirgiannis, 2011).
In similarity-based keyword generation, one of common information sources is search result snippets. Given starting seeds, each keyword k is submitted as a query to a search engine to retrieve a set of characteristic documents , which is used to create a context vector for the input keyword and extract relevant keywords. For example, Joshi & Motwani (2006) characterized each input keyword using its text-snippets (i.e., words before and after the input keyword) document from the top 50 search-hits. The relevance of keyword k’ to k is measured by the frequency of k’ observed in the characteristic document of keyword k; then the directed relevance between keywords was used to construct a directed graph (i.e., TermsNet). TermsNet suggests keywords through ranking their qualities. Specifically, the quality of k’ for k is defined as quality(k’, k) =
, where each i is an outneighbor of k’, which helps identify relevant yet nonobvious terms and their semantic associations. Abhishek & Hosanagar (2007) built a mathematical formulation which measures semantic similarity between keywords using a Web-based kernel function. They scraped advertisers’ webpages, extracted and added keywords with high TFIDF into the initial dictionary, then created the context vector for each keyword. Given the TFIDF keyword vector for document , the context vector is the normalized centroid of . The semantic similarity kernel function is defined as the inner product of context vectors for two keywords. Through extracting keywords from the landing page as initial seeds, Thomaidou & Vazirgiannis (2011) entered the extracted seeds into a search engine and parsed the snippets and titles of search results to construct a characteristic vector for these keywords. Most occurrences inside the resulted documents are kept as the most relevant keywords for the seed query. The proposed method can generate keywords that do not explicitly show on the landing page.
Similarity-based methods by exploring sources such as search result snippets can help increase the precision of keyword generation and catch the trend of consumer behaviors. However, when constructing the characteristic vectors of keywords, most similarity-based methods with search result snippets favor the keywords with high co-occurrence frequency. This might lead an expensive cost for the generated keywords, because keywords with high co-occurrence frequency are typically popular. Moreover, keywords generated by exploring the top-hit search result snippets are expensive as well (Thomaidou & Vazirgiannis, 2011). Thus, similarity-based keyword generation with search result snippets may place advertisers into a highly competitive environment, thus can’t guarantee profit maximization.
To address this issue, researchers have explored semantic relationships between keywords with user-generated contents such as Wikipedia, DBpedia and manually-defined Web directories as valuable sources to generate non-obvious keywords (Amiri et al., 2008; Chen et al., 2008; Mirizzi et al., 2010). Wikipedia contains a large amount of clean information and conceptual knowledge on a wide spectrum of topics that can be utilized to suggest excessive long-tail keywords. Amiri et al. (2008) considered each query as an initial concept and tried to find related concepts from the Wikipedia collection. For each query keyword q, they grouped the retrieved documents by expectation maximization (EM) clustering algorithm and constructed a representative vector (i.e., keywords vector) for each cluster on
the basis of the TFIDF scheme. The representative vector contains related keywords/concepts and the relationship weights between these keywords and . Based on these vectors, a contextual graph was created to suggest a set of keywords/concepts that are more similar to the query keywords. DBpedia dataset is a community effort on the basis of Wikipedia to extract and store structured information in an RDF dataset that supports sophisticated queries. Mirizzi et al. (2010) presented a system to generate semantic tags through exploiting semantic relations from the DBpedia dataset. The similarity between each pair of resources in the DBpedia graph is calculated by querying external information sources (e.g., search engines and social bookmarking systems) and exploiting textual and link analysis in DBpedia. They used a hybrid ranking algorithm to rank keywords and expand queries formulated by users, and proved the validity of their algorithm by comparing with other RDF similarity measures (i.e., Algo2, Algo3, Algo4 and Algo5). By exploiting the semantic knowledge in the concept hierarchy built based on a manually-defined Web directory, Chen et al. (2008) proposed a keyword generation method. In more detail, it first matched a given seed keyword with one or several relevant concepts, and then these concepts were used together with the concept hierarchy to enrich the meaning of the seed keyword, finally a set of keywords was suggested by taking advantage of the conceptual information based on the similarity function of a variant of the Jaccard coefficient. However, similarity-based methods with semantic relationships suffer from the low concept coverage, and potentially lead to a decrease in the conversion rate, because low-cost keywords may be too far away from the initial seeds and thus fail to attract the target users.
Other sources such as co-bidding information and ads database have also been exploited in similarity-based keyword generation (Chang et al., 2009; Sarmento et al., 2009). Assuming that a set of bid keywords under the same ad is associated with a similar hidden intent, Chang et al. (2009) constructed a point-wise mutual information feature vector for each keyword () = (1 , 2 , … , ), where is the pointwise mutual information between keyword and co-bidded keyword . Then given an ad consisting of keywords, they ranked the suggested keywords in the ad network through summing the cosine similarity between the PMI feature vectors, i.e., (, ) = ((), ()) for = [1, … , ]. Similarly, assuming that advertisers associate inter-changeable keywords into the same ad, Sarmento et al. (2009) constructed a keyword synonymy graph by computing pairwise similarity between all co-occurrence vectors, and suggested relevant and non-obvious keywords by ranking candidate keywords through a function considering both the overlap and the average similarity. Through performing online comparisons of the proposed method with another keyword generation method used in the largest Portuguese Web advertising broker, they showed that advertisements containing keywords generated by the proposed method often have a superior performance in terms of click-through rate, which in turn resulted in a potential revenue increase.
3.2.3 Multivariate Models
Section titled “3.2.3 Multivariate Models”Keyword generation methods based on similarity measures are heavily confined to the local space defined by seed keywords in that they rely on statistical or semantic relationships between keywords. Moreover, in many cases, keywords generated by similarity-based methods might fail to capture search users’ real intents that are the most important to advertisers. To address these issues, multivariate models have been used to use rich latent information to facilitate keyword generation. Multivariate models can help advertisers generate a long tail of candidate keywords that are relevant and occupy a large fraction of the total traffic, by exploring potential factors and hidden topics affecting the performance of candidate keywords. Notations used in multivariate models for keyword generation are presented in Table 3c.
Table 3c. Notations used in multivariate models for keyword generation
| Terms | Definition |
|---|---|
| 𝑦 | A binary variable indicating whether a candidate keyword is relevant to a given |
| seed keyword | |
| 𝒙 | A vector of input features (𝑥̅) associated with a candidate keyword |
| 𝑤̅ | A weight learned for an input feature in 𝒙 |
| 𝑠𝑖𝑡𝑢𝑎𝑡𝑖𝑜𝑛 | Situation features specific to a targeted scene |
| 𝑐𝑜𝑢𝑛𝑡(𝑘, 𝑠𝑖𝑡𝑢𝑎𝑡𝑖𝑜𝑛) | The number of times that 𝑘 occurs in 𝑠𝑖𝑡𝑢𝑎𝑡𝑖𝑜𝑛 |
| 𝑐𝑜𝑢𝑛𝑡(𝑘) | The collection frequency of 𝑘 |
| 𝑐𝑜𝑢𝑛𝑡(𝑠𝑖𝑡𝑢𝑎𝑡𝑖𝑜𝑛) | The number of keywords in scenes mapped to 𝑠𝑖𝑡𝑢𝑎𝑡𝑖𝑜𝑛 |
| 𝑈 | A set of items (e.g., URLs) |
| 𝑹 𝐾 × 𝑈 | A keyword-item rating matrix |
| 𝑹𝑢 | The 𝑢-th column of 𝑹 𝐾 × 𝑈 |
| 𝑅𝑘,𝑢 | The rate of 𝑘 on item 𝑢 |
| 𝑸 | A binary column vector with 𝐾 -dimensions where it is equal to 1 if the keyword |
| on the 𝑘-th position is the seed keyword | |
| 𝒔𝒊𝒎 | A similarity vector |
| 𝝅𝑚 | A vector of indexed Web pages in the 𝑚-th iteration |
| (𝑚) 𝜋𝑖 | A score of the 𝑖-th Web page |
| 𝐺 | 1 A row-normalized adjacency matrix of the link graph, and 𝐺𝑗,𝑖 = 𝑜𝑖 |
| 𝑜𝑖 | The out-degree of 𝑖-th Web page |
|---|---|
| 𝚲 | A damping vector biased to a certain topic |
| 𝑪 | A content damping vector |
| 𝜗1 , 𝜗2 | Parameters controlling the impact of the content relevant score and the |
| advertisement relevant score | |
| 𝑔 | A row-normalized Wikipedia graph link 𝑛 × 𝑛 matrix |
| 𝑡𝑜𝑝𝑖𝑐 | A topic |
| 𝑛𝑡𝑜𝑝𝑖𝑐 | The number of topics |
| 𝑛𝑑 | The number of documents |
| (𝑡𝑜𝑝𝑖𝑐) 𝜑 | The topic distribution for document |
| (𝑘) 𝜑 | The keyword distribution for topic |
| (𝑡𝑜𝑝𝑖𝑐) (𝑘) 𝛽 , (𝛽 ) | Hyper parameters of Dirichlet distributions |
| 𝑘0 | A seed keyword |
| 𝑘0 . 𝐶𝑎𝑛𝑑 | The set of candidate keywords for 𝑘0 |
| 𝐼 | A set of keywords consisting of 𝑘0 and 𝑘0 . 𝐶𝑎𝑛𝑑 |
| 𝑘𝑖 . 𝐴𝐾 | A list of associative keywords of 𝑘𝑖 |
| 𝑘𝑖 . 𝑃𝑟𝑜𝑓𝑖𝑙𝑒 | A corresponding characteristic profile of 𝑘𝑖 |
| 𝑘. 𝑣𝑜𝑙 | The search volume of 𝑘 |
| 𝐶𝑜𝑟𝑝𝑢𝑠 | All characteristic profiles of keywords in 𝐼 |
| 𝜂𝑗 | The total times that the title keyword doesn’t appear in the 𝑗-th component of a |
| Wikipedia article | |
| 𝛼𝑗 | The importance of a component where a given keyword appears |
| 𝜃𝑗 | A random variable obeying an Beta distribution, denoting the unimportance of a |
| component, i.e., 𝜃𝑗 = 1 − 𝛼𝑗 | |
| ′ ′ 𝛼𝑗 , 𝛽𝑗 | The shape parameters for the Beta distribution of 𝜃𝑗 |
| 𝐾𝑊𝑊(𝑘) | The weight for a given keyword |
| (𝑘) 𝑇𝐹𝐼𝐷𝐹𝑠 | The importance of a keyword presented in the abstract |
| (𝑘) 𝑇𝐹𝐼𝐷𝐹𝑐 | The importance of a keyword presented in the content |
| (𝑘) 𝑇𝐹𝐼𝐷𝐹𝑑 | The importance of a keyword presented in the main text |
| 𝑇𝐹𝐼𝐷𝐹𝑖 (𝑘) | The importance of a keyword presented in the information box |
| 𝐴𝑇(𝑘) | A variable indicating whether a keyword is in the anchor text |
In the literature on keyword generation, five multivariate models, namely logistic regression, collaborative filtering, topic-sensitive PageRank, latent Dirichlet allocation and hierarchical Bayesian have been employed to explore effects of various keyword characteristics in the generation process.
(1) Logistic regression (LR). LR is a basic learning technique which treats keyword generation as a binary classification problem. LR learns a vector of weights for input features and returns the estimated probability of whether a candidate phrase is relevant (Yih et al., 2006; Wu & Bolivar, 2008; Berlt et al., 2011; Lee et al., 2009). Typically, LR is used in keyword generation in the following form:
(4)
where y is a binary variable, whose value is equal to 1 if the candidate keyword is relevant, otherwise 0; x is a vector of input features associated with a candidate keyword; and is a weight that the LR model learns for an input feature in x. The generated keywords are ranked by the estimated probability.
LR was used in finding advertising keywords from Web pages by Yih et al. (2006). Specifically, it takes y as a binary variable under the monolithic selector; while under the decomposed selector, a phrase is decomposed into individual words and each word is tagged with one of the five labels (i.e., beginning, inside, last, unique and outside), and then five estimated possibilities are returned, i.e., . The probability of a phrase is calculated by multiplying the five probabilities of its individual words being the correct label of the sequence. Experiments illustrated that LR significantly outperforms baseline methods (e.g., the TFIDF model, an extended TFIDF model with learned weights and a domain-specific keyword extraction method).
Subsequent studies used LR for different advertising scenarios. Following Yih et al. (2006), Wu & Bolivar (2008) added HTML features and proprietary data features (e.g., leaf and root category entropy) for the particular website (i.e., eBay) in the LR model, and constructed a candidate category vector for each keyword to resolve the keyword ambiguity problem. In order to find relevant keywords from online video contents, Lee et al. (2009) took into account not only within-document term features (e.g., TF-IDF scores), but also situation features specific to a targeted scene to train a LR model, i.e., pointwise mutual information (PMI) based on the co-occurrence information between a term k and situation situation, , where count(k, situation) is the number of times that k occurs in situation situation, count(k)and count(situation) are the collection frequency of k and the number of words in scenes mapped to situation, respectively. Experiments showed that the scene-specific features are potentially useful to improve the performance of keyword extraction in video advertising. Instead of directly asking humans to evaluate the relevance of candidate keywords, Berlt et al. (2011) reduced the training cost of the LR-based keyword generation model by taking experts’ evaluation on the relevance of advertisements for the page where the keyword candidate is extracted from. Experiments showed that their ad-collection-aware approach could yield significant gains without dropping precision values. However, the LR-based methods can only generate keywords from particular pages, while missing
information from the similar pages. Besides websites and Web pages, advertisement databases and search click logs have been used by Bartz et al. (2006) to examine the performance of logistic regression, and results showed that biddedness data in advertisement databases can provide better precision.
(2) Collaborative filtering (CF). CF is a classic recommendation algorithm. Suppose that there are a keyword set K and an item (e.g., URL) set U. Following Bartz et al. (2006), the keyword-item rating matrix in keyword generation is given as
(5)
where denotes the rate of keyword k on item u. Each keyword can be represented as a |U|-dimensional vector and the similarity between two rating vectors can be measured with the cosine similarity
(6)
Then the keyword-item rating matrix could be converted to a keyword-term similarity matrix based on the cosine similarity, and the Top-k most similar keywords are ranked for keyword generation. Specifically, keywords and URLs in the search logs are extracted to construct a term-URL rating matrix whose rate is the number of times that a user searched for that keyword and clicked on that URL; then a column vector with |K|-dimensions was created, whose value is 0-1 binary, where it is equal to 1 if the keyword in the k-th position is the seed keyword. The similarity vector was calculated as , where is the u-th column of matrix , and is an 0-1 binary indicator vector with |K|-length and contains 1 for every non-zero entry of . Finally, the keywords were ranked in descending order of indexes in .
Based on advertisement databases and search click logs, Bartz et al. (2006) examined the performance of a CF model with respect to generating relevant keywords, starting from a set of seed keywords describing an advertiser’s products or services, and found that the standard collaborative filtering framework has statistically equal performance with the logistic regression with a set of selected features.
(3) Topic-sensitive PageRank (TSPR). Topic-sensitive PageRank extends PageRank by
allowing the iteration process to be biased to a specific topic. The main idea of the PageRank algorithm is to propagate the quality score of a Web page to its out-links and obtain the static quality of Web pages by performing a random walk on the link graph. Following Haveliwala (2003), the topic-sensitive PageRank algorithm is defined as
\boldsymbol{\pi}_{m+1} = (1 - \vartheta)\boldsymbol{\Lambda} + \vartheta G \boldsymbol{\pi}_m, \tag{7}
where = [1 () , … , () is a vector of the indexed Web pages in the -th iteration, () is the score of the -th Web page; the matrix is a row-normalized adjacency matrix of the link graph, and , = 1 , is the out-degree of the -th Web page; is the damping vector biased to a certain topic, where -th element in is the relevance of the -th Web page to the topic.
The propagation process of the topic-sensitive PageRank algorithm is biased by the damping vector in each iteration. After iterations, Web pages with higher damping values propagate higher scores to their neighbors in the link graph.
In order to simultaneously generate keywords valuable for advertising from short-text Web pages, Zhang et al. (2012a) combined the content bias and advertisement bias into the propagation process of topic-sensitive PageRank, given as
\mathbf{R}_{m+1} = \vartheta_1 \mathbf{C} + \vartheta_2 \mathbf{A} + (1 - \vartheta_1 - \vartheta_2) g \mathbf{R}_m, \tag{8}
where is the content damping vector (i.e., the vector of the relevance between a set of Wikipedia entities and the target Web page) obtained through a regression based on Yih et al. (2006), and is the advertisement damping vector obtained through calculating the frequency of each entity in the text of an advertisement; 1 and 2 are the parameters controlling the impact of the content relevant score to the content-sensitive PageRank value and the advertisement relevant score to the advertisementsensitive PageRank value, respectively; is the row-normalized Wikipedia graph link × matrix, where stands for the size of the entity set. The TSPR-based keyword generation method can generate highly relevant keywords that don’t occur on the target Web page, and can yield a significant improvement in precision over baseline methods (i.e., TF counting, supervised learning).
(4) Latent Dirichlet allocation (LDA). Users’ search intentions can be captured timely through exploring users’ query topics hidden in query logs, which are valuable for commercial advertising and helpful in keyword generation (Qiao et al., 2017). Latent Dirichlet allocation (LDA) is a generative probabilistic model for a collection of documents, assuming that each document is represented as
random mixtures over latent topics and each topic is characterized by a distribution over words (Blei et al., 2003).
Given a corpus consisting of topics over documents, and each document contains keywords, let and denote the topic (topic) distribution for document and the keyword (k) distribution for topic, respectively. Both and obey Dirichlet distributions with hyper parameters and . Given the seed keyword , Qiao et al. (2017) generated a set of candidate keywords by analyzing indirect associations between and keywords in query logs. Let I denote a keyword set consisting of seed keyword and candidate keywords , i.e., . Each keyword has a list of associative keywords , and the list of associative keywords constitutes a characteristic profile for , i.e., , where k is a keyword in and k.vol is its search volume. Taking each characteristic profile as a document, all characteristic profiles of keywords in I can be collected as a corpus, which is denoted as .
In keyword generation, LDA interprets the characteristic profile of (i.e., ) as a multinomial distribution over a set of topics and each topic is assigned a multinomial distribution over keywords in Corpus. Then the generation probability of a keyword k in the Corpus can be obtained through a process that samples a topic (topic) from specific with a characteristic profile and subsequently samples a keyword (k) from associated with topic, which is formulated as
Dir(\varphi^{(k)}|topic,\beta^{(k)}) d\varphi^{(k)}. \tag{9}
The sampling process discussed above is repeated k.vol rounds for each keyword in a characteristic profile. Then the generation probability of the observed Corpus can be obtained by repeatedly applying the sampling process to all the characteristic profiles, which is given as
(10)
Then Gibbs sampling was used to estimate parameters () and () as well as the latent variable by maximizing (| () , () ) . After the parameter estimation, each keyword can be projected into a topic distribution.
Considering the fact that two keywords related to similar topics might be competitive with each other due to market overlaps, Qiao et al. (2017) utilized topic distributions of keywords in query logs to infer competitive relationships between keywords. The mined topic structure is further combined into a factor graph model to extract a set of competitive keywords. The LDA-based method can generate competitive keywords which rarely co-occur with the seed keyword in queries.
On video sites with user-generated clips (e.g., YouTube), the text data is typically short. A video comprises a small number of hidden topics, which can be represented as keyword probabilities. Thereby, a video’s text can be generated from some distribution over those topics. Welch et al. (2010) explored an LDA-based keyword generation method for video advertising by mining a range of short-text sources associated with videos. Compared to statistical n-gram keyword generation methods, the LDA-based method performed better when a limited amount of text data is available, and can substantially improve the matching relevance and the profitability of generated keywords.
(5) Hierarchical Bayesian (HB). HB is a statistical model formed in multiple hierarchical structures which can be used to estimate the harmonic parameters in the keyword weighting formula for keyword generation. Given that a set of articles has been randomly selected from the corpus (e.g., Wikipedia articles), HB calculates the weight based on the importance of a keyword from the components of the Wikipedia article. Let be the total times that the title keyword doesn’t appear in the -th component, and be a random variable obeying a Beta distribution, i.e., ~( ′ , ′ ), based on the sample data . Following Nie et al. (2019), the posterior joint probability distribution ( , ′ , ′ |) is
p(\theta_j, \alpha'_j, \beta'_j | \eta_j) = \frac{p(\eta_j | \theta_j, \alpha'_j, \beta'_j) p(\theta_j | \alpha'_j, \beta'_j) p(\alpha'_j, \beta'_j)}{p(\eta_j)} \propto p(\eta_j | \theta_j, \alpha'_j, \beta'_j) p(\theta_j | \alpha'_j, \beta'_j) p(\alpha'_j) p(\beta'_j). \tag{11}
By using HB, the weight of each keyword extracted from articles in the corpus can be calculated and used to decide its priority in the candidate set. Nie et al. (2019) presented a keyword generation method taking advantage of the rich link structure of Wikipedia’s entry articles. Starting with a few seed keywords, the proposed method generates keywords in an iterative way, until a threshold is reached which balances the tradeoff between coverage and relevance of the generated keyword set. In the keyword generation process, the weight of a keyword in an article was calculated as () = 1() + 2() + 3() + 4() + 5 |()| , where () is the weight for a given keyword; (), (), () and () measure the importance of a keyword occurring in abstract, content, main text, information box, respectively; |()| indicates whether a keyword is in the anchor text; and ( = 1 − , = 1, ⋯ ,5) is the importance of a component where the keyword appears, which can be estimated by using the hierarchical Bayesian keyword weighting method. The HB-based method performs at a superior level with respect to both coverage and relevance.
3.2.4 Linguistics processing
Section titled “3.2.4 Linguistics processing”Multivariate methods are incapable of generating semantically relevant keywords that don’t contain or co-occur with the seed keywords. Moreover, multivariate methods suffer from the problem of topic drift which might generate keywords with little clicks and conversions and thus produce a massive overhead. Thus, more syntactic and semantic analysis are needed to capture users’ real search intentions in keyword generation. Keyword generation based on linguistics processing helps find more semantically related and profitable keywords. Notations used in linguistics processing models for keyword generation are presented in Table 3d.
Table 3d. Notations used in linguistics processing models for keyword generation
| Terms | Definition |
|---|---|
| 𝒌 | 𝒌 = {𝑘(1) , 𝑘(2) , … , 𝑘(𝑛) }, denoting the bags of words of keyword 𝑘 |
| 𝑙𝑎𝑛𝑑𝑖𝑛𝑔 | A landing page |
| 𝒍𝒂𝒏𝒅𝒊𝒏𝒈 | 𝒍𝒂𝒏𝒅𝒊𝒏𝒈 = {𝑙𝑎𝑛𝑑𝑖𝑛𝑔(1) , 𝑙𝑎𝑛𝑑𝑖𝑛𝑔(2) , … , 𝑙𝑎𝑛𝑑𝑖𝑛𝑔(𝑚) }, denoting the bags of words |
| of 𝑙𝑎𝑛𝑑𝑖𝑛𝑔 | |
| 𝑡𝑟𝑎𝑛𝑠𝑙𝑎𝑡𝑖𝑜𝑛 | A translation table denoting the likelihood of 𝑙𝑎𝑛𝑑𝑖𝑛𝑔(𝑗) being generated from 𝑘(𝑖) |
| (𝑙𝑎𝑛𝑑𝑖𝑛𝑔(𝑗) 𝑘(𝑖)) | |
| 𝑤𝑗 | A weighting parameter for 𝑙𝑎𝑛𝑑𝑖𝑛𝑔(𝑗) |
| 𝑚𝑎𝑝𝑝𝑖𝑛𝑔 | A mapping from word(s) to sense(s) |
| 𝑆𝑒𝑛𝑠𝑒𝑠𝐷𝐼𝐶(𝑘𝑖) | The set of senses encoded in a dictionary 𝐷𝐼𝐶 for 𝑘𝑖 |
| 𝑞 | A query keyword |
| 𝒒 | 𝒒 = {𝑞(1) , 𝑞(2) , … , 𝑞(𝑛)}, denoting a set of query keywords after sampling 𝑛 times |
In the following, we go through four linguistics processing methods in keyword generation, namely, translation model, word sense disambiguation, relevance-based language models and heuristics-based methods.
(1) Translation model (TM). Translation model is originally presented in statistical machine translation literature to translate text from one type of natural languages to another (Brown et al., 1993). In keyword generation, translation model learns translation probabilities from keywords to landing pages through a parallel corpus, and bridges the vocabulary mismatch by giving credits to words in a phrase that are relevant to the landing page but do not appear as part of it. By treating keywords and landing page as bags of words, i.e., = {(1) , (2) , … , () } and = {(1) ,(2) , … , () } , for each () ∈ , the probability of the translation probability from the keyword to the landing page (|) can be estimated as
(|) ∝ ∏ ∑ (() |()), (12) where (() |()) is the translation table, i.e., the probability that characterizes the likelihood of a word in a landing page being generated from a word in a keyword.
Ravi et al. (2010) proposed a keyword generation method by combining a translation model with language models to produce highly relevant well-formed phrases. Specifically, the probability (|) was modified by associating a weight for all () ∈ with respect to different features (e.g., a higher weight for words with HTML tags), i.e., (|) ∝ ∏ (∑ (() |())) , then the keyword language model () was instantiated with a bigram model capturing most of useful co-occurrence information and smoothed by a unigram model. Based on the Bayes’ law, the probability (|), i.e., the likelihood of a keyword given the landing page, can be estimated to rank the keywords, i.e., (|) ∝ (|) P(). Experiments based on a realworld corpus of landing pages and associated keywords showed that the TM-based method outperformed significantly over a method based purely on text extraction, and could generate many human-crafted keywords.
(2) Word sense disambiguation (WSD). WSD is the ability in computational linguistics to identify which sense (meaning) of a word is used in a particular context (Navigli, 2009). Through viewing a text as a sequence of words (1, 2, … , ), WSD can be defined as a task of assigning the appropriate sense(s) to word(s) in the text, i.e., to identify a mapping () from word(s) to sense(s), such that () ⊆ (), where () is the set of senses encoded in a dictionary for word , and () is that subset of the senses of which are appropriate in the text. In online advertising and SSA, in order to exclude the display of an advertisement from a population of non-target audiences, it is necessary to identify negative keywords. For example, Scaiano & Inkpen (2011) proposed a method to automatically identify negative keywords, using Wikipedia as a sense inventory and an annotated corpus. Specifically, they searched all links containing the seed keywords and collected all destination pages to find all senses for each keyword, then generated context vectors for each sense by tokenizing each paragraph containing a link to the sense being considered. In this process, all words were recorded and counted as a dimension in the context vector. After identifying the intended sense and creating a broad-scope intended-sense list, negative keywords are identified through finding words from the context vectors of the unintended senses with high TFIDF. The WSD-based method could find keywords strongly correlated with negative topics and improve the performance of advertising campaigns.
(3) The relevance-based language (RBL) model. The RBL model is used to determine the probability of observing a keyword in a collection of documents, i.e., (|) (Lavrenko & Croft, 2017). Given a query keyword and a large collection of documents (), both and each document are represented as a sequence of words. Each document in is related to and there is no training data about which document in is related to . The relevance model is referred to the underlying mechanism that determines the probability (|) . We assume that both and documents related to can be sampled from , but possibly by different sampling processes. After sampling times, we can observe query keywords = {(1) , (2) , … , ()}. Thus, given such observations, we can estimate the conditional probability of observing as
(13)
Jadidinejad & Mahmoudi (2014) proposed a keyword generation method based on a modified relevance-based language model, with Wikipedia as the knowledge base. First, by capitalizing Wikipedia’s disambiguation pages, different semantic groups for a given ambiguous query were extracted. Second, appropriate semantic groups were selected based on user’s intent, and an initial list of candidate keywords were generated by tracking bidirectional anchor links. Third, given a seed query and a collection of documents corresponding to candidate keywords from Wikipedia, the relevancebased language model was applied to estimate the probability of observing a keyword in documents, which helped measure the relevance between candidate keywords to the seed query. The RBL-based method is language independent, well-grounded with expert keywords and computationally efficient.
(4) Heuristics-based method. Consumers with a high conversion probability tend to use an online store’s internal search engine (Ortiz-Cordova et al., 2015). Scholz et al. (2019) proposed a heuristicsbased method to extract keywords from an online store’s internal search logs. Specifically, a set of candidate keywords identified from the internal search and other sources (e.g., Thesauri) was enriched with other keyword generation tools and filtered according to the monthly search volume in Google, then keywords whose internal search volumes are higher than a predefined threshold were included into the target set. This heuristics-based method can substantially increase the number of profitable keywords and the conversion rate, and in the meanwhile, decrease the average cost per click.
3.2.5 Machine learning
Section titled “3.2.5 Machine learning”The performance of linguistics processing is influenced by the quality of sources (e.g., Web pages, texts, dictionaries), which might make suggested keywords deviate from search users’ real intentions. Machine learning can automatically learn and produce more accurate and reliable results by consuming a large amounts of data accumulated in online advertising, executing feature engineering without little interference of humans and capturing more rich behavioral information and structural relationships with high-order representation. Thus, machine learning models can generate large sets of relevant keywords by capturing the intention of users and processing the up-to-date information sources. Notations used in machine learning models for keyword generation are presented in Table 3e.
Table 3e. Notations used in machine learning models for keyword generation
| Terms | Definition |
|---|---|
| 𝜉𝑛 | A random variable describing the position of random walk after 𝑛 steps |
| 𝓌𝑛 | The 𝑛-th step of a random walk |
| 𝑐̃ | A concept that an advertiser is interested in |
| 𝑙𝑘 | The random variable related to a concept for query keyword 𝑘 |
| 𝑙𝑢 | The random variable related to a concept for URL 𝑢 |
| 𝒯 | The probability of transiting to the absorbing null class node |
| 𝐷 | Dataset |
| 𝑛̂ | A node in decision tree |
| ′ 𝑛̂ | A child node of 𝑛̂ |
| 𝐶(𝑛̂ Υ) | A set of child nodes of 𝑛̂ |
| 𝐷𝑛̂ | A subset of dataset 𝐷 at node 𝑛̂ |
| Υ | The branching criterion |
| 𝐺(𝑛̂, Υ) | The quality of the partition of 𝐷𝑛̂ induced by Υ |
| 𝑥Υ | An element of 𝒙 |
| 𝒳Υ | A set of unique values of categorical variable 𝑥Υ |
| 𝒳Υ,𝑘 | The 𝑘-th value of 𝒳Υ |
| 𝒳Υ | The number of values in 𝒳Υ |
|---|---|
| 𝐻 | The entropy |
| 𝑠𝑒𝑞, 𝑠𝑒𝑞′ | A sequence |
| ′ 𝑠𝑒𝑞𝑖 (𝑠𝑒𝑞𝑖 ) | The 𝑖-th element in sequence 𝑠𝑒𝑞(𝑠𝑒𝑞′ ) |
| 𝑠𝑒𝑞_𝑖𝑑 | The id of sequence 𝑠𝑒𝑞 |
| 𝑠𝑒𝑞_𝑝𝑎𝑡𝑡𝑒𝑟𝑛 | A sequential pattern |
| 𝑲𝑇 | 𝑇 The union of the keyword matrix [𝒌𝑇,1 , … , 𝒌𝑇,𝑛] and the target dataset {𝒌𝑇,𝑖 } |
| 𝑲𝐿 | 𝑇 The union of the keyword matrix [𝒌𝐿,1 , … , 𝒌𝐿,𝑚] and {𝒌𝐿,𝑖 }, i.e., a subset of 𝑲𝑇 |
| that is chosen to be labeled | |
| 𝜖𝑖 | The measurement error |
| 𝑓𝑇 | 𝑇 𝑓𝑇 = [𝑓(𝑘𝑇,1), … , 𝑓(𝑘𝑇,𝑛)] , denoting the function values on all the available data |
| 𝐾𝑇 | |
| 2 𝜎 | The variance of a distribution |
| 2𝑪𝑓 𝜎 | A covariance matrix |
| 𝑠𝑖𝑘 | A binary parameter indicating whether the 𝑖-th ad is subscribed with the keyword 𝑘 |
| 𝒞𝑖 | A binary variable indicating whether the 𝑖-th ad belongs to category 𝑗 |
| 𝜇𝑗𝑘 | The mean of the prior distribution for the keyword subscription probability |
| 𝑟̃𝑖𝑗 | The probability that the 𝑖-th ad belongs to category 𝑗 |
| 𝑐𝑎𝑛𝑑𝑘𝑛−1 | A candidate set of keywords with one-step relevance to 𝑘𝑛−1 |
| (𝑘𝑖 ) 𝑅1 , 𝑘𝑖+1 | The one-step relevance of keyword pair (𝑘𝑖 , 𝑘𝑖+1 ) |
| 𝑅𝑛 | 𝑅𝑛 (𝑘0 , 𝑘 𝑘1 , 𝑘2 , … , 𝑘𝑛−1 ), denoting the n-step relevance of 𝑘0 and 𝑘 via the |
| intermedia keywords 𝑘1 , 𝑘2 , … , 𝑘𝑛−1 | |
| 𝑯 | 𝑯 = (𝒉1 , 𝒉2 , … , 𝒉𝑛), denoting hidden representations |
| 𝒆(𝑘𝑡) | The embedding of keyword 𝑘𝑡 |
| 𝒄𝒕𝑡−1 | A context vector |
| 𝒔𝑡 | A state vector |
| 𝐾̃ | (𝑘̃ , 𝑘̃ , … , 𝑘̃𝑚), denoting a generated target keyword sequence 𝐾̃ = 1 2 |
| 𝑑𝑜𝑚𝑎𝑖𝑛𝑘, 𝑑𝑜𝑚𝑎𝑖𝑛𝑘̃ | The corresponding domain categories of 𝐾 and 𝐾̃ |
In the literature, researchers have investigated several statistical learning methods to facilitate keyword generation in SSA, including random walk, decision tree, sequential pattern mining, active learning, Bayesian online learning, multi-step semantic transfer analysis and sequence-to-sequence learning.
(1) Random walk (RW). RW can be used to describe a keyword generation path including a succession of random steps in the query-click graph extracted from search logs. In essence, clicks represent a strong association between queries and URLs (Yang & Zhai, 2022). Hence, advertisers can exploit the proverbial “wisdom of the crowds” to reconstruct query-click logs as a weighted bipartite graph (,,). Specifically, query keywords in and URLs in constitute the partitions of the graph, and the number of times that users issued query k to the search engine and clicked on URL u (i.e., ) can be regarded as weight on the edge . Suppose that is a sequence of independent and identically distributed random variables, a random walk is a random process which describes a path consisting of a succession of random steps on some mathematical space (Xia et al., 2019). It can be denoted as , where is a random variable describing the position of random walk after n steps and , where denotes the step of the random walk.
Fuxman et al. (2008) formulated the keyword generation problem within a framework of Markov Random Fields and developed an RW-based algorithm with absorbing states to traverse a query-click graph. Given a concept that an advertiser is interested in, a seed set of URLs relevant to was constructed manually, which can be regarded as the representation of . Let and denote the random variable related to for query keyword k and URL u, respectively. The probability that a random walk starting from query k will be absorbed at concept , i.e., , can be computed as
P(l_k = \tilde{c}) = (1 - T) \sum_{u:(k,u) \in R} \frac{R_{k,u}}{\sum_{u:(k,u) \in R} R_{k,u}} P(l_u = \tilde{c}), \tag{14}
where is the probability of transiting to the absorbing null class node. The null class node is a node in a query-click graph whose probability (i.e., or ) is below a threshold, and the set of null class nodes define the boundary of the query-click graph. Similarly and recursively, for all URLs in the seed set, ; for other URLs (i.e., unlabeled URL) in search logs, the probability of a random walk that starts from URL u and ends up being absorbed in concept , i.e., , can be computed as
(15)
The processes defined by and iterated alternately until the convergence. Discarding and whose probabilities lower than a predefined threshold, we can obtain , the probability that query k belongs to seed concept , for every query in the set K. we can obtain , i.e., the probability that k will be absorbed at , for every query keyword in search logs, which can be regarded as the relevance between k and . The RW-based can generate a large amount of high-quality keywords with minimal effort from advertisers.
(2) Decision tree (DT). DT is a flowchart-like structure where paths from the root to leafs represent classification rules. Given a dataset with x being a feature vector of keywords
and y being the label of relevance, DT represents a recursive partition of D such that (a) each node of the tree stores a subset of D with the root node storing D, (b) the subset at node is the union of the mutually disjoint subsets stored at its child nodes , i.e., forms a partition of where denotes the set of child nodes of , and (c) the partition is determined by a branching criterion Y. The optimal DT is built by recursively identifying the locally optimal branching criterion at each node starting from the root node while subjecting to some stopping as well as pruning criteria. Specifically, at node , the optimal branching criterion is
\theta_{\hat{n}}^* = argmax_Y \ G(\hat{n}, Y), \tag{16}
where measures the quality of the partition of induced by Y.
In the decision tree-based scheme, GM et al. (2011) developed a keyword generation approach to learn the website-specific hierarchy from the (Web page, URL) pairs of a website, and keywords are populated on nodes of the induced hierarchy via successive top-down and bottom-up iterations. Human evaluations showed that their method outperformed previous approaches by Broder et al. (2007) and Anagnostopoulos et al. (2007) in terms of relevance. In keyword generation, as specified by GM et al. (2011), an instance (x, y) corresponds to a Web page, where x is a vector of features extracted from the URL of the Web page, and y is the cluster of Web pages with similar contents. As an example, consider a Web page with the URL “www.examplewear.com/exampleshop/product.php?view=detail& group = shoes & dept = men”, from which four features can be extracted, i.e., (the name of the php script), =“detail” (the value of argument “view”), =“shoes” (the value of argument “group”) and = “men” (the value of argument “group”). Each element of x, i.e., , is a categorical variable having a set of unique values denoted by . For example, “women”, “outlet”, “accessories”}, which is constructed by going through all URLs and collecting values of the “dept” argument. For convenience, let denote the k-th value of assuming an arbitrary order, and denote the number of values in . The branching criterion is to select a feature , according to which is partitioned. The quality of the resulting partition is measured with the gain ratio metric, specified as follows.
G(\hat{n}, Y) = \frac{H(y|D_{\hat{n}}) - \sum_{k=1}^{|\mathcal{X}_{Y}|} P(x_{Y} = \mathcal{X}_{Y,k}|D_{\hat{n}}) H\left(y|D_{\left(\hat{n}, \mathcal{X}_{Y,k}\right)}\right)}{H(x_{Y}|D_{\hat{n}})}, \tag{17}
where is the estimated probability of having value on feature dimension i for a data instance in , is the entropy of labels in measuring how impure (diversified)
Web pages in are in terms of assigned clusters, is the entropy of labels in , and is the entropy of feature Y in measuring the complexity of the partition. The gain ratio metric measures how much impurity (content dissimilarity) reduction can be achieved through a data space partition, and favors partitions with high impurity reduction but low partition complexity, which is helpful in preventing overfitting.
(3) Sequential pattern mining (SPM). SPM aims to find frequent patterns from a set of sequences (Mabroukeh & Ezeife, 2010), which is used to find keywords in online broadcasting contents. Given a set of items (e.g., terms) , two sequences and , where ( ) is a subset of items K, if there exist integers making , , …, , seq’ is called a subsequence of seq, i.e., . Given a sequence dataset D, i.e., a set of tuples , where seq is a sequence and is the id of seq, the support of a subsequence is the number of tuples in the dataset containing seq’, given as
support_D(seq') = |\{\langle seq\_id, seq \rangle | (\langle seq\_id, seq \rangle \in D)^{\wedge} (seq' \in seq)\}|. \tag{18}
Given a positive integer as the support threshold, a sequence seq’ is called a sequential pattern if .
In keyword generation from online community contents, Li et al. (2007) used sequential mining to discover language patterns (i.e., a sequence of frequent words around an extracted keyword). The Web has become a communication platform, where users spend a large amount of time on broadcasting and interactions with others in online communities, e.g., blogging, posting, chatting, etc. Online contents are composed of specific keywords, phrases and wordings associated with frequently changed topics in communities. Keywords are extracted once a sentence is matched with a pattern from online broadcasting contents and scored with the sum of the confidence of matched patterns, i.e., , where is the remaining part of sequential pattern after is removed. The process of sequential pattern mining and keyword extraction iterates and eventually generates a large number of keywords. Experiments showed that the proposed approach can find meaningful language patterns and reduce the cost of manual data labeling, compared with traditional
statistical approaches that considered each word individually.
(4) Active learning (AL). AL is a special type of machine learning where a learning algorithm actively queries users (or some information sources) to label new data points with the desired outputs under situations where unlabeled data is abundant but manual labeling is expensive. Transductive Experimental Design is an active learning approach which can be used to select candidate keywords (for labeling and training) that are hard to predict and representative for unlabeled candidates. Let denote the union of the keyword matrix and the target dataset , and denote the union of the keyword matrix and a subset of that is chosen to be labeled (i.e., ). Define as the output function learned from the measure , i = 1, …, m, where is the weight vector, is measurement error and (label) is the binary relevance score. Let be the function values on all the available data . Then the predictive error has the covariance matrix with
\boldsymbol{C}_f = \boldsymbol{K}_T (\boldsymbol{K}_L^T \boldsymbol{K}_L + \mu \boldsymbol{I})^{-1} \boldsymbol{K}_T^T. \tag{19}
The total predictive variance on the complete data set is given as
(20)
The objective is to find a subset which can minimize the total predictive variance.
Users’ relevance feedback is another type of valuable information source for profitable keyword generation. Wu et al. (2009) proposed an efficient interactive model based on an active learning approach called transductive experimental design using relevance feedback for keyword generation in SSA. Each keyword was represented using a characteristic document consisting of top-hit search snippets for a seed keyword. In a seed’s characteristic document, top-n weighted terms were recommended as candidate keywords. The AL-based method could significantly improve the relevance of generated keywords.
(5) Bayesian online learning (BOL). Bayesian online learning replaces the true posterior distribution with a simple parametric distribution, and defines an online algorithm by a repetition of two steps (i.e., an update of the approximate posterior when a new sample arrives and an optimal projection into the parametric family) (Opper & Winther, 1999). BOL is helpful to improve the computational efficiency when estimating the unknown variables based on a large data. In SSA, advertisers use a set of keywords to describe an advertisement. Let K be the set of subscribed keywords
in the i-th ad: if the i-th ad is subscribed with keyword , then , else . Assuming that the keyword vector of an ad is sampled from one or several ad categories, such as automobiles and travel, let denote the probability that the i-th ad is subscribed by k when it belongs to category j. Then under the scheme of Bayesian online learning, each data point of ads is processed at a time, and the posterior distributions of the probability obtained after processing a data point are passed as the prior distributions for processing the next data point. Keywords can be generated to an advertiser based on keyword subscriptions of other advertisers. The probability of an unobserved keyword that is implicitly related to the i-th ad can be given as
p(s_{ik'} = 1 | \{s_{ik}\}_{k \in K}) = \sum_{i=1}^{n} \tilde{r}_{ii} \mu_{jk}, \tag{21}
where is the probability that the i-th ad belongs to category j, and is the mean of prior distribution for the keyword subscription probability .
Schwaighofer et al. (2009) provided an efficient Bayesian online learning algorithm to group advertisements into categories and applied the BOL algorithm to generate keywords. Experiments based on two advertisement datasets showed that the BOL-based algorithm is suitable for large scales of data streams because of its low computational cost.
(6) Multi-step semantic transfer analysis (MTSTA). The MTSTA-based keyword generation can yield keywords based on both their direct and indirect relevance to the seed keywords via semantic transfer. Given a seed keyword , for keyword k, if there exist n-1 intermedia keywords satisfying the conditions that k is in the candidate set of (i.e., ), is in the candidate set of (i.e., ), then the n-step relevance of and k via the intermedia keywords , can be defined as
(22)
where , , are the one-step relevance of keyword pairs.
The MTSTA-based keyword generation finds keywords with multi-step relevance that is no less than a certain threshold in the query logs (Zhang & Qiao, 2018; Zhang et al., 2021). In order to explore keywords with indirect relevance, Zhang and his colleagues explored a MTSTA-based keyword generation method by iteratively conducting co-occurrence analysis to form a hierarchal multi-step relevance tree, and developed a pruning strategy to reduce the computational consumption in generating the transfer paths.
(7) Sequence-to-sequence learning (Seq2Seq). The encoder-attention-decoder framework based on Seq2Seq learning is an end-to-end approach to sequence learning that makes minimal assumptions on the sequence structure (Sutskever et al., 2014). In keyword generation, the encoder represents an input keyword sequence with hidden representations , i.e.,
\boldsymbol{h}_t = GRU(\boldsymbol{h}_{t-1}, \boldsymbol{e}(k_t)), \tag{23}
where GRU is gated recurrent unit (Chung et al., 2014) and is the embedding of keyword .
The decoder updates state as follows:
\mathbf{s}_{t} = GRU(\mathbf{s}_{t-1}, [\mathbf{ct}_{t-1}; \mathbf{e}(\tilde{k}_{t-1})]), \tag{24}
where is the context vector defined as a weighted sum of the encoder’s hidden states, and is the embedding of a previously decoded keyword.
After obtaining the state vector , the decoder samples from the generation distribution and generates a keyword :
\tilde{k}_t \sim P(\tilde{k}_t | \tilde{k}_1, \tilde{k}_2, \dots, \tilde{k}_{t-1}, ct_t) = softmax(\mathbf{w} \cdot \mathbf{s}_t). \tag{25}
forms a sequence of generated keywords.
Zhou et al. (2019) proposed a keyword generator based on Seq2Seq learning to generate domain-specific keywords through estimating the probability , where and are the corresponding domain categories of K and , respectively. In addition, a reinforcement learning algorithm was developed to strengthen the domain constraint in the generation process. The Seq2Seq-based method could generate diverse, relevant keywords within the domain constraint.
However, statistical learning methods have some limitations, such as requiring a set of labelled keywords and the low efficiency in online computation.
3.3 Features used for Keyword Generation
Section titled “3.3 Features used for Keyword Generation”In the literature, keyword generation methods have been proposed on the basis of five major information sources to extract keywords and relationships among them, which are described as follows.
(1) Websites and Web pages: The Web has become a vital place for firms to post advertisements and other commercial information (Thomaidou and Vazirgiannis, 2011). In the meanwhile, the richness of information sources on the Web entitles advertisers to build a domain-specific keyword pool. In
particular, websites and Web pages can be used as a corpus of the source text to extract relevant keywords of interest for their online advertising campaigns. In this branch of keyword generation methods, meta-tags of Web pages are used as an important information feature. The meta-tag crawler sends one or more seed keywords to search engines and extracts a set of meta-tag keywords from Web pages in the organic list. Several popular online advertising tools (e.g., WordStream and Wordtracker) employ meta-tag crawlers to obtain a pool of meta-tag keywords and then based on it suggest relevant keywords for advertisers.
- (2) Search users’ query logs: User’s query logs with search engines timely reflect their intents (Da et al., 2011), which are significantly valuable for commercial communications and advertising. This stream of keyword generation primarily utilizes statistical information of co-occurrence relationships among keywords mining from historical query logs.
- (3) Search results snippets: One or several seed keywords are sent to search engines and resulting search result snippets are used to generate relevant keywords.
- (4) Advertisement databases and advertisers’ bidding data: Search advertisement databases and advertising logs such as bidding data are taken as inputs to obtain relevant keywords.
- (5) Domain semantics and concept hierarchy: Keyword generation methods relying on query logs mining generally ignore the semantic similarity between keywords, thus fail to suggest keywords that don’t explicitly contain seed keywords or have less co-occurrence with but are semantically related to seed keywords. To this end, the fifth category of keyword generation primarily focuses on the expansion of the keyword scope by taking advantage of conceptual hierarchies built manually or extracted either from vocabulary dictionaries/corpus (e.g., thesaurus dictionary, Wikipedia) or constructed by domain experts.
In the following, we explore features used in prior research in the five streams. Tables 4a-4e summarize input/features used in keyword generation in five research streams.
In the literature, a variety of features are used to represent keywords, which have great contributions to the effectiveness of keyword generation solutions. In keyword generation from websites and Web pages, from Table 4a, it is apparent that information retrieval oriented features are most widely used in keyword extraction from websites and Web pages. As reported by Yih et al. (2006), information retrieval oriented features and query log features are helpful for keyword generation, while linguistic features don’t seem to work. Consequently, Berlt et al. (2011) adopted features extracted from the ad collection and GM et al. (2011) took the hierarchic URL tokens as features, while omitting linguistic features. However, Li et al. (2007) found that features of language patterns can help keyword generation, and Zhou et al. (2007) inserted features such as title and keyword importance into meta keywords vector to improve keyword generation. In addition to features from Web pages as in Yih et al. (2006), Wu and Bolivar (2008) explored features from the view of retailers (e.g., eBay). In keyword generation for video advertising, Lee et al. (2009) advocated features reflecting the targeted scene situation.
Table 4a. Input/Features for Keyword Generation from Websites and Web Pages
| Features | |||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| L | C | H | M | T | U | I | R | S | L | Q | R | N | H | C | C | T | L | S | |||||||||
| Refs. | F | A | Y | F | I | R | R | L | D | C | L | E | R | 1 | O | I | D | P | F | ||||||||
| L | F | L | P | F | C | D | |||||||||||||||||||||
| Yih et al. | √ | √ | √ | √ | √ | √ | √ | √ | √ | √ | √ | ||||||||||||||||
| (2006) | |||||||||||||||||||||||||||
| Wu & | √ | √ | √ | √ | √ | √ | √ | √ | √ | ||||||||||||||||||
| Bolivar | |||||||||||||||||||||||||||
| (2008) | |||||||||||||||||||||||||||
| Berlt et al. | √ | √ | √ | √ | √ | √ | √ | √ | √ | √ | |||||||||||||||||
| (2011) | |||||||||||||||||||||||||||
| GM et al. | √ | √ | |||||||||||||||||||||||||
| (2011) | |||||||||||||||||||||||||||
| Zhou et al. | √ | √ | √ | √ | √ | √ | |||||||||||||||||||||
| (2007) | |||||||||||||||||||||||||||
| Li et al. | √ | ||||||||||||||||||||||||||
| (2007) | |||||||||||||||||||||||||||
| Lee et al. | √ | √ | √ | √ | √ | √ | √ | ||||||||||||||||||||
| (2009) |
Note: LF=Linguistic Features; CA=Capitalization; HY=Hypertext; MF=Meta related Features (e.g., meta section, meta keywords, meta description); TI=Title; URL=Uniform Resource Locator; IRF=Information Retrieval Oriented Features (e.g., TF, IDF, TF history, log value of TF and DF); RL=Relative Location (e.g., wordRatio, sentenceRatio, wordDocRatio); SDL=Sentence and Document Length; LCP=Length of the Candidate Phrase; QLF=Query Log Features (e.g., whether the word appears in the query log files as the first/interior/last word of a query keyword, whether the word never appears in any query log); RE=Root Entropy; NRC=The Number of Root Categories; H1=the Highest Section Level; CO=Co-occurrence; CID=Class ID (i.e., the category of Web pages or advertisements such as sports); TD=Text Descriptions (i.e., a detail description to the product, company or related matter of Web pages or advertisements); LP=Language Pattern; SF=Situation Features.
In online advertising, clicks demonstrate a strong relationship between queries and URLs. This makes query logs valuable information for keyword generation (Bartz et al., 2006; Fuxman et al., 2008), as illustrated in Table 4b. Meanwhile, joint search demand and keyword search demand are informative and helpful in keyword expansion and competitive strategy development (Qiao et al., 2017). Moreover, semantic and domain-specific information entitles to generate keywords that aren’t present in the corpus (Zhou et al., 2019). In addition, online store’s internal search is another source to extract keywords relevant to consumer behaviors (Scholz et al., 2019).
Table 4b. Input/Features for Keyword Generation from Query Logs
| Features | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Refs. | SL | URL | CL | SD | KO | HT | SF | DSF | NIS | |||||||
| Bartz et al. | √ | √ | ||||||||||||||
| (2006) | ||||||||||||||||
| Fuxman et al. | √ | √ | √ | |||||||||||||
| (2008) | ||||||||||||||||
| Qiao et al. | √ | √ | √ | |||||||||||||
| (2017) | ||||||||||||||||
| Zhou et al. | √ | √ | ||||||||||||||
| (2019) | ||||||||||||||||
| Scholz et al. | √ | |||||||||||||||
| (2019) |
Note: SL=Seed Links; URL=Uniform Resource Locator; CL= Clicks; SD=Search Demand (e.g., keyword search demand and joint search demand); KO=Keyword Overlap; HT=Hidden Topic; SF=Semantic Features (e.g., language model score); DSF=Domain-specific Features (e.g., domain category distribution); NIS=The Number of Internal Search Results.
In keyword generation from search result snippets, as we can see from Table 4c, TF and TFIDF, inverse TF, search snippets similarity and common search URLs are taken as predictive variables to characterize the relevance between seed terms and candidate keywords (Wu et al., 2009); and weighted title, meta keywords, meta description and anchor text with its importance inside the HTML document are used to hold semantics of a document (Thomaidou and Vazirgiannis, 2011).
Table 4c. Input/Features for Keyword Generation from Search Result Snippets
| Features | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Refs, | IRF | SSF | URL | TI | MF | AT | BT | H1 | |||||
| Wu et al. (2009) | √ | √ | √ | ||||||||||
| Thomaidou & Vazirgiannis | √ | √ | √ | √ | √ | √ | √ | ||||||
| (2011) |
Note: IRF=Information Retrieval Oriented Features (e.g., TF and TF-IDF, inverse TF); SSF=Search Snippets related Features (e.g., search snippets similarity, search result snippets); URL=Uniform Resource Locator; TI=Title; MF=Meta related Features (e.g., meta keywords, meta description); AT=Anchor Text; BT=Bold Tags; H1=the Highest Section Level.
In keyword generation from advertising databases, from Table 4d, we can notice that features are relatively scattered. In Chang et al. (2009), feature vectors based on pointwise mutual information are constructed to represent bidding keywords. Similarly, Sarmento et al. (2009) weighted the keyword cooccurrence value feature with mutual information. Schwaighofer et al. (2009) utilized the feature of ad category to suggest keywords based on the prior selected keywords with similar semantics, and Ravi et al. (2010) used keyword overlap, cosine similarity and position of the candidate keyword on the landing page.
Table 4d. Input/Features for Keyword Generation from Advertising Databases
| Features | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Reference | SOC | PMI | CO | KO | AC | KO | URL | PK | IRF | |||||
| Chang et al. (2009) | √ | √ | ||||||||||||
| Sarmento et al. (2009) | √ | √ | ||||||||||||
| Schwaighofer et al. | √ | |||||||||||||
| (2009) | ||||||||||||||
| Ravi et al. (2010) | √ | √ | √ | √ | √ |
Note: SOC=Second Order Co-bidding; PMI=Point-wise Mutual Information; CO=Co-occurrence; KO=Keyword Overlap; AC=Ad Category; KO=Keyword Overlap; URL=Uniform Resource Locator; PK=Position of the Keyword (i.e., binary features indicating whether the keyword is present in the title of the landing page, or in its body); IRF=Information Retrieval Oriented Features (e.g., a variant of TF-IDF weighting).
In keyword generation based on semantics and concept hierarchy, semantic relationships between keywords are taken into account for keyword generation (Joshi and Motwani, 2006; Abhishek and Hosanagar, 2007; Mirizzi et al., 2010; Zhang and Qiao, 2018; Zhang et al., 2021), as shown in Table 4e. Similarly, information retrieval oriented features are frequently used to improve the keyword generation results. It is notable to see that Wikipedia is widely used as a corpus to generate keywords for online advertising in various ways, e.g., creating representative vectors for semantic concepts(Amiri et al., 2008; Zhang et al., 2012a) and context vectors (Scaiano and Inkpen, 2011), ranking keyword pairs based on hypertextual links (Mirizzi et al., 2010), mining keywords based on Wikipedia graph (Welch et al., 2010; Jadidinejad and Mahmoudi, 2014).
Table 4e. Input/Features for Keyword Generation based on Semantics and Concept Hierarchy
| Features | ||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| C | I | C | W | C | E | H | U | T | H | A | H | M | S | O | A | L | Q | |
| Reference | D | R | O | F | H | I | T | R | I | E | T | L | F | P | C | C | C | L |
| F | S | L | P | F |
| Joshi | √ | √ | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| &Motwani | ||||||||||||||||||
| (2006) | ||||||||||||||||||
| Abhishek | √ | √ | ||||||||||||||||
| &Hosanag | ||||||||||||||||||
| ar (2007) | ||||||||||||||||||
| Amiri et | √ | √ | ||||||||||||||||
| al. (2008) | ||||||||||||||||||
| Chen et al. | √ | √ | ||||||||||||||||
| (2008) | ||||||||||||||||||
| Mirizzi et | √ | √ | ||||||||||||||||
| al. (2010) | ||||||||||||||||||
| Welch et | √ | √ | √ | √ | ||||||||||||||
| al. (2010) | ||||||||||||||||||
| Scaiano | √ | √ | ||||||||||||||||
| &Inkpen | ||||||||||||||||||
| (2011) | ||||||||||||||||||
| Zhang et | √ | √ | √ | √ | √ | √ | √ | √ | √ | √ | √ | √ | ||||||
| al. (2012a) | ||||||||||||||||||
| Jadidinejad | √ | |||||||||||||||||
| &Mahmou | ||||||||||||||||||
| di (2014) | ||||||||||||||||||
| Zhang and | √ | √ | ||||||||||||||||
| Qiao | ||||||||||||||||||
| (2018) | ||||||||||||||||||
| Nie et al. | √ | √ | √ | |||||||||||||||
| (2019) | ||||||||||||||||||
| Zhang et | √ | √ | ||||||||||||||||
| al. (2021) |
Note: CD=Characteristic Document (i.e., text-snippets from top 50 search-hits for the keyword); IRF=Information Retrieval Oriented Features (e.g., IDF, TF-IDF, DF, DF-ICF, DF-LCF, CF-IDF); CO=Co-occurrence; WF= Wikipedia Features (e.g., incoming links, outgoing links, redirects, candidate concepts, pool size); CH=Concept Hierarchy; EIS=External Information Sources (e.g., classical search engine results and social tagging); HT=Hidden Topics; URL=Uniform Resource Locator; TI=Title; HE=Headline (i.e., whether it is exactly the headline); AT=Anchor Text; HL=Hyperlink (i.e., whether it is part of a hyperlink of the page); MF=Meta related Features; SP=Span; OC=OneCapt; AC=AllCapt; LCP=Length of the Candidate Phrase; QLF=Query Log Features (e.g., the number of queries related to a keyword in a query log).
3.4 Evaluation Metrics for Keyword Generation
Section titled “3.4 Evaluation Metrics for Keyword Generation”In the literature, various evaluation metrics have been employed to evaluate the effectiveness of keyword generation techniques, as summarized in Table 5.
Most research used more than one metric to evaluate the proposed method. Precision, recall, and F-measure are the most commonly used metrics. Among them, precision ranks first, which has been taken into account in 14 out of 30 keyword generation studies; and recall has been considered together with precision in most situations. Precision and recall are regarded as two facets of the quality of keyword generation (Zhou et al., 2007; Berlt et al., 2011). The F-measure family of metrics combines precision and recall, e.g., F1 is the harmonic mean of precision and recall (Zhou et al., 2019). Li et al. (2007) used the F1 from both macro (i.e., the transcript level) and micro (i.e., the section level) perspectives.
Besides these three popular metrics, a rich set of metrics has been used to measure whether the generated keyword set is satisfactory, useful or effective, such as relevance (Thomaidou and Vazirgiannis, 2011), novelty (Qiao et al., 2017; Zhou et al., 2019; Zhang et al., 2021) and coverage (Chang et al., 2009; Nie et al., 2019). Joshi and Motwani (2006) developed a variant of F-measure taking into account maximizing precision, recall and nonobviousness to measure the goodness of keyword generation. Because the ultimate goal of keyword generation is to improve advertising performance and bring more profits to advertisers, performance indexes such as click-through rate are also considered as important metrics (Sarmento et al., 2009; Zhou et al., 2019).
Table 5. Evaluation Metrics for Keyword Generation
| Metric | Definition | Refs. |
|---|---|---|
| Top-n score | The number of the top-n outputs that are in the | Yih et al. (2006); Lee et al. (2009) |
| list of terms described by the annotator for that | ||
| page, e.g., Top-10 score. | ||
| Entropy | Let 𝑃(𝑘 𝑝) denote the probability that | Yih et al. (2006) |
| keyword 𝑘 is relevant to page 𝑝, | ||
| 𝑃(𝑘 𝑝) if 𝑘 𝐸𝑛𝑡𝑟𝑜𝑝𝑦 = −log2 is relevant to | ||
| 𝑝; 𝐸𝑛𝑡𝑟𝑜𝑝𝑦 = −log2(1 − 𝑃(𝑘 𝑝)), | ||
| otherwise. | ||
| Accuracy | The ratio of correctly predicted observations to | Berlt et al. (2011); Zhou et al. (2019) |
| the total observations. | ||
| 𝐴𝑐𝑐𝑢𝑟𝑎𝑐𝑦 = (𝑇𝑟𝑢𝑒 𝑝𝑜𝑠𝑡𝑖𝑡𝑖𝑣𝑒 + | ||
| 𝑇𝑟𝑢𝑒 𝑛𝑒𝑔𝑎𝑡𝑖𝑣𝑒)/(𝑇𝑟𝑢𝑒 𝑝𝑜𝑠𝑡𝑖𝑡𝑖𝑣𝑒 + | ||
| 𝑇𝑟𝑢𝑒 𝑛𝑒𝑔𝑎𝑡𝑖𝑣𝑒 + 𝐹𝑎𝑙𝑠𝑒 𝑝𝑜𝑠𝑡𝑖𝑡𝑖𝑣𝑒 + | ||
| 𝐹𝑎𝑙𝑠𝑒 𝑛𝑒𝑔𝑎𝑡𝑖𝑣𝑒). | ||
| Precision | The ratio of correctly predicted positive | Wu &Bolivar (2008); Berlt et al. |
| observations to the total predicted positive | (2011); Zhou et al. (2007); Li et al. | |
| observation. | (2007); Bartz et al. (2006); Zhou et al. |
| Recall | 𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 = 𝑇𝑟𝑢𝑒 𝑝𝑜𝑠𝑖𝑡𝑖𝑣𝑒/ (𝑇𝑟𝑢𝑒 𝑝𝑜𝑠𝑖𝑡𝑖𝑣𝑒 +𝐹𝑎𝑙𝑠𝑒 𝑝𝑜𝑠𝑖𝑡𝑖𝑣𝑒). The ratio of correctly predicted positive observations to all observations in actual class. 𝑅𝑒𝑐𝑎𝑙𝑙 = 𝑇𝑟𝑢𝑒 𝑝𝑜𝑠𝑖𝑡𝑖𝑣𝑒/(𝑇𝑟𝑢𝑒 𝑝𝑜𝑠𝑖𝑡𝑣𝑒 + 𝐹𝑎𝑙𝑠𝑒 𝑛𝑒𝑔𝑎𝑖𝑡𝑣𝑒). | (2019); Wu et al. (2009); Chang et al. (2009); Joshi &Motwani (2006); Abhishek &Hosanagar (2007); Chen et al. (2008); Mirizzi et al. (2010); Zhang et al. (2012a); Zhang et al. (2021) Berlt et al. (2011); Zhou et al. (2007); Li et al. (2007); Zhou et al. (2019); Joshi &Motwani (2006); Abhishek &Hosanagar (2007); Chen et al. (2008); |
|---|---|---|
| F1-measure | The weighted average of Precision and Recall. 𝐹1 = 2 ∗ 𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 ∗ 𝑅𝑒𝑐𝑎𝑙𝑙/(𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 + 𝑅𝑒𝑐𝑎𝑙𝑙). | Zhang et al. (2021) Li et al. (2007); Qiao et al. (2017); Zhou et al. (2019); Joshi &Motwani (2006); Chen et al. (2008); Zhang &Qiao (2018); Zhang et al. (2021) |
| NDCG | The normalized discounted cumulative gain, i.e., a measure of ranking quality. It is calculated for the sorted list of results for each of the keywords 𝑠𝑐𝑜𝑟𝑒(𝑗)−1 2 𝑘 𝑁𝐷𝐶𝐺 = 𝑁 ∑ , 𝑖=1 log2(𝑗+1) where N is the normalization constant chosen so that a perfect ordering of the results will receive the score of one; 𝑠𝑐𝑜𝑟𝑒(𝑗) is the gain value associated with the label of the item at the 𝑗-th position of the ranked list; log2(𝑗 + 1) is a discounting function that reduces the document’s gain value as its rank increases. | GM et al. (2011); Chen et al. (2008) |
| Percentage of URL Match | A measure of the efficiency of a hierarchy in matching unindexed URLs which is defined as the percentage of correctly matched URL in a given hierarchy. 𝑃𝑒𝑟𝑐𝑒𝑛𝑡𝑎𝑔𝑒 𝑈𝑅𝐿 𝑀𝑎𝑡𝑐ℎ = ∑(𝑘,𝑣)∈𝑢 1(𝑘,𝑣)𝑚𝑎𝑡𝑐ℎ𝑒𝑑ℎ𝑖𝑒𝑟𝑎𝑟𝑐ℎ𝑦 , 𝑢 where (𝑘, 𝑣) is a key-value pair for an URL, and 𝑢 is the set of all key-value pairs for an URL. | GM et al. (2011) |
| Jaccard Similarity | A measure of similarity between two keyword sets which is defined as the size of the intersection divided by the size of the union of the sample sets. ℎ𝑓𝑒𝑎𝑡𝑠∩𝑠𝑓𝑒𝑎𝑡𝑠 𝐽𝑎𝑐𝑐𝑎𝑟𝑑 𝑆𝑖𝑚𝑖𝑙𝑎𝑟𝑖𝑡𝑦 = , ℎ𝑓𝑒𝑎𝑡𝑠∪𝑠𝑓𝑒𝑎𝑡𝑠 | GM et al. (2011) |
| where 𝑠𝑓𝑒𝑎𝑡𝑠 and ℎ𝑓𝑒𝑎𝑡𝑠 are keywords and | ||
|---|---|---|
| categories from semantic and matched path in | ||
| the hierarchy. | ||
| Relevance | The fraction of relevant keywords in the set. | Fuxman et al. (2008); Thomaidou |
| &Vazirgiannis (2011); Joshi | ||
| &Motwani (2006); Mirizzi et al. | ||
| (2010); Nie et al. (2019) | ||
| Indirectness | The fraction of keywords indirectly connected | Fuxman et al. (2008) |
| to the seed set in the result set, a query 𝑞 is | ||
| indirect if 𝑞 ∉ 𝑄(𝑆), | ||
| where 𝑄(𝑆) denotes the query set directly connected to seed set 𝑆. | ||
| Novelty | The fraction of new effective keywords which | Qiao et al. (2017); Zhou et al. (2019); |
| are omitted or not found by other methods. | Zhang &Qiao (2018); Zhang et al. | |
| (2021) | ||
| Keyword | The number of generated keywords. | Scholz et al. (2019) |
| number | ||
| Impression | The number of times that an advertisement is | Scholz et al. (2019); Scaiano &Inkpen |
| displayed on results pages. | (2011) | |
| Cost per click | Advertiser’s pay for each click on the ads. | Scholz et al. (2019) |
| Conversion rate | The number of conversions divides the number | Scholz et al. (2019) |
| of total ad interactions that can be tracked to a | ||
| conversion during the same period. | ||
| Perplexity | A measurement of how well a probability | Zhou et al. (2019) |
| distribution or probability model predicts a | ||
| sample, specifically the generation quality with | ||
| respect to grammar and fluency computed by | ||
| the generation distribution in the models. | ||
| 𝐻(𝑝) 𝑃𝑒𝑟𝑝𝑙𝑒𝑥𝑖𝑡𝑦(𝑝) = 2 , | ||
| where 𝐻(𝑝) is the entropy of the distribution. | ||
| Distinct-n | The proportion of distinct n-grams to all the n | Zhou et al. (2019) |
| grams in generated keywords to evaluate the | ||
| diversity. | ||
| Coverage | The ratio between the number of suggestions | Zhou et al. (2019); Chang et al. (2009); |
| produced by a system and the maximum | Nie et al. (2019) | |
| number of allowed suggestions. | ||
| Click-through | The ratio of page views that lead to a click to | Zhou et al. (2019); Sarmento et al. |
| rate | the total number of page views. | (2009) |
| Revenue per | The revenue of a search engine per one | Zhou et al. (2019) |
| mille | thousand page views. | |
| Specificity | How general or specific were the generated | Thomaidou &Vazirgiannis (2011) |
| keywords judged by some researchers and | ||
| students. | ||
| Nonobviousness | A term not containing the seed keyword or its | Thomaidou &Vazirgiannis (2011); |
| variants sharing a common stem. | Joshi &Motwani (2006) |
| Rouge-1 score | A recall-based measure which evaluates the quality of a candidate bid phrase against all the relevant gold bid phrases. | Ravi et al. (2010) |
|---|---|---|
| where is the test landing page. | ||
| Ad display | Whether campaign ads (or very closely related | Scaiano &Inkpen (2011) |
| ads) are shown or not. | ||
| Popularity | An indicator of how pertinent the keywords are | Welch et al. (2010) |
| to advertisers. | ||
| Popularity = , | ||
| where are the keywords from source | ||
| judged relevant by at least one user, and is | ||
| the number of advertisers bidding for keyword | ||
| k. |
3.5 Summary
Section titled “3.5 Summary”In summary, all the five sources of information are valuable to build domain-specific keyword pools. In this sense, none of keyword generation methods based on a single information source can provide the perfect solution because each of them has its own advantages and shortcomings. We believe that the five branches of works complement each other, and thus it calls for a benchmark study integrating the five sources of information to generate relevant keywords.
4. Keyword Targeting
Section titled “4. Keyword Targeting”4.1 Problem Description
Section titled “4.1 Problem Description”In SSA, advertisers need to select a specific set of keywords from the domain-specific keyword pool and determine appropriate match types (i.e., broad match, phrase match and exact match) for these keywords in order to reach a specific target population. Based on selected keywords, their advertisements are displayed when users submit queries or browse Web pages. We term this process as keyword targeting following the marketing paradigm (analog to the targeting strategy), or market-level keyword optimization from the perspective of decision making. Note that keyword targeting has a more broad sense than keyword selection. The output of keyword targeting is a set of keywords and corresponding match types called the target keyword set.
Formally, given that a set of generated keywords is determined, keyword targeting can be defined as follows.
i \in \{1,2,\dots,n^{(GNT)}\}, \overline{m} \in \{0,1,2,3\}, \tag{26}
where is the keyword targeting function, is a set of selected keywords from the domain-specific keyword pool , and is the decision variable of keyword targeting, indicating whether the i-th keyword is selected in match type . Note that each keyword can be selected in one and only one match type or is not selected at all. Hence, , indicate null, exact match, phrase match and broad match, respectively.
In SSA, many keywords do not raise reliable advertising impacts, and instead occupy a large portion of the advertising expenditure. Keyword targeting can prevent advertisers from targeting wrong populations that waste their advertising resources with poor returns. Moreover, it’s critical to select keywords because consumers with different intents tend to use different types of keywords (e.g., general keywords and specific keywords). Thus, product sales via SSA highly rely on an effective set of keywords that describe advertised offerings and consumers’ intents.
However, it’s not a straightforward task to select a set of right keywords from a large pool with millions of available keywords (Bartz et al., 2006). Even if the size of the keyword pool is relatively small, it’s unwise to bid on all keywords simultaneously (Ji et al., 2010). Thus, keyword targeting is one of the most crucial steps in search advertising optimization. In effect, keyword targeting is a cornerstone process for all SSA stakeholders (i.e., search engines, advertisers, and consumers) pursuing the best combination of advertising presentation, promotion, and discovery (Thomaidou and Vazirgiannis, 2011). Moreover, the keyword targeting process needs to take into account mechanisms behind search engines, product/service features, as well as characteristics of the target population.
There are two tradeoffs in the keyword targeting process (Rusmevichientong and Williamson, 2006). First, there is a tradeoff between selecting a limited number of profitable keywords versus selecting an extensive set of keywords (i.e., the more-less tradeoff). The former will not spend the entire
budget, while the latter will deplete the budget quickly, in turn which might lose opportunities to receive clicks and conversions that may arrive later. Second, advertisers must balance the tradeoff between selecting known keywords that yielded high profits in the past versus selecting previously unused keywords whose performance indexes such as click-through probabilities can be learnt in future advertising campaigns (i.e., the exploitation-exploration tradeoff) 1 .
In the literature, keyword targeting has been treated as two independent problems, namely keyword selection and keyword match. In the following, we discuss these two research streams in terms of techniques, features and evaluation metrics.
4.2 Techniques for Keyword Targeting
Section titled “4.2 Techniques for Keyword Targeting”4.2.1 Keyword Selection
Section titled “4.2.1 Keyword Selection”1
Given a certain amount of budget, advertisers try to spend their money on the most profitable keywords. In a highly uncertain environment such as SSA (Yang et al., 2013; Li and Yang, 2020), identifying a set of profitable set of keywords becomes even more challenging for advertisers (Yang et al., 2019).
In the literature, techniques used for keyword selection, include feature selection, adaptive approximation, mixed integer optimization, technique for order of preference by similarity to ideal solution (TOPSIS) and the mean-variance model, as summarized in Table 6a. Table 7a presents notations used in keyword selection.
Table 6a. Techniques for Keyword Selection
| Category | Approach | Refs. |
|---|---|---|
| Feature selection | Information gain | Kiritchenko &Jiline (2008) |
| Symmetrical uncertainty | Kiritchenko &Jiline (2008) | |
| Chi-square statistics | Kiritchenko &Jiline (2008) | |
| Odds ratio | Kiritchenko &Jiline (2008) | |
| Precision on the positive class | Kiritchenko &Jiline (2008) | |
| Optimization | Adaptive approximation | Rusmevichientong &Williamson |
| (2006) | ||
| Mixed integer optimization | Zhang et al. (2014b) | |
| Technique for order of preference by | Arroyo-Cañada &Gil-Lafuente | |
| similarity to ideal solution | (2019) | |
| Mean-variance model | Symitsi et al. (2022) |
In the reinforcement learning literature, it is cast as balancing the exploitation of known good options and the exploration of unknown options that might be better than known options.
Table 7a. Notations in keyword selection
| Terms | Definition |
|---|---|
| The number of query keywords | |
| The absence of | |
| A category set | |
| The categories in other than | |
| The cost-per-click for keyword | |
| The click-through rate for keyword | |
| The expected profit from keyword | |
| The probability that keyword is queried | |
| The upper bound of the expected number of queries for keyword | |
| и | The mean of the total number of queries that arrive in a period |
| The largest prefix for keyword selection | |
| An integer random variable in period | |
| An independent binary random variable in period t | |
| The probability that , i.e., | |
| G t | The largest index for keyword selection in period t |
| The number of impressions that keyword receives in period | |
| The number of clicks that keyword receives in period | |
| The cumulative number of impressions for keyword in periods from 1 to | |
| The cumulative number of clicks for keyword in periods from 1 to | |
| The estimated click-through rate (CTR) for keyword in period | |
| The auctions triggered by keyword | |
| θ | An auction |
| A set of keyword for the l -th ad-group | |
| The average true value of a click for the l -th ad-group | |
| The bid price for keyword in the -th ad-group | |
| The impression probability for the -th ad-group in auction | |
| The average click-through rate for the -th ad-group | |
| The floor bid price | |
| The winning score of auction | |
| The relevance score of the -th ad-group in auction | |
| The performance value of the -th set of keywords under the -th evaluation | |
| criterion | |
| The weight of the j -th criterion | |
| The weighted normalized value of the -th set of keywords under the -th | |
| evaluation criterion | |
| A + | The positive ideal solution |
| A - | The negative ideal solution |
| J | A benefit criteria index |
| J’ | A cost criteria index |
| An alternative from the positive ideal solution | |
| An alternative from the negative ideal solution | |
| The relative closeness | |
| The characteristic membership functions | |
|---|---|
| The percentage allocation of the budget for the i -th keyword | |
| The growth in profit for the i -th keyword |
(1) Feature selection (FS). By assuming that keywords can be optimized based on their historic performance, Kiritchenko & Jiline (2008) applied a set of feature selection techniques to a set of words (i.e., search terms) combinations (i.e., multi-word phrases) comprising historical users’ queries to optimize keyword selection. More specifically, the past performance of individual keywords and all possible multi-word keywords is analyzed, then feature selection techniques were used to sort phrases according to their effectiveness extracted from the historical data, and then a set of profitable phrases was selected. Let denote the number of query keywords (i.e., single words and word combinations), denote a sequence of non-space characters, represent the absence of , and denote categories in other than . The relevance of to category can be measured by a function such as information gain, chi-square statistic, symmetrical uncertainty, odds ratio, and precision on the positive class, which are described as follows.
Information gain is the amount of information gained about a random variable, which can tell how important a given attribute is in a feature vector. The information gain-based relevance of to category is given as , where , and .
Chi-square statistic is a measure of the difference between observed and expected frequencies of outcomes of a set of events or variables. The Chi-square-based relevance of to category is given as , where is the probability that keywords containing is related to and keywords excluding is related to categories other than ; is the probability that keywords containing is related to categories other than and keywords excluding is related to .
Symmetrical uncertainty measures the relevance between a feature and the class label. The symmetrical uncertainty-based relevance of to category is given as .
Odds ratio is a measure of association between an exposure and an outcome, which represents the odds that an outcome will occur given a particular exposure, compared to the odds of the outcome
occurring in the absence of that exposure. The odds ratio-based relevance of to category is given as
Precision on the positive class measures the fraction of keywords containing word which is relevant to category , i.e., .
Feature selection techniques discussed above showed similar performance. Among them, symmetrical uncertainty performed the best by a slight margin and the precision on the positive class technique is a little inferior to others. In general, feature selection techniques could not only identify profitable keywords, but also discover more specific phrases.
(2) Adaptive approximation (AA). In light of the more-less tradeoff and the exploitation-exploration tradeoff, Rusmevichientong and Williamson (2006) developed adaptive approximation algorithms to solve the keyword selection problem.
In the static case where click-through rates of keywords are known, keyword selection can be modeled as a stochastic knapsack problem with query arrival as a random variable. Let , , denote the cost-per-click, click-through rate and expected profit for keyword , respectively. Let denote the probability that is queried and u denote the mean of the total number of queries that arrive in a period. In order to develop an efficient approximation algorithm for keyword selection, keywords are sorted in a prefix-orderings, i.e., the descending order of profit-to-cost ratio, i.e., and the expected number of queries for (i.e., ) is at most ( , , and ). Then a near-optimal approximation algorithm was developed to choose the largest prefix which satisfies
(27)
That is, the near-optimal selected set includes keywords with prefix-orderings , whose cost is close to the budget.
In the dynamic case where the click-through rates are not known, keyword selection was formulated as a multi-armed bandit problem. An improved adaptive approximation algorithm was developed to select a bandit (i.e., a subset of keywords) in each time period based on their past observations that yield near-optimal profits. In this algorithm, the click-through rates for are updated according to impressions and clicks that the keyword receives in period t: as for all i,
:= , := , and estimated click-through rate , if ; , otherwise. Let denote an integer randomly chosen uniformly from the set in period t and denote an independent binary random variable with and , where . Similarly, keywords were sorted in the descending order of profit-to-cost ratio. Keywords with indexes are selected as their target set, where , if ; , otherwise; and is the index such that
(28)
The AA algorithm outperformed multi-armed bandit algorithms by increasing about 7% profits, and the expected profit could converge to a near-optimal level.
(3) Mixed integer optimization (MIP). MIP adds an additional condition that at least one of the variables can only take integer values on the basis of linear programming which maximizes (or minimizes) a linear objective function subject to one or more constraints. In the SSA context, Zhang et al. (2014b) modeled keyword selection as a MIP problem, which maximizes an advertiser’s revenue and the relevance of selected keywords, while minimizing the keyword competitiveness, with constraints of the lower and the upper bounds of bidding prices on a set of keywords and the limited budget for an ad-group.
Given an ad-group l, a keyword set for l (i.e., ) can be obtained by filtering out keywords whose relevance scores are less than a certain threshold. Let denotes auctions triggered by keyword . In an auction , the expected revenue of ad-group l from is , where is the average true value of a click, is the bidding price, is the impression probability, and is the average CTR. Let denote the indicator variable for keyword selection if is selected; otherwise . In order to maximize the total expected revenue, the objective is given as
\max_{x_i^{(SEL)}, b_{l,i}} \sum_{k_i \in K_l} \left\{ c_i \sum_{\vartheta \in \Theta_i} (v_l - b_{l,i}) \mathcal{d}_{l,\vartheta} c_l x_i^{(SEL)} \right\}, \tag{29}
where is the impression confidence based on keyword competitiveness.
Constraints are the budget of an ad-group, and the lower bound and the upper bound of bidding prices, which are given as
s.t.\sum_{k_{i}\in K_{l}}\left\{\sum_{\vartheta\in\Theta_{i}}b_{l,i}d_{l,\theta}c_{l}x_{i}^{(SEL)}\right\}\leq B_{l}, \text{ with } \max_{\vartheta\in\Theta_{i}}\left\{b_{\epsilon},\frac{\omega_{\vartheta}}{r_{l,\vartheta}}\right\}\leq b_{l,i}\leq v_{l}, \tag{30}
where is the floor price, is the winning score of auction , and is the relevance score of ad-group l in .
In order to select relevant yet less-competitive keywords and put optimal bidding prices over these keywords, Zhang et al. (2014b) constructed a mixed integer programming model and solved it by iteratively conducting binary integer programming and sequential quadratic programming until convergence. Simulation experiments showed that the MIP-based keyword selection method is capable of increasing impressions, expected clicks, advertiser’s revenue, as well as search engine’s revenue.
(4) Technique for order of preference by similarity to ideal solution (TOPSIS). TOPSIS is a multi-criteria decision analysis method based on the concept that the chosen alternative should have the shortest distance from the positive ideal solution (PIS) and the furthest distance from the negative ideal solution (NIS) (Garc á-Cascales and Lamata, 2012). Given several alternative sets of keywords for an advertising campaign, let denote the performance value of the i-th set of keywords under the j-th evaluation criterion (e.g., advertising inventory, impressions per week, clicks per week, opportunity to see, click-through rate, cost per click, and revenue), i = 1, 2, …, n, j = 1, 2, …, m, and denote the weight of the j-th criterion. The weighted normalized value of the i-th set of keywords under the j-th evaluation criterion is calculated as
(31)
The positive ideal value set and the negative ideal solution are determined as
A^{-} = \{v_{1}^{-}, \dots, v_{m}^{-}\} = \left\{ (\min_{i} v_{ij}, j \in J) (\max_{i} v_{ij}, j \in J') \right\}, \tag{32}
where J is associated with benefit criteria, and J’ is associated with cost criteria.
Then the separation of an alternative from the positive ideal solution (PIS) and the negative ideal solution (NIS) is given as
and (33)
Then the relative closeness to the ideal solution can be expressed as , and keywords can be selected according to rank in descending order. Arroyo-Cañada & Gil-Lafuente (2019) proposed a fuzzy asymmetric TOPSIS-based keyword selection method. Specifically, this method introduced fuzzy indicators by replacing with fuzzy numbers or linguistic values, and incorporated characteristic membership functions and to asymmetrically penalize the lack of frequency and soften light excesses for the j-th criterion, i.e., .
(5) Mean-variance model (MVM). MVM selects the most efficient portfolio by analyzing expected returns (mean) and standard deviations (variance) of various portfolios (Markowitz, 1952). The efficient frontier of keyword portfolios can be obtained as follows.
s. t., \mu_p = \sum_{i=1}^{n_k} w_i E(z_i), \sum_{i=1}^{n_k} w_i = 1, w_i \ge 0, \tag{34}
where and are the percentage allocation of the budget and the growth in profit for the i-th keyword, respectively.
Symitsi et al. (2022) explored keyword portfolios by examining the risk-adjusted keyword performance, and selected unrelated and negatively related keywords into keyword portfolios for the goal of diversification. The MVM-based keyword selection method outperformed advertisers’ heuristic rules used in practice.
In summary, current keyword selection methods can recognize profitable keywords under budget constraints by balancing the tradeoff between costs and revenues. However, the dynamic feature of SSA has been ignored in prior studies on keyword selection, which assumes that keyword costs and revenues are unchangeable (Rusmevichientong and Williamson, 2006; Kiritchenko and Jiline, 2008).
4.2.2 Keyword Match
Section titled “4.2.2 Keyword Match”In SSA, advertisers need to make another important choice over keyword match types, including exact match, phrase match and broach match, when making keyword targeting decisions (Dhar and Ghose, 2010). Keyword match type controls when advertisements will be shown to consumers, which in turn determines the target population of potential consumers. Therefore, keyword match is a critical variable in SSA (Du et al., 2017; Yang et al., 2021).
In the literature on keyword match, current research primarily focused on broad match, which falls into two research streams. One stream explored broad match mapping mechanisms to help advertisers identify similar keywords, increase the advertising reach and reduce the campaign management burden, by using regression SVM, max-margin voted perceptron and distributed language model (Radlinski et al., 2008; Gupta et al., 2009; Grbovic et al., 2016). Another stream addressed optimization problems in broad match, using graph model and game-theoretic model (Singh and Roychowdhury, 2008; Amaldoss et al., 2016). Techniques used for keyword match in the literature are summarized in Table 6b. Table 7b presents notations used in keyword match.
Table 6b. Techniques for Keyword Match
| Category | Approach | Refs. |
|---|---|---|
| Learning model | Support vector regression | Radlinski et al. (2008) |
| Max-margin voted perceptron | Gupta et al. (2009) | |
| Distributed language model | Grbovic et al. (2016) | |
| Graph model | / | Singh &Roychowdhury (2008) |
| Game theory | Game-theoretic model | Amaldoss et al. (2016) |
Table 7b. Notations in keyword match
| Terms | Definition | |
|---|---|---|
| 𝑥𝑖 | The 𝑖-th training sample | |
| 𝑦𝑖 | The target value of the 𝑖-th training sample | |
| 𝜏 | The intercept of a prediction | |
| ð | A threshold | |
| ′ 𝒙 = 𝑓(𝑘 ) → 𝑘 | A feature vector encoding various properties of an advertisement’s impressions on a | |
| ′ broad match keyword 𝑘 shown in a context containing keyword 𝑘 | ||
| 𝒸 | ′ A binary variable indicating whether keyword 𝑘 is clicked | |
| 𝒸̂ | The click probability of a broad match keyword | |
| 𝒘 | A weight vector | |
| 𝑛𝒘𝑖 | The number of iterations that the 𝑖-th weight vector don’t change | |
| 𝒘𝑎𝑣𝑔 | A moving average weight vector | |
| 𝜁 | An amnesia rate | |
| 𝒮̂ | A set of search sessions | |
| 𝓈 | , … , 𝒶𝑁) ∈ 𝒮̂ A search session 𝓈 = (𝒶1 | |
| 𝒗𝒶𝑛 | A multiple dimensional real-valued representation for a unique action 𝒶𝑛 | |
| 𝜉 | The length of the relevant context for action sequences | |
| Φ | A vocabulary set for unique actions in the dataset | |
| 𝑛𝐾 | The number of keywords in set 𝐾 | |
| 𝑛𝐴𝑑𝑒𝑟 | The number of advertisers who are interested in the keywords | |
| 𝑛𝐴𝑆 | The maximum number of ad-slot available | |
| ℰ | The valuation matrix with entries 𝜀𝑗,𝑘 | |
| 𝜀𝑗,𝑘 | The product of true value and quality score of advertiser 𝑎𝑑𝑒𝑟𝑗 for keyword 𝑘 |
| 𝐵𝑗 | The daily budget for advertiser 𝑎𝑑𝑒𝑟𝑗 |
|---|---|
| d𝑘 | The daily search demands of keyword 𝑘 |
| 𝐴𝑑𝑒𝑟 | A set of advertisers |
| 𝒮 | A set of edges connecting advertisers and keywords in broad match graph |
| 𝒮′ | The extension set of edges, 𝒮 ⊂ 𝒮′ |
| 𝐺 | A graph 𝐺 = (𝐴𝑑𝑒𝑟,𝐾, 𝒮) |
| 𝐺′ | A broad-match graph for graph 𝐺 |
| 𝐸𝑈 | The expected utility |
(1) Support vector regression (SVR). SVR is a supervised learning model for regression analysis (Scholkopf, 1999). Given a training sample with a target value and the prediction of the innerproduct plus intercept 〈, 〉 + for that sample, SVR is defined as
where ð is a threshold.
Radlinski et al. (2008) presented a two-stage method combining exact match and broad match to recommend advertisements, with the objective of optimizing both the advertising relevance and the advertising revenue for search engines simultaneously. At the first stage, an ad query substitution table was built using external knowledge sources in an offline setting. Specifically, they fixed a large set of sufficiently frequent ad queries, and used SVR to learn weights for features in a combined linear function computing the final score for each query substitute. At the second stage, advertisements retrieval was performed by finding advertisements whose keywords exactly match the substituted query. The SVR-based method combines merits of both broad match (i.e., flexibility) and exact match (i.e., computational efficiency).
(2) Max-margin voted perceptron (MMVP). MMVP is a discriminative online classifier performing well on high-dimensional learning tasks (Freund & Schapire, 1999). Assume that for every keyword (), there exists a set of broad-match keywords ({′}) that can be identified using some similarity functions. The problem of identifying broad match for a given keyword is equal to predicting the click probability of broad match keyword. Let = ( → ′ ) denote a feature vector encoding various properties of the impression of an advertisement on a broad match keyword ′ shown in a context containing keyword , and ∈ {−1, +1} denotes a binary variable indicating whether ′ is clicked. The dataset of training instances for MMVP in SSA is constructed as {( = ( →
. The MMVP algorithm starts with an initial zero weight vector , and predicts the click probability of a broad match keyword, i.e., . If the prediction is different from the label c, it updates the weight vector , otherwise is not changed. The process runs repeatedly through all the training instances. In the process, the number of iterations that each weight vector doesn’t change is counted as . Then the predicted click probability of a broad keyword k’ can be computed as .
In order to effectively capture the fluid SSA environment, Gupta et al. (2009) developed an amnesiac averaged perceptron algorithm by incorporating the exponentially weighted moving average into the MMVP and exploiting implicit feedback (i.e., advertising click-through logs) to identify high-quality broad matches for a given keyword. Specifically, besides , another moving average weight vector is initialized as 0; for each , after updating , is updated as , where is the amnesia rate indicating that the weight vectors observed in the past are less influential than the most recent one. Finally, the moving average weight vector is used to conduct the click probability prediction. The MMVP-based matching method can quickly adjust to rapidly-changing distributions of keywords, advertisements and user behaviors.
(3) Distributed language model (DLM). DLM learns word representations in a low-dimensional continuous vector space using a surrounding context of a word in a sentence, where in the resulting embedding space, semantically similar words are close to each other (Mikolov et al., 2013). In SSA, DLM can be used to learn ad and query representations in a low-dimensional space and solve the query-ad matching problem (Grbovic et al., 2016). Given a search session set , is an uninterrupted sequence of user’s actions comprising queries, ad clicks, and link clicks. The search embedding learns a D-dimensional real-valued representation for each unique action by maximizing the following objective function
where and are the input and output vector representations of user’s actions, respectively, is the length of the relevant context for action sequences, and is a vocabulary set for unique actions in the dataset consisting of queries, ads, and links.
The optimization can be done via stochastic gradient ascent. Grbovic et al. (2016) presented a DLM-based matching method through semantic embeddings of search queries and advertisements. This method delineates the temporal context of action sequences, where actions with similar contexts will have similar representations, and reduces the complex broad match problem to a trivial K-nearestneighbor search between queries and ads in the joint embedding space. The DLM-based method can gain a good performance in terms of relevance, coverage and incremental revenue.
(4) Graph model (GM). Broad match graph is a weighted bipartite graph between a set of advertisers and a set of keywords. Let denote the total number of keywords, denote the total number of advertisers, denote the maximum number of ad-slot available, ℰ denote the valuation matrix where , is the product of true value and quality score of advertiser for keyword , is the daily budget for and d denote the daily search demands of . Given instance parameters (, , , ℰ = (,), = (), d = (d)), a bipartite graph = (,, ) is constructed, with vertex sets (i.e., the advertiser set and the keyword set ) and the edge set (i.e., = {( , ): ∈ , ∈ , , > 0}). Each edge (, ) ∈ has a weight ,, each ader-node ∈ has a weight , and each keyword-node ∈ has a weight d. Then, given instance parameters (, , , ℰ′, , d) where ℰ ⊂ ℰ′, ′ = (,, ′) is a broad-match graph for = (, , ), if ⊂ ′ and , ′ = , for all (, ) ∈ .
Based on the broad match graph, Singh and Roychowdhury (2008) studied dynamics of bidding over various related keywords, and discussed two broad match scenarios and the extent of auctioneer’s control on budget splitting. When the quality of broad match is good, the auctioneer (i.e., search engine) could always improve the revenue by judiciously using broad match.
(5) Game-theoretic model (GTM). GTM uses game theory (i.e., mathematical models of strategic interactions among rational agents) to predict actions of either cooperative or competitive individuals (Moorthy, 1985). Amaldoss et al. (2016) applied a game-theoretic model to analyze advertisers’ expected utilities in four possible cases, i.e., both advertisers use broad match (,), advertiser 1 uses exact match but advertiser 2 uses broad match (, ), advertiser 1 uses broad match whereas advertiser 2 uses exact match (, ), and both advertisers use exact match (, ), under an assumption that there are two risk-neutral advertisers bidding for a keyword. Their analysis disclosed that a) search engine profits increase when advertisers adopt broad match; b) search engines should increase the accuracy of broad match up to the point where advertisers are willing to adopt.
Effective keyword match can improve both the relevance and monetization of SSA campaigns by controlling advertisers’ reach (Gupta et al., 2009). Current research on keyword match concentrated on various themes: identifying high-quality broad match mappings (Gupta et al., 2009; Grbovic et al., 2016), allocating budget over several broad match scenarios (Singh and Roychowdhury, 2008), optimizing the relevance of keyword match (Radlinski et al., 2008) and examining the strategic role of broad match (Amaldoss et al., 2016). Nonetheless, in order to obtain an optimal solution for keyword targeting, keyword match should be addressed together with keyword selection.
4.3 Input Features for Keyword Targeting
Section titled “4.3 Input Features for Keyword Targeting”Table 8a summarizes input/features used in keyword selection techniques reported in the literature. From Table 8a, we can see that historical performance is the main source for feature extraction in keyword selection, e.g., profit-to-cost (Rusmevichientong and Williamson, 2006), cost per click and clicks (Arroyo-Cañada and Gil-Lafuente, 2019; Symitsi et al., 2022). In machine learning based keyword selection, keyword combinations are taken as features (Kiritchenko and Jiline, 2008) and extracted from queries and keywords, combined with human judged labels (Zhang et al., 2014b).
Table 8a. Input/Features used for keyword selection
| Features | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Refs. | PCR | WC | EV | BP | CPC | IMP | CTR | VPA | RS | CL | OS | RAP | CPR |
| Rusmevichientong | √ | ||||||||||||
| &Williamson (2006) | |||||||||||||
| Kiritchenko &Jiline | √ | √ | |||||||||||
| (2008) | |||||||||||||
| Zhang et al. (2014b) | √ | √ | √ | √ | √ | √ | |||||||
| Arroyo-Cañada | √ | √ | √ | √ | √ | √ | |||||||
| &Gil-Lafuente | |||||||||||||
| (2019) | |||||||||||||
| Symitsi et al. (2022) | √ | √ | √ | √ | √ |
Notes: PCR=Profit-to-Cost Ratio; WC=Words Combinations; EV=Engaged Visit (i.e., the time spent at the website multiplied by the number of pages visited); BP=Bid Price; CPC=Cost Per Click; IMP=Impression (e.g., impression per week, impression probability based on bid price, impression confidence based on competitiveness); CTR=Click-Through Rate; VPA=Value Per Ad-group; RS=Relevance Score (calculated based on the query-ad similarity, semantic similarity, taxonomy, and user query time); CL=Clicks; OS=Opportunity to See; RAP=Relevance of the Advertising Place; CPR=Cots-Per-Reservation.
Table 8b summarizes input/features used in research on keyword match. In keyword targeting, match type is often considered as an important decision factor where optimization and equilibrium analysis are conducted (Singh and Roychowdhury, 2008; Amaldoss et al., 2016). Feature selection provides considerable improvement in keyword match (Gupta et al., 2009). For keyword match optimization, features extracted from search sessions are used to learn low-dimensional continuous representations of queries and advertisements (Grbovic et al., 2016). Moreover, features such as lexical similarity, semantic similarity and revenue describe match quality between the query and candidate substitution (Radlinski et al., 2008).
Table 8b. Input/Features used for Keyword Match
| Features | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| M | C | D | S | C | K | S | C | C | I | B | L | S | K | S | P | |
| Refs. | F | O | E | S | T | I | Q | L | I | A | C | S | S | O | D | R |
| M | R | D | F | F | F | |||||||||||
| Gupta et al. (2009) | √ | √ | √ | √ | √ | √ | ||||||||||
| Grbovic et al. (2016) | √ | √ | √ | |||||||||||||
| Singh &Roychowdhury (2008) | √ | √ | ||||||||||||||
| Radlinski et al. (2008) | √ | √ | √ | √ | √ | √ | ||||||||||
| Amaldoss et al. (2016) | √ |
Note: MF=Match related Feature (e.g., broad match mapping, the accuracy of broad match bid); CO=Cooccurrence; DE=Densified (i.e., the local structure of similarity graphs); SSM=Syntactic Similarity Measures (e.g., string edit distance, the presence of one keyword as a substring inside the other); CTR=Click-Through Rate; KID=Keyword-ID (e.g., the total number of bidded keywords for the original and broad-match keywords); SQ=Sequences of Queries; CL=Clicks (ad clicks, search link clicks); CI=Contextual Information (e.g., dwell time and skipped ads); IA=Information Asymmetry; BC=Budget Control (i.e., the extent of auctioneer’s control on the budget splitting); LSF=Lexical Similarity Features (i.e., share words, word distance, cosine and trigram cosine); SSF=Semantic Similarity Features (i.e., max match score, abstract cosine and taxonomy similarity); KO=Keyword Overlap; SD=Search Demand; PRF= Potential Revenue Features (i.e., max bid, second bid).
4.4 Evaluation Metrics for Keyword Targeting
Section titled “4.4 Evaluation Metrics for Keyword Targeting”Evaluation metrics that we identified in the reviewed articles on keyword targeting (i.e., keyword selection and match) are presented in Table 9. As keyword decisions move deeper into the lifecycle framework from keyword generation to keyword targeting, evaluation metrics become closer to the ultimate goal of keyword decisions for advertisers, i.e., revenue/profit maximization. In particular, the revenue/profit is the most common evaluation metric in keyword targeting (either keyword selection or keyword match) (Rusmevichientong and Williamson, 2006; Singh and Roychowdhury, 2008; Radlinski et al., 2008; Gupta et al., 2009; Zhang et al., 2014b; Symitsi et al., 2022), while the most commonly used metrics in keyword generation (e.g., precision, recall and F-measure) disappear. Moreover, it appears that keyword selection and keyword match emphasize different metrics. That is, keyword selection highlights keyword/advertising performance indexes such as impressions, expected clicks, CPC, and advertising cost, while keyword match accentuates metrics such as NDCG, relevance, and coverage (Radlinski et al., 2008; Gupta et al., 2009; Grbovic et al., 2016).
Table 9. Evaluation Metrics for Keyword Targeting
| Metrics | Definition | Research | Refs. | |||
|---|---|---|---|---|---|---|
| Stream | ||||||
| Revenue/Profit | An advertiser’s or search engine’s economic | Keyword | Rusmevichientong | |||
| benefits. | selection | &Williamson (2006); | ||||
| Kiritchenko &Jiline (2008); | ||||||
| Zhang et al. (2014b); | ||||||
| Symitsi et al. (2022) | ||||||
| Keyword | Gupta et al. (2009); Singh | |||||
| match | &Roychowdhury (2008); | |||||
| Radlinski et al. (2008) | ||||||
| AUC | The area under the ROC curve representing | Keyword | Kiritchenko &Jiline (2008) | |||
| the degree or measure of separability. | selection | |||||
| Keyword | Grbovic et al. (2016) | |||||
| match | ||||||
| Impressions | The number of times that an advertisement | Keyword | Zhang et al. (2014b); | |||
| is displayed on results pages. | selection | Symitsi et al. (2022) | ||||
| Expected clicks | The number of times that the ads get clicked | Keyword | Zhang et al. (2014b) | |||
| when shown for that keyword. | selection | |||||
| 𝐸𝑥𝑝𝑒𝑐𝑡𝑒𝑑 𝑐𝑙𝑖𝑐𝑘𝑠 = 𝐴𝑣𝑒𝑟𝑎𝑔𝑒 𝐶𝑇𝑅 ∗ | ||||||
| 𝐼𝑚𝑝𝑟𝑒𝑠𝑠𝑖𝑜𝑛. | ||||||
| Cost per click | An advertiser’s pay for each click on the | Keyword | Zhang et al. (2014b) | |||
| ads. | selection | |||||
| Advertising | The sum of all keyword costs which equals | Keyword | Zhang et al. (2014b) | |||
| cost | to the search engine revenue. | selection | ||||
| Brand | The awareness about the brand related to | Keyword | Arroyo-Cañada &Gil | |||
| awareness | impressions per week, cookies per week, | selection | Lafuente (2019) | |||
| opportunity to see and relevance. | ||||||
| Website Traffic | The traffic to the corporative website most | Keyword | Arroyo-Cañada &Gil | |||
| lined with clicks, click-through rate and cost | selection | Lafuente (2019) | ||||
| per click. | ||||||
| Rankings of | The keyword set rankings of proximities to | Keyword | Arroyo-Cañada &Gil | |||
| proximities | the ideal solution. | selection | Lafuente (2019) | |||
| Risk | The performance of selected keywords in | Keyword | Symitsi et al. (2022) | |||
| standard deviation of the popularity growth. | selection | |||||
| Sharpe ratio | The difference between investment returns | Keyword | Symitsi et al. (2022) | |||
| and the risk-free return, divided by the | selection | |||||
| standard deviation of investment returns. | ||||||
| 𝑆ℎ𝑎𝑟𝑝𝑒 𝑟𝑎𝑡𝑖𝑜 = (𝑅𝑝 − 𝑅𝑓)/𝜎𝑝, |
| where is the return of portfolio, is the risk-free rate, and is the standard deviation of the portfolio’s excess return. | |||
|---|---|---|---|
| Keyword number | The number of selected keywords. | Keyword selection | Symitsi et al. (2022) |
| LogLoss | Log-loss over a test dataset. where is the click-through rate (CTR), and is one of the replacements given by the broad match mapping for the original keyword . | Keyword match | Gupta et al. (2009) |
| LogL-Lift | The difference between the model’s log-likelihood and the entropy of the test set. | Keyword match | Gupta et al. (2009) |
| Relative CTR | The CTR of the subset of the test set that overlaps with the mapping. , where is the click-through rate (CTR), and is one of the replacements given by the broad match mapping for the original keyword . | Keyword match | Gupta et al. (2009); Grbovic et al. (2016) |
| Coverage | The number of items where model made any prediction divides the number of total items, specifically the coverage of the mapping. where is one of the replacements given by the broad match mapping for the original keyword . | Keyword match | Gupta et al. (2009); Grbovic et al. (2016) |
| Macro NDCG | A measure of how well the ranked scores align with the ranked editorial grades using as NDCG labels and position discounting of log. | Keyword match | Grbovic et al. (2016) |
| Relevance | The relevance of an advertisement and a query substitution. | Keyword match | Radlinski et al. (2008) |
| Utility (for search engine) | The expected utility for advertiser 1 choosing -type match and advertiser 2 choosing -type match. | Keyword match | Amaldoss et al. (2016) |
4.5 Summary
Section titled “4.5 Summary”In summary, as we were aware of the existing literature, there are few studies on keyword targeting (Li and Yang, 2022). Instead, scholars have tried to address either keyword selection or determination of
keyword match types separately. We argue that it’s of necessity to address the keyword selection and keyword match problems in an integrated way, in order to help advertisers effectively reach the targeted population via SSA campaigns.
5. Keyword Assignment and Grouping
Section titled “5. Keyword Assignment and Grouping”5.1 Problem Description
Section titled “5.1 Problem Description”SSA is a structural advertising form, which is distinctly different from the flattened structure of traditional advertising (Yang et al., 2017). For advertisers who wish to promote their products or services via SSA, they need to design one or more advertising campaigns, and create one or more adgroups for each campaign (we call this the basic SSA structure) (Chatwin, 2013), as shown in Figure 2. Given that a set of keywords is determined by the keyword targeting process (i.e., the target keyword set), an advertiser needs to assign a subset of target keywords to each campaign, and then each campaign-specific set of keywords also needs to be grouped into several subsets, one of which corresponds to an ad-group. Keyword assignment is conducted at the campaign level, and keyword grouping is made at the ad-group level. The output of this step is the keyword structure.
From an operational perspective, keyword assignment and grouping is one of the most critical keyword decisions throughout the entire life cycle of SSA campaigns (Yang et al., 2019; Whitney, 2022). In SSA, advertising campaigns with one or several ad-groups are run to fulfill promotional goals, which constitute the search advertising structure and serve as the basic units for daily advertising operations. Organizing keywords according to search advertising structures allows advertisers to better manage advertising activities (Rutz et al., 2012) and track the effectiveness of their advertising efforts (Hou, 2015). Moreover, keyword assignment and grouping helps advertisers display the ads to the right consumers (Gopal et al., 2011; Polato et al., 2021).
Formally, given that a set of keywords and corresponding match types are determined, keyword assignment and grouping can be defined as follows.
(1) Keyword assignment:
Section titled “(1) Keyword assignment:”
i \in \{1, 2, \dots, n^{(TGT)}\}, j \in \{1, 2, \dots, n_{campaign}\}, \tag{37}
where is the keyword assignment function, is the set of keywords assigned to the j-th campaign, and is the decision variable of keyword assignment, indicating whether the i-th keyword is assigned to the j-th campaign.
(2) Keyword grouping:
Section titled “(2) Keyword grouping:”
where is the keyword grouping function, is the set of keywords grouped to the l-th adgroup of the j-th campaign, and is the decision variable of keyword grouping, indicating whether the i-th keyword is grouped into the l-th ad-group of the j-th campaign. Notations used in keyword assignment and grouping are presented in Table 10.
Table 10. Notations in keyword assignment and grouping
| Terms | Definition |
|---|---|
| The total number of search demands of the i -th keyword in a search market | |
| The click-through rate (CTR) of the i -th keyword in the l -th ad-group | |
| The cost-per-click (CPC) of the i -th keyword in the l -th ad-group | |
| The 0-1 binary decision variable indicating whether the i -th keyword is assigned to | |
| the -th ad-group or not. | |
| The advertising budget available to the l -th ad-group | |
| An acceptable probability range of the l -th ad-group | |
| The value-per-sale of the i -th keyword | |
| The conversion rate of the i -th keyword in the l -th ad-group | |
| ψ | The risk-tolerance of an advertiser |
| w | The normal vector to the hyperplane |
| τ | The intercept of the hyperplane function |
| The i -th training sample in the form of a multiple dimensional real vector | |
| The maximum number of words per keyword | |
| The size of the embedding | |
| A multi-layer perceptron with a single hidden layer parametrized by | |
| A multiple layers feed forward network with a linear activation function in the | |
| output layer parametrized by | |
| The network parameters |
5.2 Keyword Assignment and Grouping
Section titled “5.2 Keyword Assignment and Grouping”Although how to effectively organize keywords following search advertising structures (i.e., keyword assignment and grouping) is a critical operational-level issue, as far as we are aware, in the literature, less attention has been put to keyword assignment and grouping, except for recent works on keyword grouping (Li & Yang, 2020) and keyword categorization (Krasňanská et al., 2021; Polato et al., 2021). Techniques used for keyword assignment and grouping in the literature are summarized in Table 11.
Table 11. Techniques for Keyword Assignment and Grouping
| Category | Approach | Refs. |
|---|---|---|
| Optimization | Chance constrained programming | Li &Yang (2020) |
| Machine learning | Linear support vector machine | Krasňanská et al. (2021) |
| DeepSets model | Polato et al. (2021) |
(1) Chance constrained programming (CCP). CCP is a technique to solve optimization problems under various uncertainties, which formulates an optimization problem ensuring that the probability of meeting a certain constraint is above a certain level (Charnes & Cooper, 1959). Let denote the total number of search demands of the i-th keyword in a search market. Let and denote the click-through rate (CTR) and cost-per-click (CPC) of the i-th keyword in the l-th ad-group, respectively. Given an advertising campaign with m ad-groups and a set of keywords (i.e., n), let denote the 0-1 binary decision variable indicating whether the i-th keyword is assigned to the l-th ad-group or not. Then the budget constraint in keyword assignment and grouping can be formulated with chance constrained programming as
where is the advertising budget available to the l-th ad-group and is an acceptable probability range indicating that the probability that the cost of the l-th ad-group is less than the allocated budget, is greater than or equal to a certain level.
Considering that SSA environments are essentially uncertain, Li & Yang (2020) formulated keyword grouping as a stochastic programming problem with click-through rate and conversion rate as random variables, taking into account budget constraints and advertiser’s risk-tolerance as follows.
(40)
where is the conversion rate of the i-th keyword in the l-th ad-group; is the value-per-sale of the i-th keyword; and is the risk-tolerance of an advertiser. Moreover, they developed a branch-and-bound algorithm to solve their model. Their experiments illustrated that, a) the proposed method could approximately approach the optimal level; b) keyword grouping leads to a significant improvement in the profit for search advertisers with a large number of keywords.
(2) Linear support vector machine (LSVM). LSVM creates the hyperplane to segregate n-dimensional space into classes (Abe, 2005). Given a training dataset of n points , i = 1, …, n, where is a multiple dimensional real vector, and is a binary target value indicating the class that belongs, the maximum-margin hyperplane that divides the set of points is given as
(41)
where w is a normal vector to the hyperplane and is the intercept of the hyperplane function.
Krasňanská et al. (2021) applied a one-against-one LSVM-based method to classify keywords into multiple categories. The LSVM-based method can obtain a higher accuracy rate compared with other machine learning methods such as multinomial logistic regression and multinomial Na we Bayes.
(3) DeepSets model (DSM). DSM is a designing model for machine learning tasks whose objective functions are defined on sets that are invariant to permutations (Zaheer et al., 2017). It characterizes permutation invariant functions and provides a family of functions that has a special structure helpful to design a deep network architecture. In SSA, keywords can be regarded as a set of words. In general, when a keyword is short, the sequential order of a word in that keyword is not very important when learning a suitable keyword representation. Thus, keywords can be represented as a 2D tensor in , where is the maximum number of words per keyword and is the size of the embedding. Given a keyword k, the DeepSets is given as follows.
f_{DS}(\mathbf{k}, \boldsymbol{\theta}', \boldsymbol{\theta}) = f_{\boldsymbol{\theta}}(\sum_{k \in \mathbf{k}} f_{\boldsymbol{\theta}'}(k; \boldsymbol{\theta}'); \boldsymbol{\theta}), \tag{42}
where is a multi-layer perceptron with a single hidden layer parametrized by , and , is a multiple layers feed forward network with a linear activation function in the output layer parametrized
by ′. The network parameters can be optimized by a stochastic gradient descent approach with the goal of minimizing the cross entropy loss.
Polato et al. (2021) developed a deep learning model for multilingual keyword categorization by employing the fastText multilingual word embeddings, and designed its structure based on the DeepSets model. The DSM-based method can obtain good performance on accuracy scores and computational efficiency.
In the research stream on keyword assignment and grouping, in addition to academic efforts, research in the SSA industry has explored how to represent advertisers’ business objectives through the search advertising structure. Search Engine Land (2022) suggested to create campaigns (i.e., make keyword assignment decisions) to fulfill advertisers’ goals, e.g., finding consumers for the product (or service), increasing brand awareness, or driving new visitors to advertiser’s website, and create adgroups (i.e., make keyword grouping decision) connected to each campaign’s goal. Keyword assignment and grouping should consider various factors including the structure of advertisers’ website, products (or services) offered, locations, branded keywords and non-branded keywords, different bidding options, devices, consumer intents and keyword match types (Whitney, 2022; One PPC, 2022; Zirnheld, 2020). In the meanwhile, as the budget is set at the campaign level, it is effective to conduct keyword assignment with consideration of campaign-specific budget constraints (Whitney, 2022). For keyword grouping decisions under each campaign, it is suggested to construct more granular and specific ad-groups (Hill, 2018), taking into account ad-copies (Cherepakhin, 2021). However, methods used in the industry research are not theoretically rigorous, and lack necessary details and experimental evaluations to prove the effectiveness of the methods.
Note that, in the field of information retrieval, there are two research streams related to keywords grouping, namely keyword clustering (e.g., Regelson and Fain, 2006; Ortiz-Cordova and Jansen, 2012) and query clustering (e.g., Broder, 2002; Jansen et al., 2008; Yi and Maghoul, 2009), which are beyond the scope of our review.
5.3 Input Features used for Keyword Assignment and Grouping
Section titled “5.3 Input Features used for Keyword Assignment and Grouping”Table 12 summarizes input/features used in techniques for keyword assignment and grouping, as reported in the literature. Together with keyword performance parameters such as click-through rate, the SSA structure matters in keyword decisions (Li and Yang, 2020). In keyword categorization, statistical characteristics of keyword like TF-IDF has often been listed as input features (Krasňanská et al., 2021), and internal word structures are also used as the underlying framework for keyword representation (Polato et al., 2021).
Table 12. Input/Features for Keyword Assignment and Grouping and Related Research
| Refs. | Features | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| AS | SD | CTR | CPC | CVR | VPS | RT | IRF | IWS | |
| Li &Yang (2020) | √ | √ | √ | √ | √ | √ | √ | ||
| Krasňanská et al. (2021) | √ | ||||||||
| Polato et al. (2021) | √ |
Note: AS=Ad Structure; SD=Search Demand; CTR=Click-Through Rate; CPC=Cost Per Click; CVR=Conversion Rate; VPS=Value Per Sale; RT=Risk Tolerance; IRF=Information Retrieval Oriented Features (e.g., TF-IDF); IWS=Internal Word Structure.
5.4 Evaluation Metrics for Keyword Assignment and Grouping
Section titled “5.4 Evaluation Metrics for Keyword Assignment and Grouping”As the goal of keyword assignment and grouping is to fill promotional goals (e.g., maximizing the expected profit) by finding an optimal solution for segmenting a set of keywords into groups, Li and Yang (2020) took profit and return on investment as metrics. Frequently used evaluation metrics such as precision, recall, F1-score and accuracy are employed in keyword categorization. Evaluation metrics that we identified in the reviewed articles on keyword assignment and grouping and related streams are presented in Table 13.
Table 13. Evaluation Metrics for Keyword Assignment and Grouping
| Metric | Definition | Research Stream | Refs. |
|---|---|---|---|
| Profit | An advertiser’s or search engine’s economic | Keyword | Li &Yang |
| benefits. | assignment and | (2020) | |
| grouping | |||
| Return on | The expected profit divided by the expected | Keyword | Li &Yang |
| investment | total cost. | assignment and | (2020) |
| grouping | |||
| Keywords | The number of grouping keywords. | Keyword | Li &Yang |
| number | assignment and | (2020); | |
| grouping | Krasňanská et al. | ||
| (2021) | |||
| Precision | The ratio of correctly predicted positive | Keyword | Krasňanská et al. |
| observations to the total predicted positive | categorization | (2021) | |
| observation. | |||
| 𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 = 𝑇𝑟𝑢𝑒 𝑝𝑜𝑠𝑖𝑡𝑖𝑣𝑒/ | |||
| (𝑇𝑟𝑢𝑒 𝑝𝑜𝑠𝑖𝑡𝑖𝑣𝑒 +𝐹𝑎𝑙𝑠𝑒 𝑝𝑜𝑠𝑖𝑡𝑖𝑣𝑒). |
| Recall | The ratio of correctly predicted positive | Keyword | Krasňanská et al. |
|---|---|---|---|
| observations to the all observations in actual | categorization | (2021) | |
| class. | |||
| 𝑅𝑒𝑐𝑎𝑙𝑙 = 𝑇𝑟𝑢𝑒 𝑝𝑜𝑠𝑖𝑡𝑖𝑣𝑒/(𝑇𝑟𝑢𝑒 𝑝𝑜𝑠𝑖𝑡𝑣𝑒 + | |||
| 𝐹𝑎𝑙𝑠𝑒 𝑛𝑒𝑔𝑎𝑖𝑡𝑣𝑒). | |||
| F1-score | The weighted average of Precision and Recall. | Keyword | Krasňanská et al. |
| 𝐹1 = 2 ∗ 𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 ∗ 𝑅𝑒𝑐𝑎𝑙𝑙/(𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 + | categorization | (2021) | |
| 𝑅𝑒𝑐𝑎𝑙𝑙). | |||
| Accuracy | The ratio of correctly predicted observations to | Keyword | Polato et al. |
| the total observations. | categorization | (2021) | |
| 𝐴𝑐𝑐𝑢𝑟𝑎𝑐𝑦 = (𝑇𝑟𝑢𝑒 𝑝𝑜𝑠𝑡𝑖𝑡𝑖𝑣𝑒 + | |||
| 𝑇𝑟𝑢𝑒 𝑛𝑒𝑔𝑎𝑡𝑖𝑣𝑒)/(𝑇𝑟𝑢𝑒 𝑝𝑜𝑠𝑡𝑖𝑡𝑖𝑣𝑒 + | |||
| 𝑇𝑟𝑢𝑒 𝑛𝑒𝑔𝑎𝑡𝑖𝑣𝑒 + 𝐹𝑎𝑙𝑠𝑒 𝑝𝑜𝑠𝑡𝑖𝑡𝑖𝑣𝑒 + | |||
| 𝐹𝑎𝑙𝑠𝑒 𝑛𝑒𝑔𝑎𝑡𝑖𝑣𝑒). | |||
| Time | The amount of time taken by an algorithm. | Keyword | Polato et al. |
| complexity | categorization | (2021) |
5.5 Summary
Section titled “5.5 Summary”These prior works on keyword assignment and grouping problem could provide additional insights for advertisers in SSA. However, few are designed for the keyword assignment and grouping optimization problem following the search advertising structure, which is one of the critical research directions in the field of keyword decisions.
6. Keyword Adjustment
Section titled “6. Keyword Adjustment”6.1 Problem Description
Section titled “6.1 Problem Description”Search engines have to serve both organic and sponsored search results with low response latency in order to support better user experiences (Bai and Cambazoglu, 2019). Additionally, owing mainly to the everchanging nature of the bidding processes, and search users’ and advertisers’ behaviors, the search advertising market is extremely dynamic (Yang et al., 2015; 2022). In other words, consumer behaviors (e.g., ad clicks), characteristics of advertisement (e.g., ad positions) and competitions from other advertisers would change over time (Amaldoss et al., 2016). In such a dynamic market, advertisers need to prudently adjust their advertising strategies over time, which could be a strenuous task given the level of inherent complexity of search advertising. In particular, advertisers have to track the performance of ongoing search advertising campaigns and accordingly adjust their keyword structure in real time.
Search engine allows advertisers to actively adjust their keyword decisions. In SEA, it has been well recognized that keyword adjustment is important for advertisers to precisely display their advertisements and achieve more profit (Ye et al., 2015; George, 2019). First, keyword adjustment aims to obtain a dynamic policy maximizing the expected profit for SSA campaigns during a promotional period, which is distinctly different from one or several static keyword decisions at a series of times. Second, the number of distinct keywords used by search users is enormous in practical settings and search behaviors change over time (Bartz, 2006), which exponentially increase the search space for keyword adjustment. This raises a large challenge for the computational efficiency of online keyword adjustment.
Mathematically, given the selected keyword set , we define the keyword adjustment process as follows.
f^{(ADJ)}: K^{(TGT)} \xrightarrow{x_{i,t}^{(ADJ)} = \left(x_{i,\overline{m},t}^{(TGT)}, x_{i,j,t}^{(ASM)}, x_{i,j,l,t}^{(GRP)}\right)} K_{j,1,t}^{(ADJ)}, \dots, K_{j,l,t}^{(ADJ)}, \dots, K_{j,n_{group},t}^{(ADJ)}, \dots K_{j,n_{group},t}^{(ADJ)}, \dots K_{j,n_{group},t}^{(ADJ)}, \dots K_{j,n_{group},t}^{(ADJ)}, \dots K_{j,n_{group},t}^{(ADJ)}, \dots K_{j,n_{group},t}^{(ADJ)}, \dots K_{j,n_{group},t}^{(ADJ)}, \dots K_{j,n_{group},t}^{(ADJ)}, \dots K_{j,n_{group},t}^{(ADJ)}, \dots K_{j,n_{group},t}^{(ADJ)}, \dots K_{j,n_{group},t}^{(ADJ)}, \dots K_{j,n_{group},t}^{(ADJ)}, \dots K_{j,n_{group},t}^{(ADJ)}, \dots K_{j,n_{group},t}^{(ADJ)}, \dots K_{j,n_{group},t}^{(ADJ)}, \dots K_{j,n_{group},t}^{(ADJ)}, \dots K_{j,n_{group},t}^{(ADJ)}, \dots K_{j,n_{group},t}^{(ADJ)}, \dots K_{j,n_{group},t}^{(ADJ)}, \dots K_{j,n_{group},t}^{(ADJ)}, \dots K_{j,n_{group},t}^{(ADJ)}, \dots K_{j,n_{group},t}^{(ADJ)}, \dots K_{j,n_{group},t}^{(ADJ)}, \dots K_{j,n_{group},t}^{(ADJ)}, \dots K_{j,n_{group},t}^{(ADJ)}, \dots K_{j,n_{group},t}^{(ADJ)}, \dots K_{j,n_{group},t}^{(ADJ)}, \dots K_{j,n_{group},t}^{(ADJ)}, \dots K_{j,n_{group},t}^{(ADJ)}, \dots K_{j,n_{group},t}^{(ADJ)}, \dots K_{j,n_{group},t}^{(ADJ)}, \dots K_{j,n_{group},t}^{(ADJ)}, \dots K_{j,n_{group},t}^{(ADJ)}, \dots K_{j,n_{group},t}^{(ADJ)}, \dots K_{j,n_{group},t}^{(ADJ)}, \dots K_{j,n_{group},t}^{(ADJ)}, \dots K_{j,n_{group},t}^{(ADJ)}, \dots K_{j,n_{group},t}^{(ADJ)}, \dots K_{j,n_{group},t}^{(ADJ)}, \dots K_{j,n_{group},t}^{(ADJ)}, \dots K_{j,n_{group},t}^{(ADJ)}, \dots K_{j,n_{group},t}^{(ADJ)}, \dots K_{j,n_{group},t}^{(ADJ)}, \dots K_{j,n_{group},t}^{(ADJ)}, \dots K_{j,n_{group},t}^{(ADJ)}, \dots K_{j,n_{group},t}^{(ADJ)}, \dots K_{j,n_{group},t}^{(ADJ)}, \dots K_{j,n_{group},t}^{(ADJ)}, \dots K_{j,n_{group},t}^{(ADJ)}, \dots K_{j,n_{group},t}^{(ADJ)}, \dots K_{j,n_{group},t}^{(ADJ)}, \dots K_{j,n_{group},t}^{(ADJ)}, \dots K_{j,n_{group},t}^{(ADJ)}, \dots K_{j,n_{group},t}^{(ADJ)}, \dots K_{j,n_{group},t}^{(ADJ)}, \dots K_{j,n_{group},t}^{(ADJ)}, \dots K_{j,n_{group},t}^{(ADJ)}, \dots K_{j,n_{group},t}^{(ADJ)}, \dots K_{j,n_{group},t}^{(ADJ)}, \dots K_{j,n_{group},t}^{(ADJ)}, \dots K_{j,n_{group},t}^{(ADJ)}, \dots K_{j,n_{group},t}^{(ADJ)}, \dots K_{j,n_{group},t}^{(ADJ)}, \dots K_{j,n_{group},t}^{(ADJ)}, \dots K_{j,n_{group},t}^{(ADJ)}, \dots K_{j,n_{
where is the keyword adjustment function, is the adjusted keyword set in the l-th adgroup of the j-th campaign at time t, and is a decision vector of keyword assignment, indicating the structure adjustments of the i-th keyword in time t.
6.2 Keyword Adjustment and Related Work
Section titled “6.2 Keyword Adjustment and Related Work”How to effectively conduct keyword adjustment in real time has become a critical problem for advertisers in SSA. However, in the literature, no study we are aware of has been reported on this issue.
Keyword spreading is a technique related to keyword adjustment, which provides indirectly valuable help for advertisers in keyword research. In more detail, keyword spreading is a technique with the goal of optimizing the expected advertising revenue, where an advertiser substitutes high-cost keywords that are likely to be intensely competitive, with a set of related long-tail keywords that are collectively of lower costs but capable of leading to an equivalent volume of traffics. Budinich et al. (2010) provided an experimental benchmark of keyword spreading, and conducted large scale simulations to pin-point that the keyword spreading technique is generally convenient and acceptable to all three parties involved in SSA.
One related research stream to keyword adjustment is dynamic bid optimization (i.e., bid adjustment), i.e., how to adjust bids over a set of keywords over time. The bid optimization problem is referred to dynamically determining bids over a subset of keywords in order to maximize advertiser’s expected profit. SSA entitles advertisers to adjust their bids over keywords and rankings of their advertisements any time they want, and their payoffs can be realized in real time, which demands a dynamic equilibrium bidding strategy. As reported in an empirical research by Zhang and Feng (2011) based on two data sets containing bidding records over a sample of keywords, advertisers may engage in cyclical bid adjustments under certain conditions. Cyclical bidding patterns happen in both generalized first-price (GFP) and generalized second-price (GSP) auctions. Importantly, cyclical bidupdating behaviors emphasize the necessity of adopting a dynamic perspective when exploring equilibrium properties of bidding strategies in SSA. For more information on bid adjustment, refer to see Borgs et al. (2007), Zhou et al. (2008), Katona and Sarvary (2010), Cai et al. (2017), and Küçükaydin et al. (2019).
Another related research stream to keyword adjustment is budget adjustment, i.e., how to allocate advertising budget over time. In addition to bid adjustment, advertisers need to dynamically distribute their advertising budgets in order to avoid early ineffective clicks and save money for better advertising opportunities in the future. In SSA, there exist three levels of budget decisions throughout the entire lifecycle of advertising campaigns, namely, allocation across SSA markets, distribution over a series of time slots, and adjustment of the daily budget across keywords (Yang et al., 2012). For more information on budget adjustment, refer to see Yang et al. (2012, 2014, 2015) and Zhang et al. (2014a).
Moreover, research in the SSA industry believes that advertisers should adjust their keyword structures in real time (Search Engine Land, 2022). However, it takes time for advertisers to manage, track and adjust advertising structures to get the optimal results (Whitney, 2022). A good search advertising structure is critical for a successful SSA efforts, which helps advertisers effectively reach the right consumers (Whitney, 2022; Search Engine Land, 2022; Cherepakhin, 2021; One PPC, 2022). As a content marketing specialist at WordStream wrote, “Not having a well-structured account is like attempting to drive a car that’s not properly built – accidents are bound to happen”. Saravia (2020) suggested advertisers to conduct keyword research and adjust ad-structure related settings over time for optimal advertising performance. In order to equip with a more organized and manageable SSA structure, advertisers should keep fine-tuning and optimizing their campaigns (Hill, 2018).
7. Discussion and Future Directions
Section titled “7. Discussion and Future Directions”7.1 General Discussion
Section titled “7.1 General Discussion”7.1.1 The Disciplinary Perspective
Section titled “7.1.1 The Disciplinary Perspective”Our review collected 43 research papers on keyword decisions that have been published in 28 outlets (journals or conferences) in the fields of computer science, artificial intelligence, information retrieval, information systems, advertising, and marketing. This suggests that keyword decisions have been a hot topic covered in a great variety of high-level journals and conferences.
From the disciplinary perspective, keyword decisions are an interdisciplinary research field, which falls into computational advertising (Yang et al., 2017). Table 14 summarizes major disciplines, terminology and publication outlets for research on keyword decisions. Note that, we tell the major discipline of a study based on the research issue it addressed, authors’ affiliations and publication outlets. From Table 14, we can observe the following phenomena. First, in keyword generation, most contributions are from computer science, except for a few from management science, while for keyword targeting, keyword assignment and grouping, researchers from economics and management become the dominant forces. This is probably because that keyword generation is closely related to popular topics in computer science (e.g., query generation and expansion), while keyword targeting, keyword assignment and grouping are related to market mechanisms, advertising structure and processes.
Second, it is apparent that researchers from different disciplines have different focuses on keyword decisions. Specifically, in keyword generation, computer science researchers emphasize developing and comparing methods for keyword extraction from various sources including websites and Web pages, search result snippets, advertising databases and query logs (e.g., Yih et al., 2006; Li et al., 2007; Wu and Bolivar, 2008; Lee et al., 2009; Nie et al., 2019), and those in management science give prominence to investigating keyword generation from the perspective of consumers (e.g., Scholz et al., 2019) and using indirect associations between keywords to facilitate keyword generation (e.g., Abhishek and Hosanagar, 2007; Qiao et al., 2017; Zhang and Qiao, 2018; Zhang et al., 2021); in keyword targeting, computer science researchers primarily aim to identify a set of profitable keywords through adaptive approximation (Rusmevichientong and Williamson, 2006), feature selection (Kiritchenko and Jiline, 2008) and integer programming (Zhang et al., 2014b), and improve the matching efficiency by using
machine learning methods (e.g., Radlinski et al., 2008; Gupta et al., 2009; Grbovic et al., 2016), those in economics put a premium on the balance between risk and profit in keyword selection (Symitsi et al., 2022) and the economic consequence of matching mechanisms (Singh and Roychowdhury, 2008), and those in management science concentrate on the strategic role of keyword management costs (Amaldoss et al., 2016) and brand awareness and traffic generated from selected keywords (Arroyo-Cañada and Gil-Lafuente, 2019); in keyword assignment and grouping, computer science researchers employ machine learning methods to increase accuracy and efficiency of keyword categorization (Polato et al., 2021; Krasňanská et al., 2021), and those in management science take into account search advertising structure to formulate keyword grouping in a stochastic programing framework aiming to maximize the expected profit (Li and Yang, 2020).
Third, it is apparent that there are no commonly agreed definitions for related concepts identified in the literature on keyword decisions. In particular, these terms have been defined variously in different papers. For example, regarding keyword generation, some studies used keyword suggestion (e.g., Chen et al., 2008; Sarmento et al., 2009; Schwaighofer et al., 2009; Qiao et al., 2017) to represent it, some used keyword recommendation (e.g., Thomaido and Vazirgiannis, 2011; Zhang et al., 2012a), others used keyword extraction (e.g., Yih et al., 2006; Li et al., 2007; Zhou et al., 2007; Wu and Bolivar, 2008), and there are also other terms such as keyword enrichment (GM et al., 2011), term recommendation (Bartz et al., 2006), bidterm suggestion (Chang et al., 2009), and bid phrases generation (Ravi et al., 2010). Some scholars used keyword selection to indicate the process of shrinking the domain-specific keyword pool in order to target potential customers precisely (e.g., Rusmevichientong and Williamson, 2006), while others used it to represent keyword extraction from Web pages or search logs (e.g., Berlt et al., 2011). We also found that some studies used keyword suggestion to represent keyword selection (e.g., Zhang et al., 2014b; Zhang and Qiao, 2018). We believe that this phenomenon can be attributed to the interdisciplinary nature of keyword decisions.
Table 14. The Summary of Disciplines, Terminology and Publication Outlets for Keyword Decision Research
| Keyword | Refs. | Major | Journal/Conference | Terminology |
|---|---|---|---|---|
| Decision | Discipline | |||
| Keyword | Bartz et al. | Computer | The 2nd Workshop on Sponsored Search | Keyword |
| generation | (2006) | science | Auctions (EC’06) | recommendation |
| Joshi | Computer | The 6th IEEE International Conference | Keyword |
|---|---|---|---|
| &Motwani | science | on Data Mining-Workshops | generation |
| (2006) | (ICDMW’06) | ||
| Yih et al. | Computer | The 15th International Conference on | Keyword |
| (2006) | science | World Wide Web (WWW’06) | extraction |
| Abhishek | Managemen | The 9th International Conference on | Keyword |
| &Hosanagar | t science | Electronic Commerce (ICEC’07) | generation |
| (2007) | |||
| Li et al. | Computer | The 1st International Workshop on Data | Keyword |
| (2007) | science | Mining and Audience Intelligence for | extraction |
| Advertising (ADKDD’07) | |||
| Zhou et al. | Computer | Integration and Innovation Orient to E | Keyword |
| (2007) | science | Society | extraction |
| Amiri et al. | Computer | The International Conference on | Keyword |
| (2008) | science | Information and Knowledge Engineering | suggestion |
| (IKE’08) | |||
| Chen et al. | Computer | The 2008 International Conference on | Keyword |
| (2008) | science | Web Search and Data Mining | suggestion |
| (WSDM’08) | |||
| Fuxman et al. | Computer | The 17th International Conference on | Keyword |
| (2008) | science | World Wide Web (WWW’08) | generation |
| Wu &Bolivar | Computer | The 17th International Conference on | Keyword |
| (2008) | science | World Wide Web (WWW’08) | extraction |
| Chang et al. | Computer | The 18th International Conference on | Bidterm |
| (2009) | science | World Wide Web (WWW’09) | Suggestion |
| Lee et al. | Computer | The 32nd International ACM SIGIR | Keyword |
| (2009) | science | Conference on Research and | extraction |
| Development in Information Retrieval | |||
| (SIGIR’09) | |||
| Wu et al. | Computer | The 18th International Conference on | Keyword |
| (2009) | science | World Wide Web (WWW’09) | generation |
| Sarmento et | Computer | The 3rd International Workshop on Data | Keyword |
| al. (2009) | science | Mining and Audience Intelligence for | suggestion |
| Advertising (ADKDD’09) | |||
| Schwaighofer | Computer | The 3rd International Workshop on Data | Keyword |
| et al. (2009) | science | Mining and Audience Intelligence for | suggestion |
| Advertising (ADKDD’09) | |||
| Mirizzi et al. | Computer | The 19th ACM International Conference | Keyword |
| (2010) | science | on Information and Knowledge | suggestion |
| Management (CIKM’10) | |||
| Ravi et al. | Computer | The 3rd ACM International Conference | Bid phrases |
| (2010) | science | on Web Search and Data Mining | generation |
| (WSDM’10) |
| Welch et al. | Computer | The 19th ACM International Conference | Keyword | |
|---|---|---|---|---|
| (2010) | science | on Information and Knowledge | selection | |
| Management (CIKM’10) | ||||
| Berlt et al. | Computer | Journal of Information and Data | Keyword | |
| (2011) | science | Management | selection | |
| GM et al. | Computer | The 4th ACM International Conference | Keyword | |
| (2011) | science | on Web Search and Data Mining | enrichment | |
| (WSDM’11) | ||||
| Scaiano | Computer | The International Conference on Recent | Keyword | |
| &Inkpen | science | Advances in Natural Language | selection | |
| (2011) | Processing | |||
| Thomaidou | Computer | The 2011 International Conference on | Keyword | |
| &Vazirgianni | science | Advances in Social Networks Analysis | recommendation | |
| s (2011) | and Mining | |||
| Zhang et al. | Computer | ACM Transactions on Intelligent | Keyword | |
| (2012a) | science | Systems and Technology (TIST) | recommendation | |
| Jadidinejad | Computer | Journal of Computer & Robotics | Keyword | |
| &Mahmoudi | science | suggestion | ||
| (2014) | ||||
| Qiao et al. | Managemen | Information & Management | Keyword | |
| (2017) | t science | suggestion | ||
| Zhang &Qiao | Managemen | The 22nd Pacific Asia Conference on | Keyword | |
| (2018) | t science | Information Systems (PACIS’18) | suggestion | |
| Nie et al. | Computer | IEEE Intelligent Systems | Keyword | |
| (2019) | science | generation | ||
| Scholz et al. | Managemen | Decision Support Systems | Keyword | |
| (2019) | t science | generation | ||
| Zhou et al. | Computer | The 27th International Conference on | Keyword | |
| (2019) | science | World Wide Web (WWW’19) | generation | |
| Zhang et al. | Managemen | Electronic Commerce Research | Keyword | |
| (2021) | t science | suggestion | ||
| Keyword | Rusmevichie | Computer | The 7th ACM Conference on Electronic | Keyword |
| targeting | ntong | science | Commerce (EC’06) | selection |
| &Williamson | ||||
| (2006) | ||||
| Kiritchenko | Computer | The Workshop on New Challenges for | Keyword | |
| &Jiline | science | Feature Selection in Data Mining and | optimization | |
| (2008) | Knowledge Discovery at ECML/PKDD | |||
| 2008 | ||||
| Zhang et al. | Computer | Information Processing & Management | Keyword | |
| (2014b) | science | suggestion | ||
| Arroyo | Managemen | Operational Research International | Keyword | |
| Cañada and | t science | Journal | selection | |
| Gil-Lafuente | ||||
|---|---|---|---|---|
| (2019) Symitsi et al. | Economics | European Journal of Operational | Keyword | |
| (2022) | Research | selection | ||
| Radlinski et | Computer | The 31st Annual International ACM | Keyword match | |
| al. (2008) | science | SIGIR Conference on Research and | ||
| Development in Information Retrieval (SIGIR’08) | ||||
| Singh and Roychowdhu ry (2008) | Economics | The 4th Workshop on Ad Auctions, Conference on Electronic Commerce (EC’08) | Keyword match | |
| Gupta et al. (2009) | Computer science | The 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD’09) | Keyword match | |
| Amaldoss et al. (2016) | Managemen t science | Marketing Science | Keyword match | |
| Grbovic et al. (2016) | Computer science | The 39th International ACM SIGIR conference on Research and Development in Information Retrieval (SIGIR’16) | Keyword match | |
| Keyword | Li and Yang | Managemen | International Journal of Electronic | Keyword |
| assignment | (2020) | t science | Commerce | assignment and |
| and | grouping | |||
| grouping | Krasňanská et | Computer | TEM Journal | Keyword |
| al. (2021) | science | categorization | ||
| Polato et al. | Computer | 2021 IEEE Symposium Series on | Keyword | |
| (2021) | science | Computational Intelligence (SSCI’21) | categorization |
7.1.2 The Perspective of Keyword Decisions
Section titled “7.1.2 The Perspective of Keyword Decisions”Following the framework of keyword decisions, articles collected in our review can be categorized into four groups: domain-specific keyword pool generation (30 studies), keyword targeting (10 studies), keyword assignment and grouping (3 studies) and keyword adjustment (0 study). From the literature distribution over different keyword decisions identified in SSA, we have the following observations.
First of all, research efforts on keyword decision topics are unbalanced. More specifically, research efforts focus more on keyword generation and keyword targeting; however, there are few research efforts systematically solving keyword optimization problems related to advertising structures defined by search engines, i.e., keyword assignment and grouping and keyword adjustment. In practical campaign management, it is impossible to exaggerate the importance of the SSA structure in keyword decisions. Although the industry needs have been clear, the academic literature on keyword assignment and grouping has been sparse. Second, concerning keyword targeting, as discussed in Section 4, a dozen of prior research efforts have separately explored either keyword selection or keyword match. However, there are few studies considering both of the two issues to realize the optimal targeting for SSA campaigns. In addition, there is no research on keyword adjustment reported in the existing literature.
Regarding the less research on keyword assignment and grouping (Section 5.2) and keyword adjustment (Section 6.2), there are several possible explanations. The major reason might be the fact that SSA is distinctly different from the traditional advertising forms due to its advertising mechanism and structure. That is, there are different related keyword decisions throughout the lifecycle of SSA campaigns (Yang et al., 2019), rather than a single decision. Moreover, the SSA environment is extremely dynamic (Zhang and Feng, 2011; Yang et al., 2022) and highly uncertain (Li and Yang, 2020). The dynamic complexity inherent in SSA makes keyword decisions complicated. Furthermore, different from budget adjustment and bid adjustment that have been widely explored by researchers, keyword adjustment is a discrete optimization problem in a large feasible space raised by the scale of keyword number. Finally, keyword decisions are interdisciplinary topics which need joint efforts from different disciplines. However, as we can realize, it’s not straightforward to get over disciplinary barriers.
To sum up, although plenty of research efforts have been invested in keyword decisions, there is few, if any, research taking into account practical decision components (e.g., the search advertising structure, dynamics). In this sense, we can see that there is a big gap between academic research and search advertising practice. Thus, this calls for substantial research efforts to address the practical difficulties that search advertisers meet in keyword decisions.
7.1.3 The Perspective of Datasets
Section titled “7.1.3 The Perspective of Datasets”Table 15 summarizes the datasets used to evaluate the performance of the proposed methods for various keyword decisions in the literature. We divided the data sources into four types: synthetic data generated by the authors by using computer programs, private data collected by the authors, business data provided by search engines or firms that advertise their products and services and public data shared by their owners. The first three can only be accessed by authors and those with permissions, and the fourth is available to everybody; except for the first, the other three are real-world data.
As illustrated in Table 15, 1 synthetic dataset, 19 private datasets, 10 business datasets and 1 public dataset were used in keyword generation; 3 synthetic datasets, 1 private dataset and 6 business datasets were used in keyword targeting; 1 private dataset and 3 business datasets were used in keyword assignment and grouping. First, it is obvious that almost all studies are based on datasets that are not publicly available, which may hinder the research development in this field. Second, approximately half of the prior research has access to business datasets, and the other half has to generate the necessary data for validation or collect the data through crawlers. This may also echo the gap between academic researchers and SSA practitioners. Last but not the least, we also notice that only a few studies conducted experimental evaluation on two or more datasets. Thus, it is urgent to construct benchmarking datasets for evaluating the performance of keyword decision models and algorithms.
Table 15. The Summary of Datasets for Keyword Decisions
| Keyword | Refs. | Description | Data |
|---|---|---|---|
| Decision | Source | ||
| Keyword | Bartz et al. | The advertising database and the search click logs were obtained | Business |
| generation | (2006) | from Yahoo Inc., including terms and URLs used by the | data |
| advertisers and the searchers, respectively. | |||
| Joshi | The dataset includes 8,000 search terms picked randomly from | Private | |
| &Motwani | Web pages relevant on three broad topics (travel, car-rentals, and | data | |
| (2006) | mortgage). | ||
| Yih et al. | The dataset includes 1,109 web pages randomly crawled from | Private | |
| (2006) | MSN Search results by the authors. | data | |
| Abhishek | The corpus consists of 96 documents crawled from websites of 3 | Private | |
| &Hosanagar | spas and 1 dental clinic by the authors. The initial dictionary was | data | |
| (2007) | created by taking top 15 words from each page, out of which | ||
| 1,087 were distinct. | |||
| Li et al. | The dataset includes 2,200 TV broadcast transcripts crawled from | Private | |
| (2007) | CNN Live Today by the authors. | data | |
| Zhou et al. | The dataset includes 300 Web pages crawled from three Chinese | Private | |
| (2007) | websites (i.e., Sohu, Sina and 163), and 300 advertisements | data | |
| crawled from Google’s sponsored lists by the authors. | |||
| Amiri et al. | The INEX Wikipedia collection includes more than 658,000 | Public | |
| (2008) | documents, 267,625,000 terms. https://www.mpi | data | |
| inf.mpg.de/departments/databases-and-information | |||
| systems/software/inex/ |
| Chen et al. | The dataset includes 1,306,586 web pages crawled from the | Private |
|---|---|---|
| (2008) | 150,446 ODP (Open Directory Project) categories by the authors. | data |
| Fuxman et al. | A snapshot of the query logs obtained from a major search | Business |
| (2008) | engine, including 41 million queries, 55 million URLs, and 93 | data |
| million edges. | ||
| Wu &Bolivar | The dataset includes 800 Web pages randomly crawled from a | Private |
| (2008) | large pool of eBay partner websites by the authors. | data |
| Chang et al. | The dataset includes 200 ads from Yahoo’s sponsored search ad | Business |
| (2009) | database, and each ad had fewer than 50 bidterms. | data |
| Lee et al. | The dataset includes 10 popular drama shows and the first 5 | Private |
| (2009) | episode scripts per show were selected from various sources (50 | data |
| scripts, 3,404 scenes total) by the authors. | ||
| Wu et al. | The dataset includes 100 seed category names widely spread over | Private |
| (2009) | different topics from eBay and Amazon. For each characteristic | data |
| document generation, top 400 Google search-hits were crawled | ||
| by the authors. | ||
| Sarmento et | The dataset includes a set of 84,180 advertisements and 122,099 | Business |
| al. (2009) | unique keywords, compiled over a period of about 5 years. | data |
| Schwaighofer | The first dataset includes 10,000 advertisements and 100 | Synthetic |
| et al. (2009) | keywords sampled from a randomly generated model. | data, |
| The second dataset is derived from a corpus of almost 6 million | Business | |
| advertisements and 19 million distinct keywords. | data | |
| Mirizzi et al. | The dataset is a domain-specific subgraph of Dbpedia crawled | Private |
| (2010) | starting from a set of seed nodes. | data |
| Ravi et al. | The dataset includes a set of ads with advertiser-specified bid | Business |
| (2010) | phrases from the Yahoo! Ad corpus, and each ads is associated | data |
| with a landing URL. | ||
| Welch et al. | The dataset includes a range of videos including 12 films, 3 clips | Private |
| (2010) | from news and educational content, and 5 amateur clips crawled | data |
| from YouTube by the authors. | ||
| Berlt et al. | The dataset includes 300 Web pages extracted from a Brazilian | Private |
| (2011) | newspaper. | data |
| GM et al. | The dataset includes 95,104 websites sampled from contextual | Business |
| (2011) | advertising system of Yahoo! and all Web page requests from | data |
| these websites for a duration of 90 days, 220 million pages | ||
| accounting for 21 billion impressions. | ||
| Scaiano | The dataset records the performance of existing campaigns from | Business |
| &Inkpen | an industrial partner. | data |
| (2011) | ||
| Thomaidou | The dataset includes landing pages taken from eight different | Private |
| &Vazirgianni | thematic areas promoting several products and services. | data |
| s (2011) | ||
| Zhang et al. | The Pagelinks dataset was crawled by the authors in September | Private |
| (2012a) | 2009. It includes 81.83 million triples and each triple represents a | data |
| relation where the first entity has a page link to the second entity, | ||||
|---|---|---|---|---|
| resulting in an initial graph with 81.83 million directed edges and | ||||
| 9.54 million entities. | ||||
| Jadidinejad | The dataset leveraged 2008-07-14 offline XML version of | Private | ||
| &Mahmoudi | Wikipedia, including more than 7 million articles crawled by the | data | ||
| (2014) | authors. | |||
| Qiao et al. | The dataset includes approximately 8,500 query logs on October | Private | ||
| (2017) | 2014 crawled from Baidu Tuiguang by the authors. | data | ||
| Zhang &Qiao | Query logs were collected through Google Keyword Suggestion | Private | ||
| (2018) | Tool by the authors, including query keywords and query | data | ||
| volumes for 20 seed keywords. | ||||
| Nie et al. | The dataset was crawled from Wikipedia by the authors, | Private | ||
| (2019) | including 879 articles: 130, 104, 317 and 328 articles for four | data | ||
| seed keywords, respectively. | ||||
| Scholz et al. | The dataset records the performance of SSA campaigns for two | Business | ||
| (2019) | large-scale online stores, which was provided by a company that | data | ||
| runs more than 100 online stores worldwide and has online sales | ||||
| of just under Euro 7 billion a year. | ||||
| Zhou et al. | The dataset includes 40 million query logs provided by | Business | ||
| (2019) | Sogou.com, and each sample consists of a <ad keyword,="" td="" user<=""> | data | data | |
| query> pair. | ||||
| Zhang et al. | The corpus of Zhihu was crawled by the authors and the corpus | Private | ||
| (2021) | for calculating the Web-based kernel function and semantic drift | data | ||
| levels was collected from top 50 search results of Baidu. | ||||
| Keyword | Rusmevichien | The dataset includes 100 randomly generated problem instances. | Synthetic | |
| targeting | tong | In the first experiment, each problem instance has 8,000 | data | |
| &Williamson | keywords, 200 time periods, $400 budget per period, and the | |||
| (2006) | number of search queries in each time period has a Poisson | |||
| distribution with a mean of 40,000. In the second experiment, | ||||
| each problem instance has 50,000 keywords, 200 time periods, | ||||
| $1,000 budget per period, and the number of search queries in | ||||
| each time period has a Poisson distribution with a mean of | ||||
| 150,000. | ||||
| Kiritchenko | The dataset includes 3-month records of an SME’s advertising | Business | ||
| &Jiline | campaign on Google provided by the Epiphan Systems Inc. | data | ||
| (2008) | The company operates in a video signal processing business. In | |||
| the reported period, it advertised on 388 unique keywords | ||||
| ranging from single words to 5-word phrases. The dataset is | ||||
| constructed from the company’s weblogs and contains all users’ | ||||
| queries resulting in paid clicks along with the label on users’ | ||||
| activities. | ||||
| Zhang et al. | The dataset was obtained from Microsoft Research, including | Business | ||
| (2014b) | search logs and auction logs collected during one month (April | data |
| 2011) and the advertising database containing 31 million ad | |||
|---|---|---|---|
| groups. | |||
| Arroyo | The advertising performance data (e.g., impressions per week, | Business | |
| Cañada &Gil | clicks per week) obtained by the advertising planner tool of | data | |
| Lafuente | Google, and twenty-four different alternative keyword sets | ||
| (2019) | provided by a stock exchange brokerage service company. | ||
| Symitsi et al. | The set of relevant keywords and the relevant metrics was drawn | Private | |
| (2022) | from Google Ad Words on September 11, 2015, and the Search | data | |
| Volume Index (SVI) time series data were drawn from Google | |||
| Trends by the authors. | |||
| Gupta et al. | The dataset was derived from two months of logs collected from | Business | |
| (2009) | the Microsoft contextual advertising system containing millions | data | |
| of advertising impressions based on millions of bidded keywords. | |||
| Radlinski et | The dataset is provided by Yahoo! Research, including 10 million | Business | |
| al. (2008) | most frequent queries issued to the Web search engine over a | data | |
| one-week period. | |||
| Singh | The authors illustrated the research scenarios via calculating | Synthetic | |
| &Roychowdh | examples (e.g., four advertisers and two keywords with different | data | |
| ury (2008) | revenue). | ||
| Amaldoss et | The authors illustrated the research scenarios via calculating | Synthetic | |
| al. (2016) | examples (e.g., a search advertising market with two risk-neutral | data | |
| advertisers and one keyword). | |||
| Grbovic et al. | The dataset includes more than 126.2 million unique queries, | Business | |
| (2016) | 42.9 million unique ads, and 131.7 million unique links, | data | |
| comprising over 9.1 billion search sessions on Yahoo Search. | |||
| Keyword | Li &Yang | The first dataset was obtained from advertising campaigns run by | Business |
| assignmen | (2020) | an e-commerce firm that promoted celebration commodity on | data |
| t and | Amazon from June 2016 to March 2017. | ||
| grouping | The second data set records advertising campaigns on Google | ||
| adwords provided by a large firm selling sportswear, from | |||
| January 2016 to September 2016. | |||
| Krasňanská et | The dataset includes 112,117 keywords collected by the authors | Private | |
| al. (2021) | using online marketing tools (e.g., Google Search Console, | data | |
| Google Analytics, Marketing Miner, Ahrefs, Google Ads, | |||
| Collabim, various whisperers like Google Keyword Planner or | |||
| Ubersuggest’s free keyword tool), the website of the customer for | |||
| whom the analysis was performed, competitor websites, | |||
| discussion forums, social networks, and several other resources | |||
| that focus on the field of jewellery. | |||
| Polato et al. | The dataset includes users’ generated keywords provided by a | Business | |
| (2021) | Spanish company in 17 different languages that have been semi | data | |
| automatically categorized over the Google Product Taxonomy. |
7.2 Future Directions
Section titled “7.2 Future Directions”7.2.1 Keyword adjustment
Section titled “7.2.1 Keyword adjustment”Most of prior research focuses on static keyword decisions without consideration of the real-time keyword performance in SSA markets. Keyword adjustment should take into account changes over time in consumer behaviors (e.g., ad clicks), characteristics of advertisement (e.g., ad positions) and competitions from other advertisers (Amaldoss et al., 2016). First of all, it calls for a systematic investigation on dynamic strategies for various keyword decisions throughout the entire lifecycle of SSA campaigns, as discussed in this survey, with consideration of the interdependence between these keyword decisions.
Second, it is of necessity to explore dynamic strategies with reference to each type of keyword decisions. As for keyword generation, advertisers should maintain and update the domain-specific keyword pool as the Web contents (e.g., websites and Web pages) and search users’ behaviors (e.g., query logs and clicks) have been growing and evolving over time (Nie et al., 2019). Regarding keyword targeting, prior studies (e.g., Rutz et al., 2012) showed that it’s more profitable to select general and brand keywords with broad match in the initial stage, and select specific keywords with exact match in the later stage, based on the fact that consumers would change their intentions from the exploring stage to the final purchase stage in the conversion funnel (Scholz et al., 2019). Such insights from empirical studies are valuable for designing strategies for keyword adjustment; however, they are temporally coarse-grained and thus can not support real-time operations. Dynamic strategies for keyword assignment and grouping need to consider structural constraints defined by search engines and handle the evolving interactions between keyword decisions at the two levels (i.e., keyword assignment and keyword grouping). In cases with multiple campaigns, it is also necessary to consider the dynamical relationships between keyword assignment decisions among campaigns and keyword grouping decisions among ad-groups.
Third, it is suggested to apply dynamic optimization techniques such as optimal control and reinforcement learning to deal with dynamics in keyword decisions. Different from budget adjustment and bid adjustment, keyword adjustment is a discrete optimization problem in a large feasible space characterized by the scale of keyword number. Hence, discrete optimal control can be used to adjust advertisers’ keyword decisions during the entire lifecycle of SSA campaigns in a real-time manner, maximizing the expected profit over a certain time horizon.
7.2.2 Keyword assignment and grouping
Section titled “7.2.2 Keyword assignment and grouping”Although research in the SSA industry gave quite a few heuristic-based methods for keyword assignment and grouping (Hill, 2018; Whitney, 2022), there is no concrete evidence for their effectiveness. In this sense, it’s interesting to conduct experimental evaluations to validate and compare the performance of these heuristic-based methods based on real-world datasets collected from practical SSA campaigns.
Through drawing direct analogies between SSA markets and financial markets, Dhar and Ghose (2010) stated that like financial markets, the increasing availability of information through IT and the Internet made SSA markets more efficient over time. This inspires us to treat each keyword as a risky asset and use the modern portfolio theory to assemble an asset portfolio (i.e., keyword assignment and grouping) that maximizes expected return for a given level of risk.
Optimal strategies for keyword assignment and grouping are more complicated in that they are closely related to the search advertising structure, thus need to handle multiple objectives and take into account structural constraints from search engines. It is suggested to model keyword assignment and grouping as a bi-level optimization model and apply a multi-objective deep reinforcement learning algorithm to solve the model.
7.2.3 Deep learning technologies for keyword decisions
Section titled “7.2.3 Deep learning technologies for keyword decisions”In the literature, various techniques have been employed to solve keyword decision problems, such as logistic regression (e.g., Lee et al., 2009; Berlt et al., 2011), latent Dirichlet allocation (e.g., Welch et al., 2010; Qiao et al., 2017), integer optimization (e.g., Zhang et al., 2014b; Li and Yang, 2020), random walks (e.g., Fuxman et al., 2008) and game-theoretic model (e.g., Singh and Roychowdhury, 2008; Amaldoss et al., 2016), as we discussed in Sections 3-6.
Search and electronic markets prevailing nowadays provide a large amount of microstructure data for model training and adaptive learning. In recent years, the rise of deep techniques has revived interests in applying deep learning algorithms to support and facilitate advertising decisions (e.g., Cai et al., 2017; Polato et al., 2021; Yang and Zhai, 2022). By taking keyword decisions (e.g., keyword assignment and grouping) as classification problems, a variety of deep learning models can substantially improve the model performance.
Moreover, deep learning techniques are helpful to capture complex keyword correlations and complicated advertising settings for keyword decisions (Zhou et al., 2019). The attention-based neural network module (i.e., Transformer) is specifically designed to capture interactions among elements in the input (Lee et al., 2019). Such that, attention-based models, such as set transformers (Polato et al., 2021) may work well in modeling interactions among keywords to boost keyword decisions.
The performance (e.g., clicks and conversions) of a set of similar keywords may be interdependent (Amaldoss et al., 2016). Interactions between keywords can be expressed by various graphs in terms of co-occurrence relationships, semantic relationships and performance influences that can be obtained either by analyzing search advertising logs or by extracting the corpus of vocabulary dictionaries/corpus (e.g., thesaurus dictionary, Wikipedia). Graph models such as graph neural networks (GNNs) are capable of dealing with non-Euclidean graph data by representing high-order feature interactions in the graph structure (Zhai et al., 2023). Hence, GNN can be used to model complex interactions and relationships and thus improve the performance of keyword decision models.
However, it’s not trivial to address the keyword decision problems in deep learning frameworks. For example, keyword generation may pursue keywords that are diversified and relevant to the seed keywords. This calls for deep learning models with high interpretability and a deep integration with domain (e.g., advertising and marketing) knowledge.
7.2.4 Comparison studies
Section titled “7.2.4 Comparison studies”In the literature on keyword decisions in the SSA context, as we discussed in previous sections, 39 metrics and 31 datasets were used in 30 articles on keyword generation; 19 metrics and 10 datasets were used in 10 articles in the research stream of keyword targeting; and 8 metrics and 4 datasets were used in 3 articles on keyword assignment and grouping. It is apparent that there is no commonly agreed evaluation metric and benchmark dataset. In the meanwhile, most of the datasets used in prior studies are not publicly available. Moreover, methods developed for keyword decisions were typically compared with a few baselines (including simple heuristic-based methods), rather than with state-ofthe-art methods.
This calls for plenty of research efforts on comparison studies to evaluate various keyword decision models. It is also worthwhile to build public datasets and design a set of evaluation metrics for each type of keyword decisions in SSA.
7.2.5 Joint optimization
Section titled “7.2.5 Joint optimization”In SSA, keyword decisions at different levels form a closed-loop decision cycle, where results from high-level decisions serve as constraints/inputs for low-level decisions, and operational results at low levels create feedbacks for decisions at high levels (Yang et al., 2019). As far as we knew, most of existing efforts deal with a single keyword decision separately. It is necessary to consider joint optimization for two or more related keyword decisions in an integrated manner by considering relationships between them in the search advertising structure. Addressing keyword assignment and grouping problem in a unified model can be viewed as an example in this direction.
Another direction for joint optimization is to characterize the interface of keyword decisions with other advertising decisions in SSA, such as budget allocation and bid determination. In SSA, besides identifying relevant keywords and designing effective keyword structure, advertisers have to optimally allocate the advertising budget and determine optimal bidding prices on keywords, in order to maximize the performance of campaigns. More specifically, the outcome of budget decisions largely defines the feasible space for keyword decisions; in the meanwhile, keyword decisions are closely related to bidding decisions in that the latter can be considered as an important parameter in the former, which of the two together determine whether and when search advertisements can be displayed to potential consumers. That is, keyword decisions need to cooperate with other decision variables (e.g., budget and bid) in an integrated way. Fortunately, several researches have emerged recently in this direction, e.g., the dual adjustment of daily budget and bids (Zhang et al., 2012b; Zhang et al. 2014a), simultaneously selecting relevant keywords and putting optimal bidding prices over these keywords (Zhang et al., 2014b). Additionally, it is also an interesting perspective to elaborate cooperative keyword decision scenarios in the context of SSA and explore corresponding optimal strategies.
8. Conclusions
Section titled “8. Conclusions”The main objective of this paper is to present a research agenda for keyword decisions in the context of SSA. We propose an overarching framework that highlights keyword related decision scenarios throughout the entire lifecycle of SSA campaigns. Based on this framework, we conduct a substantive review of the state-of-the-art literature on keyword decisions. We cover the related issues with sufficient depth by enumerating techniques for optimizing keyword decisions, input features and evaluation metrics. We further summarize the research status, identify the research gaps, and outline interesting prospects for future exploration in this area.
Keyword decisions are a distinct topic in online advertising because state-of-the-art Web science basically takes keyword as the basic unit to offer various information services. In this sense, without loss of generality, insights and solutions yielded from keyword decisions in SSA can also shed light on other online advertising forms such as social media advertising.
References
Section titled “References”-
[1]. Abe, S. (2005). Support vector machines for pattern classification (Vol. 2, p. 44). London: Springer.
-
[2]. Abhishek, V., & Hosanagar, K. (2007, August). Keyword generation for search engine advertising using semantic similarity between terms. In Proceedings of the 9th International Conference on Electronic Commerce (ICEC’07) (pp. 89-94), Minneapolis, MN, USA. ACM.
-
[3]. Amaldoss, W., Jerath, K., & Sayedi, A. (2016). Keyword management costs and “broad match” in sponsored search advertising. Marketing Science, 35(2), 259-274.
-
[4]. Amiri, H., AleAhmad, A., Rahgozar, M., & Oroumchian, F. (2008, July) Keyword suggestion using conceptual graph construction from Wikipedia rich documents. International Conference on Information and Knowledge Engineering (IKE’08), Las Vegas, USA.
-
[5]. Anagnostopoulos, A., Broder, A. Z., Gabrilovich, E., Josifovski, V., & Riedel, L. (2007, November). Just-in-time contextual advertising. In Proceedings of the 16th ACM Conference on Information and Knowledge Management (CIKM’10) (pp. 331-340), Lisboa, Portugal. ACM.
-
[6]. Arroyo-Cañada FJ. & Gil-Lafuente, J. (2019). A fuzzy asymmetric TOPSIS model for optimizing investment in online advertising campaigns. Operational Research International Journal, 19(3), 701-716.
-
[7]. Azad, H. K., & Deepak, A. (2019). Query expansion techniques for information retrieval: A survey. Information Processing & Management, 56(5), 1698-1735.
-
[8]. Bai, X., & Cambazoglu, B. B. (2019). Impact of response latency on sponsored search. Information Processing & Management, 56(1), 110-129.
-
[9]. Bartz, K., Murthi, V., & Sebastian, S. (2006, June). Logistic regression and collaborative filtering for sponsored search term recommendation. In 2nd Workshop on Sponsored Search Auctions (EC’06) (Vol. 5), Ann Arbor, Michigan. ACM.
-
[10].Berlt, K., Pessoa, M., Herrera, M., Sena, C. A., Cristo, M., & de Moura, E. S. (2011). ACAKS: An Ad-Collection-Aware Keyword Selection Approach for Contextual Advertising. Journal of Information and Data Management, 2(3), 243.
-
[11].Blei, D. M., Ng, A. Y., & Jordan, M. I. (2003). Latent dirichlet allocation. Journal of Machine Learning Research, 3(Jan), 993-1022.
-
[12].Borgs, C., Chayes, J., Immorlica, N., Jain, K., Etesami, O., & Mahdian, M. (2007, May). Dynamics of bid optimization in online advertisement auctions. In Proceedings of the 16th International Conference on World Wide Web (WWW’07) (pp. 531-540), Banff, Canada.
-
[13].Broder, A. (2002, September). A taxonomy of web search. In ACM SIGIR Forum (Vol. 36, No. 2, pp. 3-10), New York, NY, USA. ACM.
-
[14].Broder, A., Fontoura, M., Josifovski, V., & Riedel, L. (2007, July). A semantic approach to contextual advertising. In Proceedings of the 30th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR’07) (pp. 559-566), Amsterdam, The Netherlands. ACM.
-
[15].Brown, P. F., Della Pietra, S. A., Della Pietra, V. J., & Mercer, R. L. (1993). The mathematics of statistical machine translation: Parameter estimation. Computational Linguistics, 19(2), 263-311.
-
[16].Budinich, M., Codenotti, B., Geraci, F., & Pellegrini, M. (2010, September). On the benefits of keyword spreading in sponsored search auctions: an experimental analysis. In International Conference on Electronic Commerce and Web Technologies (pp. 158-171), Springer, Berlin, Heidelberg.
-
[17].Cai, H., Ren, K., Zhang, W., Malialis, K., Wang, J., Yu, Y., & Guo, D. (2017, February). Real-time bidding by reinforcement learning in display advertising. In Proceedings of the 10th ACM International Conference on Web Search and Data Mining (WSDM’11) (pp. 661-670), Cambridge, UK. ACM.
-
[18].Carpineto, C., & Romano, G. (2012). A survey of automatic query expansion in information retrieval. ACM Computing Surveys (CSUR), 44(1), 1-50.
-
[19].Chang, W., Pantel, P., Popescu, A. M., & Gabrilovich, E. (2009, April). Towards intent-driven bidterm suggestion. In Proceedings of the 18th International Conference on World Wide Web (WWW’09) (pp. 1093-1094), Madrid, Spain.
-
[20].Charnes, A., & Cooper, W. W. (1959). Chance-constrained programming. Management Science, 6(1), 73-79.
-
[21].Chatwin, R. E. (2013, June). An overview of computational challenges in online advertising. In 2013 American Control Conference (pp. 5990-6007). Washington, DC. IEEE.
-
[22].Chen, Y., Xue, G. R., & Yu, Y. (2008, February). Advertising keyword suggestion based on concept hierarchy. In Proceedings of the 2008 International Conference on Web Search and Data Mining (WSDM’08) (pp. 251-260), Palo Alto, CA, USA. ACM.
-
[23].Cherepakhin, I. (2021). Structure Best Practices: How to Create Your Campaigns & Ad Groups. https://www.searchenginejournal.com/ppc-guide/ad-groups/ (accessed on Sep 2, 2022).
-
[24].Chung, J., Gulcehre, C., Cho, K., & Bengio, Y. (2014). Empirical evaluation of gated recurrent neural networks on sequence modeling. In NIPS 2014 Deep Learning and Representation Learning Workshop.
-
[25].Da, Z., Engelberg, J., & Gao, P. (2011). In search of attention. The Journal of Finance, 66(5), 1461-1499.
-
[26].Dhar, V., & Ghose, A. (2010). Research commentary—Sponsored search and market efficiency. Information Systems Research, 21(4), 760-772.
-
[27].Du, X., Su, M., Zhang, X., & Zheng, X. (2017). Bidding for multiple keywords in sponsored search advertising: Keyword categories and match types. Information Systems Research, 28(4), 711-722.
-
[28].Freund, Y., & Schapire, R. E. (1999). Large margin classification using the perceptron algorithm. Machine Learning, 37(3), 277-296.
-
[29].Fuxman, A., Tsaparas, P., Achan, K., & Agrawal, R. (2008, April). Using the wisdom of the crowds for keyword generation. In Proceedings of the 17th International Conference on World Wide Web (WWW’08) (pp. 61-70), Beijing, China.
-
[30].García-Cascales, M. S., & Lamata, M. T. (2012). On rank reversal and TOPSIS method. Mathematical and Computer Modelling, 56(5-6), 123-132.
-
[31].George, T. (2019) How to use amazon advertising’s dynamic bidding feature, https://searchengineland.com/how-to-use-amazon-advertisings-dynamic-bidding-feature-320505 (accessed on Sep 2, 2022).
-
[32].GM, P. K., Leela, K. P., Parsana, M., & Garg, S. (2011, February). Learning website hierarchies for keyword enrichment in contextual advertising. In Proceedings of the 4th ACM International Conference on Web Search and Data Mining (WSDM’11) (pp. 425-434), Hong Kong, China. ACM.
-
[33].Gopal, R., Li, X., & Sankaranarayanan, R. (2011). Online keyword based advertising: Impact of ad impressions on own-channel and cross-channel click-through rates. Decision Support Systems, 52(1), 1-8.
-
[34].Grbovic, M., Djuric, N., Radosavljevic, V., Silvestri, F., Baeza-Yates, R., Feng, A., Ordentlich, E., Yang, L., & Owens, G. (2016, July). Scalable semantic matching of queries to ads in sponsored search advertising. In Proceedings of the 39th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR’16) (pp. 375-384), Pisa, Italy. ACM.
-
[35].Gupta, S., Bilenko, M., & Richardson, M. (2009, June). Catching the drift: learning broad matches from clickthrough data. In Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (pp. 1165-1174). ACM.
-
[36].Ha, L. (2008). Online advertising research in advertising journals: A review. Journal of Current Issues & Research in Advertising, 30(1), 31-48.
-
[37].Haveliwala, T. H. (2003). Topic-sensitive pagerank: A context-sensitive ranking algorithm for web search. IEEE Transactions on Knowledge and Data Engineering, 15(4), 784-796.
-
[38].Hill, S. (2018). How to structure google ads search campaigns. https://creativewebsitemarketing.com/google-ads-campaign-structure/ (accessed on Sep 2, 2022).
-
[39].Hou, L. (2015). A hierarchical Bayesian network-based approach to keyword auction. IEEE Transactions on Engineering Management, 62(2), 217-225.
-
[40].Interactive Advertising Bureau*. IAB Annual Report 2021.* Available at https://www.iab.com/wpcontent/uploads/2022/04/IAB\_Internet\_Advertising\_Revenue\_Report\_Full\_Year\_2021.pdf (accessed on Jun 28, 2022).
-
[41].Jadidinejad, A. H., & Mahmoudi, F. (2014). Advertising keyword suggestion using relevancebased language models from wikipedia rich articles. Journal of Computer & Robotics, 7(2), 29- 35.
-
[42].Jansen, B. J., Booth, D. L., & Spink, A. (2008). Determining the informational, navigational, and transactional intent of Web queries. Information Processing & Management, 44(3), 1251-1266.
-
[43].Ji, L., Rui, P., & Hansheng, W. (2010). Selection of best keywords. Journal of Interactive Advertising, 11(1), 27–35.
-
[44].Joshi, A., & Motwani, R. (2006, December). Keyword generation for search engine advertising. In 6th IEEE International Conference on Data Mining-Workshops (ICDMW’06) (pp. 490-496), Hong Kong, China. IEEE.
-
[45].Katona, Z., & Sarvary, M. (2010). The race for sponsored links: Bidding patterns for search advertising. Marketing Science, 29(2), 199-215.
-
[46].Kiritchenko, S., & Jiline, M. (2008, September). Keyword optimization in sponsored search via feature selection. In Proceedings of the Workshop on New Challenges for Feature Selection in Data Mining and Knowledge Discovery at ECML/PKDD 2008, (pp. 122-134), Antwerp, Belgium. JMLR.
-
[47].Krasňanská, D., Komara, S., & Vojtková, M. (2021). Keyword categorization using statistical methods. TEM Journal, 10(3), 1377-1384.
-
[48].Küçükaydin, H., Selçuk, B., & Özlük, Ö. (2019). Optimal keyword bidding in search-based advertising with budget constraint and stochastic ad position. Journal of the Operational Research Society, 1-13.
-
[49].Lavrenko, V., & Croft, W. B. (2017, August). Relevance-based language models. In ACM SIGIR Forum (Vol. 51, No. 2, pp. 260-267). New York, USA. ACM.
-
[50].Lee, J. T., Lee, H., Park, H. S., Song, Y. I., & Rim, H. C. (2009, July). Finding advertising keywords on video scripts. In Proceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR’09) (pp. 686-687), Boston, Massachusetts, USA. ACM.
-
[51].Lee, J., Lee, Y., Kim, J., Kosiorek, A., Choi, S., & Teh, Y. W. (2019, May). Set transformer: A framework for attention-based permutation-invariant neural networks. In Proceedings of the 36th International Conference on Machine Learning (ICML’19) (pp. 3744-3753), Long Beach, CA, USA. PMLR.
-
[52].Li, H., & Yang, Y. (2020). Optimal keywords grouping in sponsored search advertising under uncertain environments. International Journal of Electronic Commerce, 24(1), 107-129.
-
[53].Li, H., & Yang, Y. (2022). Keyword Targeting Optimization in Sponsored Search Advertising: Combining Selection and Matching*. Electronic Commerce Research and Applications*, 56, 101209.
-
[54].Li, H., Zhang, D., Hu, J., Zeng, H. J., & Chen, Z. (2007, August). Finding keyword from online broadcasting content for targeted advertising. In Proceedings of the 1st International Workshop on Data Mining and Audience Intelligence for Advertising (ADKDD’07) (pp. 55-62), San Jose, CA, USA. ACM.
-
[55].Mabroukeh, N. R., & Ezeife, C. I. (2010). A taxonomy of sequential pattern mining algorithms. ACM Computing Surveys (CSUR), 43(1), 1-41.
-
[56].Markowitz, H. (1952). Portfolio selection. The Journal of Finance, 7(1), 77-91.
-
[57].Mikolov, T., Sutskever, I., Chen, K., Corrado, G. S., & Dean, J. (2013). Distributed representations of words and phrases and their compositionality. Advances in Neural Information Processing Systems, 26.
-
[58].Mirizzi, R., Ragone, A., Di Noia, T., & Di Sciascio, E. (2010, October). Semantic tags generation and retrieval for online advertising. In Proceedings of the 19th ACM International Conference on Information and Knowledge Management (CIKM’10) (pp. 1089-1098), Toronto, Ontario, Canada. ACM.
-
[59].Moorthy, K. S. (1985). Using game theory to model competition. Journal of Marketing Research, 22(3), 262-282.
-
[60].Navigli, R. (2009). Word sense disambiguation: A survey. ACM Computing Surveys (CSUR), 41(2), 1-69.
-
[61].Nie, H., Yang, Y., & Zeng, D., (2019). Keyword Generation for Sponsored Search Advertising: Balancing Coverage and Relevance. IEEE Intelligent Systems, 34(5), 14 - 24.
-
[62].One PPC (2022). How to build a Google Ads account structure that works well. https://oneppcagency.co.uk/google-ads/account-structure/ (accessed on Sep 2, 2022).
-
[63].Opper, M., & Winther, O. (1999). A Bayesian approach to on-line learning. Saad, David (ed.) Publications of the Newton Institute. Cambridge: Cambridge University Press.
-
[64].Ortiz-Cordova, A. and Jansen, B. J. (2012). Classifying web search queries to identify high revenue generating customers. Journal of the American Society for Information Science and Technology, 63 (7), 1426-1441.
-
[65].Ortiz-Cordova, A., Yang, Y., & Jansen, B. J. (2015). External to internal search: Associating searching on search engines with searching on sites. Information Processing & Management, 51(5), 718-736.
-
[66].Polato, M., Demchenko, D., Kuanyshkereyev, A., & Navarin, N. (2021, December). Efficient Multilingual Deep Learning Model for Keyword Categorization. In 2021 IEEE Symposium Series on Computational Intelligence (SSCI’21) (pp. 01-08), Orlando, FL, USA. IEEE.
-
[67].Qiao, D., Zhang, J., Wei, Q., & Chen, G. (2017). Finding competitive keywords from query logs to enhance search engine advertising. Information & Management, 54(4), 531-543.
-
[68].Radlinski, F., Broder, A., Ciccolo, P., Gabrilovich, E., Josifovski, V., & Riedel, L. (2008, July). Optimizing relevance and revenue in ad search: a query substitution approach. In Proceedings of the 31st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR’08) (pp. 403-410). Singapore. ACM.
-
[69].Ravi, S., Broder, A., Gabrilovich, E., Josifovski, V., Pandey, S., & Pang, B. (2010, February). Automatic generation of bid phrases for online advertising. In Proceedings of the 3rd ACM International Conference on Web Search and Data Mining (WSDM’10) (pp. 341-350), New York, USA. ACM.
-
[70].Regelson, M., & Fain, D. (2006, January). Predicting click-through rate using keyword clusters. In Proceedings of the 2nd Workshop on Sponsored Search Auctions (EC’06) (Vol. 9623, pp. 1-6), Ann Arbor, MI. ACM.
-
[71].Rusmevichientong, P., & Williamson, D. P. (2006, June). An adaptive algorithm for selecting profitable keywords for search-based advertising services. In Proceedings of the 7th ACM Conference on Electronic Commerce (EC’06) (pp. 260-269). Ann Arbor, Michigan. ACM.
-
[72].Rutz, O. J., Bucklin, R. E., & Sonnier, G. P. (2012). A latent instrumental variables approach to modeling keyword conversion in paid search advertising. Journal of Marketing Research, 49(3), 306-319.
-
[73].Saravia, A. (2020). 5 brilliant tips to strengthen your google ads campaign structure*.* https://www.whitesharkmedia.com/blog/google-ads/campaign-structure/ (accessed on Sep 2, 2022).
-
[74].Sarmento, L., Trezentos, P., Gonçalves, J. P., & Oliveira, E. (2009, June). Inferring local synonyms for improving keyword suggestion in an on-line advertisement system. In Proceedings of the 3rd International Workshop on Data Mining and Audience Intelligence for Advertising (ADKDD’09) (pp. 37-45), Paris, France. ACM.
-
[75].Scaiano, M., & Inkpen, D. (2011, September). Finding negative key phrases for internet advertising campaigns using wikipedia. In Proceedings of the International Conference Recent Advances in Natural Language Processing 2011 (pp. 648-653), Hissar, Bulgaria.
-
[76].Scholkopf, B. (1999). Making large scale SVM learning practical. Advances in Kernel Methods: Support Vector Learning, 41-56.
-
[77].Scholz, M., Brenner, C., & Hinz, O. (2019). AKEGIS: automatic keyword generation for sponsored search advertising in online retailing. Decision Support Systems, 119, 96-106.
-
[78].Schwaighofer, A., Candela, J. Q., Borchert, T., Graepel, T., & Herbrich, R. (2009, June). Scalable clustering and keyword suggestion for online advertisements, In Proceedings of the 3rd International Workshop on Data Mining and Audience Intelligence for Advertising (ADKDD’09) (pp. 27–36), Paris, France. ACM.
-
[79].Search Engine Land (2022). PPC Guide: How to structure search campaigns https://searchengineland.com/guide/ppc/search-campaign-structure (accessed on Sep 2, 2022).
-
[80].Shatnawi, M., & Mohamed, N. (2012, March). Statistical techniques for online personalized advertising: a survey. In Proceedings of the 27th Annual ACM Symposium on Applied Computing (SAC’12) (pp. 680-687), Riva del Garda, Italy. ACM.
-
[81].Singh, S. K., & Roychowdhury, V. P. (2008) To broad-match or not to broad-match: An auctioneer’s dilemma. In Proceedings of the 4th Workshop on Ad Auctions, Conference on Electronic Commerce (EC’08), Chicago, IL.
-
[82].Sutskever, I., Vinyals, O., & Le, Q. V. (2014). Sequence to sequence learning with neural networks. Advances in Neural Information Processing Systems, 3104–3112.
-
[83].Symitsi, E., Markellos, R. N., & Mantrala, M. K. (2022). Keyword portfolio optimization in paid search advertising. European Journal of Operational Research, 303(2), 767-778.
-
[84].Thomaidou, S., & Vazirgiannis, M. (2011, July). Multiword keyword recommendation system for online advertising. In 2011 International Conference on Advances in Social Networks Analysis and Mining (ASONAM’11) (pp. 423-427). Taiwan, China. IEEE.
-
[85].Welch, M. J., Cho, J., & Chang, W. (2010, October). Generating advertising keywords from video content. In Proceedings of the 19th ACM International Conference on Information and Knowledge Management (CIKM’10) (pp. 1421-1424). Toronto, Ontario, Canada. ACM.
-
[86].Whitney, M. (2022). 6 steps to building a brilliant paid search account structure. Available at https://www.wordstream.com/blog/ws/2015/03/06/adwords-account-structure (accessed on Sep 2, 2022).
-
[87].Wu, H., Qiu, G., He, X., Shi, Y., Qu, M., Shen, J., Bu, C. & Chen, C. (2009, April). Advertising keyword generation using active learning. In Proceedings of the 18th International Conference on World Wide Web (WWW’09) (pp. 1095-1096), Madrid, Spain. ACM.
-
[88].Wu, X., & Bolivar, A. (2008, April). Keyword extraction for contextual advertisement. In Proceedings of the 17th International Conference on World Wide Web (WWW’08) (pp. 1195-1196), Beijing, China. ACM.
-
[89].Xia, F., Liu, J., Nie, H., Fu, Y., Wan, L., & Kong, X. (2019). Random walks: A review of algorithms and applications. IEEE Transactions on Emerging Topics in Computational Intelligence, 4(2), 95- 107.
-
[90].Yang, S., Pancras, J., & Song, Y. A. (2021). Broad or exact? Search Ad matching decisions with keyword specificity and position. Decision Support Systems, 143, 113491.
-
[91].Yang, Y. and Zhai, P. (2022). Click-through rate prediction in online advertising: A literature review. Information Processing & Management, 59(2), 102853.
-
[92].Yang, Y., J. Zhang, R. Qin, J. Li, F. Wang, W. Qi (2012). A Budget optimization framework for search advertisements across markets, IEEE Transactions on Systems, Man, and Cybernetics. Part A: Systems and Humans, 42(5): 1141-1151.
-
[93].Yang, Y., Li, X., Zeng, D., and Jansen, B. J., (2018). Aggregate effects of advertising decisions: a complex systems look at search engine advertising via an experimental study. Internet Research, 28(4), 1079-1102.
-
[94].Yang, Y., Qin, R., Jansen, B. J., Zhang, J., & Zeng, D. (2014). Budget planning for coupled campaigns in sponsored search auctions. International Journal of Electronic Commerce, 18(3), 39- 66.
-
[95].Yang, Y., Yang, Y. C., Jansen, B. J., and Lalmas, M. (2017). Computational Advertising: A Paradigm Shift for Advertising and Marketing?. IEEE Intelligent Systems, 32(3), 3-6.
-
[96].Yang, Y., Yang, Y., Guo, X., and Zeng, D. (2019). Keyword optimization in sponsored search advertising: a multi-level computational framework. IEEE Intelligent Systems, 34(1), 32-42.
-
[97].Yang, Y., Zeng, D., Yang, Y., & Zhang, J. (2015). Optimal budget allocation across search advertising markets. Informs Journal on Computing, 27(2), 285-300.
-
[98].Yang, Y., Zhang, J., Qin, R., Li, J., Liu, B., & Liu, Z. (2013). Budget strategy in uncertain environments of search auctions: A preliminary investigation. IEEE Transactions on Services Computing, 6(2), 168-176.
-
[99].Yang, Y., Zhao, K., Zeng, D. D., & Jansen, B. J. (2022). Time-varying effects of search engine advertising on sales–An empirical investigation in E-commerce. Decision Support Systems, 113843. https://doi.org/10.1016/j.dss.2022.113843
-
[100].Ye, S., Aydin, G., & Hu, S. (2015). Sponsored search marketing: Dynamic pricing and advertising for an online retailer. Management Science, 61(6), 1255-1274.
-
[101].Yi, J., & Maghoul, F. (2009, April). Query clustering using click-through graph. In Proceedings of the 18th International Conference on World Wide Web (WWW’09) (pp. 1055-1056), Madrid, Spain. ACM.
-
[102].Yih, W. T., Goodman, J., & Carvalho, V. R. (2006, May). Finding advertising keywords on web pages. In Proceedings of the 15th International Conference on World Wide Web (WWW’06) (pp. 213-222), Edinburgh, Scotland. ACM.
-
[103].Zaheer, M., Kottur, S., Ravanbakhsh, S., Poczos, B., Salakhutdinov, R. R., & Smola, A. J. (2017). Deep sets. Advances in Neural Information Processing Systems, 30.
-
[104].Zhai, P., Yang, Y. and Zhang, C. (2023). Causality-based CTR Prediction using Graph Neural Networks. Information Processing & Management, 103137.
-
[105].Zhang, J., & Qiao, D. (2018). A Novel Keyword Suggestion Method for Search Engine Advertising. In Proceedings of the 22nd Pacific Asia Conference on Information Systems (PACIS’18) (p. 305), Yokohama, Japan.
-
[106].Zhang, J., Yang, Y., Li, X., Qin, R., & Zeng, D. (2014a). Dynamic dual adjustment of daily budgets and bids in sponsored search auctions. Decision Support Systems, 57, 105-114.
-
[107].Zhang, J., Zhang, J., & Chen, G. (2021). A semantic transfer approach to keyword suggestion for search engine advertising. Electronic Commerce Research, forthcoming. https://doi.org/10.1007/ s10660-021-09496-7.
-
[108].Zhang, W., Wang, D., Xue, G. R., & Zha, H. (2012a). Advertising keywords recommendation for short-text web pages using Wikipedia. ACM Transactions on Intelligent Systems and Technology (TIST), 3(2), 36.
-
[109].Zhang, W., Zhang, Y., Gao, B., Yu, Y., Yuan, X., & Liu, T. Y. (2012b, August). Joint optimization of bid and budget allocation in sponsored search. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD’12) (pp. 1177-1185), Beijing, China. ACM.
-
[110].Zhang, X., & Feng, J. (2011). Cyclical bid adjustments in search-engine advertising. Management Science, 57(9), 1703-1719.
-
[111].Zhang, Y., Zhang, W., Gao, B., Yuan, X., & Liu, T. Y. (2014b). Bid keyword suggestion in sponsored search based on competitiveness and relevance. Information Processing & Management, 50(4), 508-523.
-
[112].Zhou, H., Huang, M., Mao, Y., Zhu, C., Shu, P., & Zhu, X. (2019, May). Domain-Constrained Advertising Keyword Generation. In Proceedings of the International Conference on World Wide Web (WWW’19) (pp. 2448-2459), San Francisco, CA, USA. ACM.
-
[113].Zhou, N., Wu, J., & Zhang, S. (2007). A keyword extraction based model for web advertisement. In Integration and Innovation Orient to E-Society, Volume 2 (pp. 168-175), Springer, Boston, MA.
-
[114].Zhou, Y., Chakrabarty, D., & Lukose, R. (2008, December). Budget constrained bidding in keyword auctions and online knapsack problems. In International Workshop on Internet and Network Economics (WINE’08) (pp. 566-576). Springer, Berlin, Heidelberg. ACM.
-
[115].Zirnheld, C. (2020). Google Ads account structure*.* https://cypressnorth.com/resources/guide/google-ads-account-structure/ (accessed on Sep 2, 2022).