Keyword Level Bayesian Online Bid Optimization For Sponsored Search Advertising
Abstract
Section titled “Abstract”Bid price optimization in online advertising is a challenging task due to its high uncertainty. In this paper, we propose a bid price optimization algorithm focused on keyword-level bidding for pay-per-click sponsored search ads, which is a realistic setting for many firms. There are three characteristics of this setting: “The setting targets the optimization of bids for each keyword in pay-per-click sponsored search advertising”, “The only information available to advertisers is the number of impressions, clicks, conversions, and advertising cost for each keyword”, and “Advertisers bid daily and set monthly budgets on a campaign basis”. Our algorithm first predicts the performance of keywords as a distribution by modeling the relationship between ad metrics through a Bayesian network and performing Bayesian inference. Then, it outputs the bid price by means of a bandit algorithm and online optimization. This approach enables online optimization that considers uncertainty from the limited information available to advertisers. We conducted simulations using real data and confirmed the effectiveness of the proposed method for both open-source data and data provided by negocia, Inc., which provides an automated Internet advertising management system.
Keywords Online advertising · Bid price optimization · Bayesian inference · Bandit algorithm · Online optimization
1 Introduction
Section titled “1 Introduction”With advances in information technology, the Internet advertising market has continued to grow year after year. Internet advertising revenue in the USA in 2021 was 189 billion USD, which is 2.9 times greater than TV ad spending in the same year [1, 2]. Against this background, Internet advertising has become indispensable for corporate promotion, regardless of the size of the company.
In this paper, we propose a machine learning method that automatically determines some of the configuration items in advertising operations from the perspective of an advertiser (a company placing Internet advertisements). Our focus point is the difficulty advertisers face in managing advertisements. To effectively distribute advertisements, a great deal of information in addition to user responses is necessary, including detailed attribute information on users who have viewed advertisements and information on competing advertisers. However, most of this information is not disclosed to advertisers, even though it is owned by the advertising platform. Advertisers thus need to make decisions based only on limited information, and many of them currently outsource their ad operations to agencies as a result. Our objective is to offer a machine learning method that automatically determines some delivery settings using only the information available to the advertiser, thereby supporting efficient operation of Internet advertising by the advertiser alone, independent of an agency.
We focus on determining bid prices for sponsored search ads, particularly Amazon ads. Sponsored search ads are ads that appear on search results screens in conjunction with the search terms entered, and as of 2021, they accounted for 41.4% of U.S. Internet advertising revenue (78.3 USD) [2]. The bid price is the maximum amount an advertiser can pay for one click on an ad. This parameter is crucial because it directly affects the cost of advertising and the sales generated via advertising. Note that while many studies on bid price optimization in sponsored search have utilized the search rank of the advertisement for optimization, the Amazon advertisements covered in this paper do not use search rank because it is not possible to obtain it due to its terms of use. We therefore propose a method for automatically determining bid prices for sponsored search ads using the limited information available to advertisers.
The key contributions of this work are as follows:
- We mathematically modeled the bid optimization in a realistic setting consisting of three characteristics: “The setting targets the optimization of bids for each keyword in pay-per-click sponsored search advertising”, “The only information available to advertisers is the number of impressions, clicks, conversions, and advertising cost for each keyword”, and “Advertisers bid daily and set monthly budgets on a campaign basis”. This setting was proposed in a joint research project with negocia, Inc., which provides an automated Internet advertising management system, and is a common situation faced by many companies. To our best knowledge, there have been no prior studies on bid optimization in similar settings.
- We proposed Bayesian AdComB, an algorithm that optimizes the bid price from the limited information available to advertisers. The algorithm models the relationships among advertising metrics by constructing a Bayesian network and then implements Bayesian inference to estimate the distribution of those metrics, tak-ing into account the uncertainty of Internet advertising. The bid price optimization is then performed online with the aid of a bandit algorithm, which is designed to maximize the cumulative long-term reward in situations where estimation and optimization must be done sequentially. This bid price optimization problem can be solved by reformulating it as an integer programming problem.
• We ran simulations using real data from negocia, Inc. and the iPinYou dataset [3], which is an open dataset. The results demonstrated not only the effectiveness of our proposed method but also the flexibility and extensibility of the framework.
Section 2 of this paper describes the problem setting of bid amount optimization, and Section 3 introduces related work. In Section 4, we explain the proposed method, and in Section 5, we present the numerical experiments we conducted to verify the effectiveness of our method. We conclude in Section 6 with a brief summary and mention of future work.
2 Problem Setting
Section titled “2 Problem Setting”2.1 Bid Optimization for Sponsored Search Ads
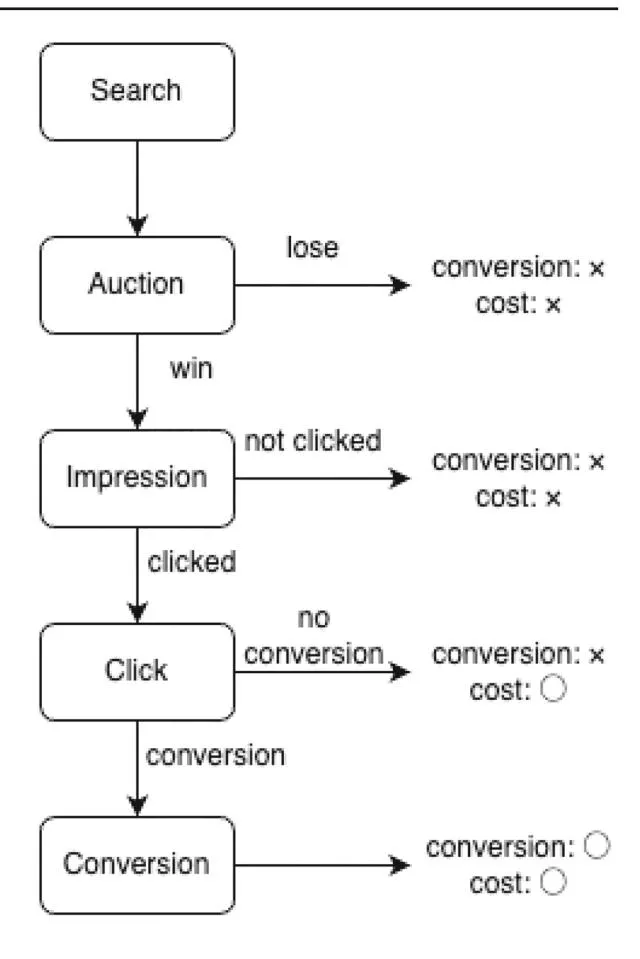
Section titled “2.1 Bid Optimization for Sponsored Search Ads”The focus of this work is bid price optimization at the keyword level for pay-per-click sponsored search advertising. Sponsored search advertising generates sales through a five-step process: search, auction, impression, click, and conversion, as shown in Fig. 1. Advertisers using sponsored search ads register multiple phrases called keywords for each advertisement. When a user performs a search, an auction is held among advertisers whose keywords match the search phrase, and the winning advertisement is displayed to the user (impression). This auction is typically a second-price auction, in which the price paid is the bid of the second-place bidder. On advertising platforms such as Google Ads and Amazon Ads, the results of this auction are affected not only by the bid price for specific keywords but also by an undisclosed score calculated by the advertising platform [4, 5]. In pay-per-click advertising, advertising costs are incurred only when a user clicks on the ad. After a click, the advertiser seeks to generate a conversion (e.g., purchase of a product).
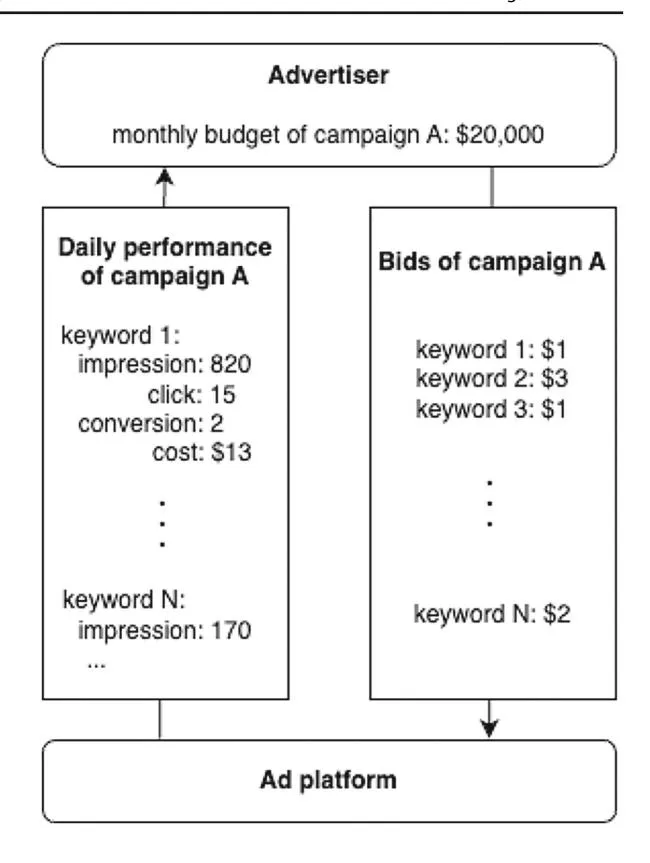
The interaction between advertisers and ad platforms is shown in Fig. 2. Advertisers manage multiple keywords in a unit called a campaign, and bid prices are determined daily for all keywords in the campaign. Note that advertisers cannot change their bid prices during the course of the day. Advertisers receive daily feedback from the ad platform, including the number of impressions, clicks, and conversions as well as the advertising cost for each keyword. However, some information is not available, such as the number of times the keyword was searched, the bid prices of other advertisers, and ad positions. Also, advertisers set budgets for the entire campaign but cannot set budgets for individual keywords. This budget is set over a longer span of time than the bid, e.g., on a monthly basis. If the budgeted amount runs out in the middle of the period, ads will not be displayed unless the budget is increased. It is extremely important for advertisers to avoid situations like this, as it represents a serious opportunity loss.
Fig. 1 Flow of a user’s search through a search engine and conversion through sponsored search advertising
Overall, the setting we examine is characterized by the following three main features:
- Bid price optimization is targeted at the keyword level for pay-per-click sponsored search ads
-
- The only information available to advertisers is the number of impressions, clicks, and conversions and the advertising cost for each keyword
-
- Advertisers determine bid prices daily and set monthly budgets for the entire campaign
This setting was proposed in a joint research project with negocia, Inc., which provides an automated Internet advertising management system.
2.2 Problem Formulation
Section titled “2.2 Problem Formulation”The bid price optimization in our setting can be formulated as follows. Let N be the total number of keywords, T the total number of bidding rounds, and the bid price
Fig. 2 Interaction between advertisers and ad platforms
for keyword i in period t. b, are the minimum and maximum bid prices that can be set, and , are the ad cost and conversion if we set a bid price of b for keyword i in period t. Also, we define for . The advertiser’s goal is to maximize the total number of conversions with an advertising cost below B.
subject to
(1)
The objective function of optimization problem (1) shows the total number of conversions throughout all rounds, and the first constraint shows the constraint that the total ad cost throughout all rounds is within the budget B. The second constraint shows that there is a fixed range that can be set for bid prices for all keywords in all rounds. In this formulation, ad cost and the number of conversions for each keyword
are expressed as a function of bid price, ci(b), ui(b), but these functions are unknown and must be predicted from the previous data.
2.3 Challenges
Section titled “2.3 Challenges”There are two main challenges with bid price optimization in the problem setting discussed Section 2.1: high uncertainty and the need for sequential forecasting and optimization. The uncertainty is caused by three main factors. The first factor is the scarcity of positive example data. In pay-per-click advertising, neither conversions nor advertising costs occur unless an ad is clicked on. However, click-through rates for Internet advertising are very low: according to a survey, the average click-through rates are 3.17% for sponsored search ads on Google and 0.46% for display ads [6]. Therefore, some keywords have very few (or no) clicks, making the prediction of conversions and advertising cost inaccurate. The second factor is the paucity of data available to advertisers. To optimize bid prices, information such as competitors’ bids, the demographics of the ad’s viewers, and the location of the ad is very important, but such information is often not available to advertisers. Therefore, advertisers must determine bid prices from limited information such as daily ad impressions, clicks, conversions, and advertising cost, which makes accurate forecasting difficult. The third factor is uncertainty derived from human behavior. User behavior such as clicks and conversions is difficult to predict because it is related to various factors such as user demographics, personality, and time. This uncertainty creates the need for sequential estimation and optimization. Bid price optimization requires knowing the conversions, advertising cost, and other advertising metrics for all possible bid price candidates, but the aforementioned uncertainties make it difficult to make predictions with sufficient accuracy. Therefore, an approach that optimizes the bid price once and fixes it thereafter is not likely to be the optimal strategy, and sequential estimation and optimization are required each time the information is updated.
3 Related Work
Section titled “3 Related Work”Bid price optimization for Internet advertising has been studied under various conditions, including different types of ads, bidding styles, and constraints.
Examples of studies on bid price optimization for sponsored search advertising include works by [7–11]. Feng et al. [7] formulated the bid price optimization problem as an adversarial bandit problem and proposed an algorithm based on Exponentialweight policy for Exploration and Exploitation (Exp3) [12] to optimize bid prices for sponsored search advertising. Their algorithm focuses on optimizing a single bid price without considering budget constraints. Abhishek et al. [8] optimize bids by creating a model that predicts the number of clicks and ad costs based on multiple assumptions. Thomaidou et al. [9] proposed a comprehensive operational framework for sponsored search that includes bid price optimization and automatic ad text generation. Zhang et al. [10] approximate and optimize the bid price optimization problem as a sequential quadratic programming problem. However, the methods proposed in these papers
require information that is difficult for advertisers to obtain, such as the location of the ads on the search result page. Uncertainty in sponsored search advertising is a challenge in contexts other than bid price optimization. Rusmevichientong et al. [13] proposed a method to prioritize keywords for bidding with uncertainty, and [14, 15] optimize the budget allocation for sponsored search advertising with uncertainty on the basis of investment portfolio theory.
Avadhanula et al. [16] and Nuara et al. [17] examined bid price optimization for multiple platforms. Avadhanula et al. [16] provided a multi-platform bid price optimization algorithm based on a method called stochastic bandits with knapsacks [18]. Their algorithm is designed for a setting with a high frequency of bid price decisions, such as real-time bidding for display advertising, and thus is not suitable for the setting of this paper, where bid prices can be changed only once a day at most. Nuara et al. [17] formulated a bid price/daily budget optimization problem for multiple platforms as a combinatorial semi-bandit problem [19] and provided an algorithm for simultaneous optimization. Their algorithm is based on the Gaussian process upper confidence bound (GP-UCB) [20], which predicts conversions and advertising costs for each bid price candidate and then optimizes bid prices using dynamic programming. Although their algorithm targets bid price optimization for multiple platforms, it can be extended to our setting, namely, multiple keywords on a single platform. However, we cannot directly apply their algorithm because it is not possible to control advertising costs by setting individual daily budgets in our setting.
Studies that have applied Bayesian inference to the field of Internet advertising include works by [21-26]. Hou et al. [24] have made ROI predictions for a portfolio consisting of multiple keywords in sponsored search advertising. They modeled the relationship between bid prices, clicks, conversions, and other advertising metrics using Bayesian networks, which is an approach similar to the Bayesian modeling utilized in this study. However, their study aimed to predict the ROI of advertising and did not optimize bid prices. Agarwal et al. [21], Du et al. [22], Ghose and Yang [23] and Yang and Ghose [26] discuss the relationship between coefficients by linearly modeling the relationship between the indicators and examining the posterior distribution of the coefficients. Yang et al. [25] focus on the hierarchical structure that exists among ads, platforms, and users and utilize Hierarchical Bayes to estimate click rates for specific ads, platforms, and users.
4 Method
Section titled “4 Method”Our proposed method, Bayesian advertising combinatorial bandit (Bayesian AdComB), consists of three subroutines inspired by the method of Nuara et al. [17]. The flow of the proposed method is shown in Algorithm 1.
The algorithm first updates the probability model for each keyword using the advertising metrics obtained in the previous round by update subroutine (line 5). We model the relationships among advertising metrics by a Bayesian network and derive the posterior distribution by Bayesian inference. Next, exploration subroutine (line 6) selects the functions and for optimization from the model
Algorithm 1 Bayesian AdComB
Section titled “Algorithm 1 Bayesian AdComB”Require: set \mathcal{B} of bid price, prior distribution \{\mathcal{M}_i^{(0)}\}_{i=1}^N, total budget B, total round T1: \bar{R} \leftarrow R2: for t \in \{1, ..., T\} do3: if \bar{B} > 0 then4: for i \in \{1, ..., N\} do \mathcal{M}_{i}^{(t)} \leftarrow \mathbf{Update}\left(\mathcal{M}_{i}^{(t-1)}, \left\{\mathrm{imp}_{i}^{\tau}, \mathrm{click}_{i}^{\tau}, \mathrm{cv}_{i}^{\tau}, \mathrm{cost}_{i}^{\tau}\right\}_{\tau=1}^{t-1}\right)5: ▶ Update subroutine (\hat{u}_i^t(b), \hat{c}_i^t(b)) \leftarrow \text{Exploration}(\mathcal{M}_i^{(t)}, \mathcal{B})6: ⊳ Exploration subroutine7. \{\hat{b}_i^t\}_{i=1}^N \leftarrow \text{Optimize}\left(\left\{\left(\hat{u}_i^t(b), \hat{c}_i^t(b)\right)\right\}_{i=1}^N, \mathcal{B}, \frac{\bar{B}}{T-t+1}\right)8:
▷ Optimization subroutine
bid with \{\hat{b}_i^t\}_{i=1}^N9: \bar{B} \leftarrow \bar{B} - \sum_{i=1}^{N} \operatorname{cost}_{i}^{t}10:11:12: break13: end if14: end fordistribution. We utilize a bandit algorithm for this selection. Finally, optimization subroutine (line 8) performs optimization using the function selected in the exploration subroutine. We reformulate Eq. (1) as an integer programming problem and optimize it using a general-purpose integer programming solver. Each subroutine is described in detail in the following subsections.
4.1 Update Subroutine
Section titled “4.1 Update Subroutine”The purpose of this subroutine is to estimate the distribution of conversions and advertising costs for each bid price candidate. Estimating these factors as a distribution rather than a point enables estimation that accounts for the high uncertainty. Our method constructs a Bayesian network to model the relationship between the bid price, the number of impressions, clicks, and conversions and the advertising costs, which are the advertising metrics available to advertisers. We then use Bayesian inference to obtain the posterior distribution.
For the probability model (prior distribution, likelihood function) in the generation process of the advertising metrics, if the log data accumulated so far exists, WAIC [27] in the log data is used as a criterion to select one of several candidates. In this paper, we propose four likelihood functions and two prior distributions that we consider reasonable. Although it is difficult to claim that a stochastic model is valid, the goodness of fit of a stochastic model to log data can be quantitatively evaluated by calculating WAIC in log data for any possible stochastic model. Therefore, it is possible to quantitatively compare stochastic models that are not included in this paper and select the model to be utilized. See Section 5.3.1 for the results of the WAIC comparison on the log data of the stochastic model proposed in this paper.
We consider four likelihood functions: (1) expressed by Fig. 3 and Eq. (2), (2) expressed by Fig. 4 and Eq. (3), (3) expressed by Fig. 5 and Eq. (4), and (4) expressed by Fig. 6 and Eq. (5). Note that these likelihood functions indicate the likelihood function
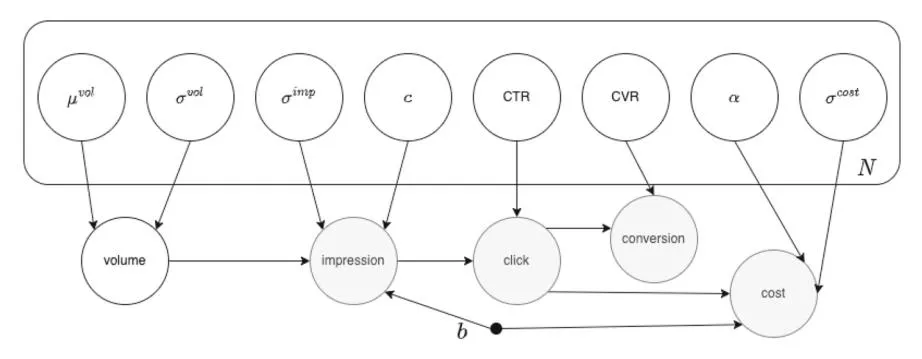
Fig. 3 Bayesian network with likelihood function 1
for the keyword i, where represents the normal distribution with mean and standard deviation , and Binomial(n, p) represents the binomial distribution with number of trials n and probability p.
\begin{aligned} \text{volume}_{i} &\sim \mathcal{N}\left(\mu_{i}^{\text{vol}}, \sigma_{i}^{\text{vol}^{2}}\right) \\ \text{imp}_{i} &\sim \mathcal{N}\left(\frac{b_{i}^{2}}{b_{i}^{2} + c_{i}^{2}} \cdot \text{volume}_{i}, \sigma_{i}^{\text{imp}^{2}}\right) \\ \text{click}_{i} &\sim \text{Binomial (imp}_{i}, \text{CTR}_{i}) \\ \text{cv}_{i} &\sim \text{Binomial (click}_{i}, \text{CVR}_{i}) \\ \text{cost}_{i} &\sim \mathcal{N}\left(\alpha_{i} \cdot b_{i} \cdot \text{click}_{i}, \sigma_{i}^{\text{cost}^{2}}\right). \end{aligned} \tag{2}
\operatorname{click}_{i} \sim \operatorname{Binomial}\left(\operatorname{imp}_{i}, \operatorname{CTR}_{i}\right) \operatorname{cv}_{i} \sim \operatorname{Binomial}\left(\operatorname{click}_{i}, \operatorname{CVR}_{i}\right) \operatorname{cost}_{i} \sim \mathcal{N}\left(\alpha_{i} \cdot b_{i} \cdot \operatorname{click}_{i}, \sigma_{i}^{\operatorname{cost}^{2}}\right).$$ (3)  <span id="page-8-2"></span>Fig. 4 Bayesian network with likelihood function 2  <span id="page-9-0"></span>Fig. 5 Bayesian network with likelihood function 3 <span id="page-9-1"></span> $$\begin{aligned} & \text{volume}_{i} \sim \mathcal{N}\left(\mu_{i}^{\text{vol}}, \sigma_{i}^{\text{vol}^{2}}\right) \\ & \text{imp}_{i} \sim \mathcal{N}\left(\frac{b_{i}^{2}}{b_{i}^{2} + c_{i}^{2}} \cdot \text{volume}_{i}, \sigma_{i}^{\text{imp}^{2}}\right) \\ & \text{click}_{i} \sim \text{Binomial}\left(\text{imp}_{i}, \text{CTR}_{i}\right) \\ & \text{cv}_{i} \sim \text{Binomial}\left(\text{click}_{i}, \text{CVR}_{i}\right) \\ & \text{cost}_{i} \sim \mathcal{N}\left((\alpha_{i} \cdot b_{i} + \beta_{i}) \cdot \text{click}_{i}, \sigma_{i}^{\text{cost}^{2}}\right). \end{aligned}$$ $$\begin{aligned} & \text{imp}_{i} \sim \mathcal{N}\left(a_{3i}b_{i}^{3} + a_{2i}b_{i}^{2} + a_{1i}b_{i} + a_{0i}, \sigma_{i}^{\text{imp}^{2}}\right) \\ & \text{click}_{i} \sim \text{Binomial}\left(\text{imp}_{i}, \text{CTR}_{i}\right) \\ & \text{cv}_{i} \sim \text{Binomial}\left(\text{click}_{i}, \text{CVR}_{i}\right) \\ & \text{cost}_{i} \sim \mathcal{N}\left((\alpha_{i} \cdot b_{i} + \beta_{i}) \cdot \text{click}_{i}, \sigma_{i}^{\text{cost}^{2}}\right). \end{aligned}$$ $$(5)$$ <span id="page-9-3"></span>In addition to the aforementioned advertising metrics, the model includes the search volume for each keyword, which is a metric that cannot be observed by the advertiser, and the keyword-specific parameters $\mu^{\rm vol}$ , $\sigma^{\rm vol}$ , $\sigma^{\rm imp}$ , c, CTR, CVR, $\alpha$ , and $\sigma^{\rm cost}$ . The process of generating the number of clicks and conversions for keywords is the same for all likelihood functions. In these formulations, the number of clicks and conversions is generated by a binomial distribution based on the click-through rate (CTR) and  <span id="page-9-2"></span>Fig. 6 Bayesian network with likelihood function 4 <span id="page-10-0"></span> | Table 1 | Characteristics of each | likelihood function | |---------|-------------------------|---------------------| | | | | | Likelihood function | Impression | Cost per click | |---------------------|-----------------------------|--------------------------------| | 1 | Consider search volume | Constant multiple of bid price | | 2 | Cubic function of bid price | Constant multiple of bid price | | 3 | Consider search volume | Linear function of bid price | | 4 | Cubic function of bid price | Linear function of bid price | conversion rate (CVR) for each keyword. The assumption that each keyword has a specific CTR and CVR is natural, given that there has been much research on CTR and CVR prediction in the Internet advertising field. The characteristics of each likelihood function are summarized in Table 1. Differences occur due to the changes made in the process of generating impressions and ad costs. The process of generating impressions in likelihood functions 1 and 3 takes into account search volume, which is information that cannot be observed by the advertiser. Since the search volume of a keyword indicates the number of times the keyword matches the search phrase, it is assumed to be generated from a normal distribution in which $\mu_i^{\text{vol}}$ , indicating the keyword's searchability, is the mean and $\sigma_i^{\text{vol}}$ , indicating the variation in the search volume of the keyword, is the standard deviation. We use $\frac{b_i^2}{b_i^2+c_i^2}$ as the ratio of the average number of impressions to the search volume (corresponding to the winning percentage of the auction), which is the formulation proposed by Zhang et al. [28]. In contrast, likelihood functions 2 and 4 assume that the number of impressions is generated from a normal distribution whose mean is a cubic function of bid prices. For the ad cost generation process, likelihood functions 1 and 2 assume that the ad cost per click is a constant multiple of the bid price, while likelihood functions 3 and 4 assume that the ad cost per click is a linear function of the bid price. In the case of a generalized secondprice auction, which is the auction format used on many advertising platforms, if the advertiser's quality score for an impression involving a click with keyword I is $QS_i$ , the quality score of a competitor one rank below the advertiser is QS' and the bid price is b', and the ad cost incurred for a click is expressed as $\frac{QS' \cdot b'}{OS_i}$ . Although information on quality scores and competitor bid prices is not disclosed, in likelihood functions 1 and 2, A is approximated by a constant, and in likelihood functions 3 and 4, B is approximated by a linear function. The two prior distributions considered in this paper are prior distribution A expressed by Eq. (6) and prior distribution B expressed by Eq. (7). Note that these prior distributions at keyword i, where Beta( $\alpha$ , $\beta$ ) represents the beta distribution with $\alpha$ , $\beta$ as the shape function, $\tilde{\mu}$ , $\tilde{\alpha}$ , $\beta$ are the parameters estimated by maximum likelihood estimation for the first round of logs, and C is the hyperparameter. Prior distribution A is a distribution designed to account for the effect of the prior distribution on the posterior distribution. A distribution whose prior distribution has no effect on the posterior distribution is called a non-informative prior distribution, but it is difficult to implement a non-informative prior distribution for complex likelihood functions using Bayesian modeling packages. Note that the prior distribution A therefore affects the posterior distribution, not the non-informative prior distribution. Prior distribution B is determined by maximum likelihood estimation for some parameters, and a normal distribution with large variance is used for other parameters. Maximum likelihood estimation is utilized to improve the fit of the posterior distribution to the data used in the selection and optimization subroutines. Since $a_{0i}$ , $a_{1i}$ , $a_{2i}$ , $a_{3i}$ , $\alpha_i$ , and $\beta_i$ are latent variables that may take negative values and the parameters determined by maximum likelihood estimation may not be used as the standard deviation of the normal distribution, the same distribution as the prior distribution A is used as the prior distribution of these latent variables. <span id="page-11-0"></span> $$\mu_{i}^{\text{vol}} = |\mathcal{N}(0, 10^{6})|$$ $$\sigma_{i}^{\text{vol}} = |\mathcal{N}(0, 10^{6})|$$ $$\sigma_{i}^{\text{imp}} = |\mathcal{N}(0, 10^{6})|$$ $$c_{i} = |\mathcal{N}(0, 10^{6})|$$ $$a_{0i} = \mathcal{N}(0, 10^{6})$$ $$a_{1i} = \mathcal{N}(0, 10^{6})$$ $$a_{2i} = \mathcal{N}(0, 10^{6})$$ $$a_{3i} = \mathcal{N}(0, 10^{6})$$ $$\text{CTR}_{i} = \text{Beta}(1, 1)$$ $$\text{CVR}_{i} = \text{Beta}(1, 1)$$ $$\alpha_{i} = \mathcal{N}(0, 10^{6})$$ $$\beta_{i} = \mathcal{N}(0, 10^{6})$$ $$\sigma_{i}^{\text{cost}} = |\mathcal{N}(0, 10^{6})|.$$ $$\mu_{i}^{\text{vol}} = \left| \mathcal{N} \left( \tilde{\mu}_{1}, (\tilde{\mu}_{1}/C)^{2} \right) \right|$$ $$\sigma_{i}^{\text{vol}} = \left| \mathcal{N} \left( \tilde{\mu}_{2}, (\tilde{\mu}_{2}/C)^{2} \right) \right|$$ $$\sigma_{i}^{\text{imp}} = \left| \mathcal{N} \left( \tilde{\mu}_{3}, (\tilde{\mu}_{3}/C)^{2} \right) \right|$$ $$c_{i} = \left| \mathcal{N} \left( \tilde{\mu}_{4}, (\tilde{\mu}_{4}/C)^{2} \right) \right|$$ $$a_{0i} = \mathcal{N}(0, 10^{6})$$ $$a_{1i} = \mathcal{N}(0, 10^{6})$$ $$a_{2i} = \mathcal{N}(0, 10^{6})$$ $$a_{3i} = \mathcal{N}(0, 10^{6})$$ $$CTR_{i} = \text{Beta}(\tilde{\alpha}_{1}, \tilde{\beta}_{1})$$ $$CVR_{i} = \text{Beta}(\tilde{\alpha}_{2}, \tilde{\beta}_{2})$$ <span id="page-12-0"></span> $$\alpha_i = \mathcal{N}(0, 10^6)$$ $$\beta_i = \mathcal{N}(0, 10^6)$$ $$\sigma_i^{\text{cost}} = \left| \mathcal{N} \left( \tilde{\mu}_5, (\tilde{\mu}_5/C)^2 \right) \right|. \tag{7}$$ Since the probability model used in the proposed method is too complex to calculate the posterior distribution analytically, we approximate it by stochastic variational inference instead [29]. Although the Markov chain Monte Carlo method (MCMC) [30] can be used to approximate the posterior distribution, the difference in the detailed shape of the posterior calculated by the update subroutine does not significantly affect the performance of the proposed method, and there is no need to obtain the exact shape of the posterior distribution. We therefore use stochastic variational inference from the viewpoint of computation time. In the stochastic model presented in this paper, $\mu_i^{\text{vol}}$ , $\sigma_i^{\text{vol}}$ , $a_{0i}$ , $a_{1i}$ , $a_{2i}$ , $a_{3i}$ , $\sigma_i^{\text{imp}}$ , $\sigma_i^{\text{cost}}$ , $\alpha_i$ , and $\beta_i$ are approximated by a normal distribution, and $CTR_i$ and $CVR_i$ are approximated by a beta distribution to optimize the variational parameters. From the second round onward, we reuse the posterior distribution from the previous round as the prior distribution and perform Bayesian estimation only with the newly obtained data. This approach, called sequential learning, speeds up the computation because it uses less data when computing the posterior distribution. Our Bayesian AdComB framework can be flexibly extended by modifying the model. For example, the framework can be utilized for bid price optimization in forms other than sponsored search advertising and also for using prior knowledge, such as relationships among metrics. #### 4.2 Exploration Subroutine In this subroutine, functions $\hat{c}_i^t(b)$ and $\hat{u}_i^t(b)$ are determined from the predicted distribution of conversions and advertising cost for each bid price candidate. We use bandit algorithms adapted to the setting of this study. The bandit problem collectively refers to the problem of repeatedly selecting one of several candidates whose expected reward is unknown, with the goal of maximizing the cumulative reward. Equation (1) can be regarded as a problem of maximizing the sum of the cumulative rewards of N bandit problems with an overall budget constraint, which is basically a variant of a combinatorial semi-bandit problem [19]. In a bandit problem, a tradeoff called the exploration-exploitation dilemma arises: if the optimal point among the data obtained so far continues to be selected, the globally optimal solution may not be reached, and if a point with a small amount of data and high uncertainty continues to be selected, the cumulative reward will be reduced. Bandit algorithms such as UCB [31] and Thompson sampling [32] create a balance between exploration and exploitation by assuming a distribution of rewards and making selections based on its mean and variance. We propose two algorithms to determine the function value of the conversion function $\hat{u}_i$ , which corresponds to the reward in the bandit problem. The first algorithm, Bayesian AdComB Percentile (Bayesian AdComB-PT), uses the qth percentile of the distribution, while the second algorithm, Bayesian AdComB Thompson sampling (Bayesian AdComB-TS), uses randomly sampled values from the distribution (q is a hyperparameter). Function $\hat{u}_i$ is determined by Eq. (8) for Bayesian AdComB-PT and Eq. (9) for Bayesian AdComB-TS. Note that $\lceil \mathcal{D} \rceil^q$ represents the qth percentile of the distribution $\mathcal{D}$ , and $\mathcal{M}_i(u_i(b))$ represents the distribution at bid price b of the conversion function predicted by the model $\mathcal{M}_i$ . $$\hat{u}_i^{\text{PT}}(b) = \left[ \mathcal{M}_i[u_i(b)] \right]^q, \tag{8}$$ <span id="page-13-1"></span><span id="page-13-0"></span> $$\hat{u}_i^{\text{TS}}(b) \sim \mathcal{M}_i[u_i(b)]. \tag{9}$$ To reduce the risk of violating the budget constraint in the aforementioned uncertain environment, we adopt the 60th percentile value as the advertising cost function, that is, $\hat{c}_i(b) = \lceil \mathcal{M}_i[c_i(b)] \rceil^{60}$ . Since this number is a parameter, we can control how strictly the budget constraint is adhered to by changing it. For example, we could decrease the risk of running out of budget by making this number larger at only the end of the month. #### <span id="page-13-3"></span>4.3 Optimize Subroutine In the optimization subroutine (line 8 of Algorithm 1), optimization is performed using the function determined in the exploration subroutine. The functions $c_i(b)$ , $u_i(b)$ used in optimization problem (1), which is the formulation of the setting in this paper, cannot make any assumptions about the function shape (e.g., convexity), and it is not easy to obtain globally optimal solutions using continuous optimization methods. Therefore, we solve optimization problem (10) with discretized bid prices. Note that $\mathcal{B}$ denotes the set of possible bid price candidates. The globally optimal solution of this problem is expected to be close to the globally optimal solution of the original problem (1). <span id="page-13-2"></span> $$\max_{b_i^t} \sum_{t=1}^T \sum_{i=1}^N u_i(b_i^t)$$ subject to $$\sum_{t=1}^T \sum_{i=1}^N c_i(b_i^t) \le B,$$ $$b_i^t \in \mathcal{B} \quad \forall i \in [N], \forall t \in [T].$$ $$(10)$$ Since the proposed method is an online optimization method in which prediction and optimization are performed sequentially, we consider optimization in the tth round. Let $\hat{c}_i^t(b)$ , $\hat{u}_i^t(b)$ be the functions of ad cost and number of conversions obtained by the update and selection subroutines at the tth round. Since the budget B is the sum of all rounds, it is necessary to set the budget per round for optimization. The opportunity loss can be serious if an ad has display difficulties for a certain period of time. Therefore, for balance, it is logical to set the budget amount for the day of optimization to the remaining budget B divided by the number of days remaining in the month. The optimization problem for the tth round is formulated as $$\max_{b_i^t} \sum_{i=1}^{N} \hat{u}_i^t(b_i^t)$$ subject to $$\sum_{i=1}^{N} \hat{c}_i^t(b_i^t) \le \frac{\bar{B}}{T - t + 1},$$ $$b_i^t \in \mathcal{B} \quad \forall i \in [N].$$ (11) Furthermore, using the variable $z_i^j$ , which takes a value of 1 only if $b_i^t = b_j$ (that is, the bid price of the *i*th keyword is the *j*th element of $\mathcal{B}$ , and 0 otherwise), the problem can be transformed as in optimization problem (12): <span id="page-14-1"></span> $$\max_{z_{i}^{j}} \sum_{i=1}^{N} \sum_{j=1}^{|\mathcal{B}|} \hat{u}_{i}^{j} z_{i}^{j}$$ $$\text{subject to} \sum_{i=1}^{N} \sum_{j=1}^{|\mathcal{B}|} \hat{c}_{i}^{j} z_{i}^{j} \leq \frac{\bar{B}}{T - t + 1},$$ $$\sum_{j=1}^{|\mathcal{B}|} z_{i}^{j} = 1 \quad \forall i = [N],$$ $$z_{i}^{j} \in \{0, 1\} \quad \forall i \in [N], \forall j \in [|\mathcal{B}|].$$ $$(12)$$ Note that we define the constants $\hat{u}_i^j$ , $\hat{c}_i^j$ as $\hat{u}_i^j := \hat{u}_i^t(b_j)$ , $\hat{c}_i^j := \hat{c}_i^t(b_j)$ . Equation (12) is an integer programming problem, and we use Gurobi optimization [33], a general-purpose integer programming solver, for this optimization. Gurobi optimization utilizes the branch-and-cut method to obtain fast exact solutions. In our setting, even with N = 1000 and $|\mathcal{B}| = 1000$ , the solution is completed within 40 s. ## <span id="page-14-0"></span>5 Numerical Experiments This section describes the numerical experiments we conducted to evaluate the effectiveness of the proposed method. #### <span id="page-14-2"></span>5.1 Setup We built two simulators for the numerical experiments: a sponsored search simulator and an iPinYou simulator. The sponsored search simulator was created on the basis of analysis of the real log data of sponsored search advertising. As in actual ad operations, when we input bid prices for each keyword into this simulator, it outputs ad impressions, clicks, conversions, and ad costs for each keyword. We used ad log data from negocia, Inc., a Japanese company that provides an automated Internet advertising management system. The iPinYou simulator is a version of the iPinYou dataset [3] modified into a form that can be used in our setting. It was originally used in a competition organized by iPinYou, a Chinese advertising company. The dataset consists of log data from multiple advertisers' display ads and includes winning bid prices from auctions, which are generally private, allowing a simulator to be built. On the other hand, the data came from display ads, not sponsored search ads, and there were multiple differences, so the simulator was constructed by preprocessing the dataset. First, since there are no keywords in the iPinYou dataset, we split the logs of one advertiser and considered each of them as a keyword and then used the logs of multiple advertisers to replicate the setup where there are multiple keywords in one campaign. Next, we changed our objective from conversion maximization to click maximization and modified our proposed methodology and baseline algorithm accordingly. This is because the dataset incurs advertising costs for impressions, and there are very few conversions logged (some advertisers do not have any conversions). As probabilistic models for the update subroutine of the proposed method in the iPinYou simulator, we considered four likelihood functions and two prior distributions. The four likelihood functions are likelihood function 1', expressed by Fig. 7 and Eq. (13); likelihood function 2', expressed by Fig. 8 and Eq. (14); likelihood function 3', expressed by Fig. 9 and Eq. (15); and likelihood function 4', expressed by Fig. 10 and Eq. (16). <span id="page-15-0"></span> $$volume_{i} \sim \mathcal{N}\left(\mu_{i}^{\text{vol}}, \sigma_{i}^{\text{vol}^{2}}\right) \\ \operatorname{imp}_{i} \sim \mathcal{N}\left(\frac{b_{i}^{2}}{b_{i}^{2} + c_{i}^{2}} \cdot \operatorname{volume}_{i}, \sigma_{i}^{\operatorname{imp}^{2}}\right) \\ \operatorname{click}_{i} \sim \operatorname{Binomial}\left(\operatorname{imp}_{i}, \operatorname{CTR}_{i}\right) \\ \operatorname{cost}_{i} \sim \mathcal{N}\left(\alpha_{i} \cdot b_{i} \cdot \operatorname{imp}_{i}, \sigma_{i}^{\operatorname{cost}^{2}}\right). \\ \end{cases} (13)$$ <span id="page-15-1"></span> $$\operatorname{imp}_{i} \sim \mathcal{N}\left(a_{3i}b_{i}^{3} + a_{2i}b_{i}^{2} + a_{1i}b_{i} + a_{0i}, \sigma_{i}^{\operatorname{imp}^{2}}\right)$$ $$\operatorname{click}_{i} \sim \operatorname{Binomial}\left(\operatorname{imp}_{i}, \operatorname{CTR}_{i}\right)$$ $$\operatorname{cost}_{i} \sim \mathcal{N}\left(\alpha_{i} \cdot b_{i} \cdot \operatorname{imp}_{i}, \sigma_{i}^{\operatorname{cost}^{2}}\right).$$ (14) <span id="page-15-2"></span> $$volume_{i} \sim \mathcal{N}\left(\mu_{i}^{vol}, \sigma_{i}^{vol^{2}}\right)$$ $$imp_{i} \sim \mathcal{N}\left(\frac{b_{i}^{2}}{b_{i}^{2} + c_{i}^{2}} \cdot volume_{i}, \sigma_{i}^{imp^{2}}\right)$$ $$click_{i} \sim Binomial\left(imp_{i}, CTR_{i}\right)$$ $$cost_{i} \sim \mathcal{N}\left((\alpha_{i} \cdot b_{i} + \beta_{i}) \cdot b_{i} \cdot imp_{i}, \sigma_{i}^{cost^{2}}\right).$$ (15)  <span id="page-16-0"></span>Fig. 7 Bayesian network with likelihood function 1' <span id="page-16-2"></span> $$\operatorname{imp}_{i} \sim \mathcal{N}\left(a_{3i}b_{i}^{3} + a_{2i}b_{i}^{2} + a_{1i}b_{i} + a_{0i}, \sigma_{i}^{\operatorname{imp}^{2}}\right) \operatorname{click}_{i} \sim \operatorname{Binomial}\left(\operatorname{imp}_{i}, \operatorname{CTR}_{i}\right) \operatorname{cost}_{i} \sim \mathcal{N}\left(\left(\alpha_{i} \cdot b_{i} + \beta_{i}\right) \cdot b_{i} \cdot \operatorname{imp}_{i}, \sigma_{i}^{\operatorname{cost}^{2}}\right).$$ (16) Common to all likelihood functions is the process of generating the number of clicks on keywords, which is the same as in the case of sponsored search advertisements discussed in Section 4.1. The characteristics of each likelihood function are summarized in Table 2. The same formulation as in Section 4.1 was used for the process of generating the number of impressions. For the ad cost generation process, we focused on the ad cost per impression, since the ad cost is charged by impression. In particular, likelihood functions 3' and 4' are assumed to be quadratic functions of the bid price. This is based on our analysis of the iPinYou data and our finding that ad cost per impression divided by bid price can be approximated as a linear function of bid price.  <span id="page-16-1"></span>Fig. 8 Bayesian network with likelihood function 2'  <span id="page-17-0"></span>Fig. 9 Bayesian network with likelihood function 3' The two prior distributions considered in this paper are prior distribution A', expressed by Eq. (17), and prior distribution B', expressed by Eq. (18). These distributions were designed with the same intention as in Section 4.1. <span id="page-17-1"></span> $$\mu_{i}^{\text{vol}} = |\mathcal{N}(0, 10^{6})|$$ $$\sigma_{i}^{\text{vol}} = |\mathcal{N}(0, 10^{6})|$$ $$\sigma_{i}^{\text{imp}} = |\mathcal{N}(0, 10^{6})|$$ $$c_{i} = |\mathcal{N}(0, 10^{6})|$$ $$a_{0i} = \mathcal{N}(0, 10^{6})$$ $$a_{1i} = \mathcal{N}(0, 10^{6})$$ $$a_{2i} = \mathcal{N}(0, 10^{6})$$ $$a_{3i} = \mathcal{N}(0, 10^{6})$$ $$\text{CTR}_{i} = \text{Beta}(1, 1)$$ $$\alpha_{i} = \mathcal{N}(0, 10^{6})$$ $$\beta_{i} = \mathcal{N}(0, 10^{6})$$ $$\sigma_{i}^{\text{coost}} = |\mathcal{N}(0, 10^{6})|.$$ $$\mu_i^{\text{vol}} = \left| \mathcal{N} \left( \tilde{\mu}_1, (\tilde{\mu}_1/C)^2 \right) \right|$$ $$\sigma_i^{\text{vol}} = \left| \mathcal{N} \left( \tilde{\mu}_2, (\tilde{\mu}_2/C)^2 \right) \right|$$ $$\sigma_i^{\text{imp}} = \left| \mathcal{N} \left( \tilde{\mu}_3, (\tilde{\mu}_3/C)^2 \right) \right|$$ $$c_i = \left| \mathcal{N} \left( \tilde{\mu}_4, (\tilde{\mu}_4/C)^2 \right) \right|$$  <span id="page-18-0"></span>Fig. 10 Bayesian network with likelihood function 4' <span id="page-18-2"></span> $$a_{0i} = \mathcal{N}(0, 10^{6})$$ $$a_{1i} = \mathcal{N}(0, 10^{6})$$ $$a_{2i} = \mathcal{N}(0, 10^{6})$$ $$a_{3i} = \mathcal{N}(0, 10^{6})$$ $$CTR_{i} = Beta(\tilde{\alpha}_{1}, \tilde{\beta}_{1})$$ $$\alpha_{i} = \mathcal{N}(0, 10^{6})$$ $$\beta = \mathcal{N}(0, 10^{6})$$ $$\sigma_{i}^{cost} = \left| \mathcal{N} \left( \tilde{\mu}_{5}, (\tilde{\mu}_{5}/C)^{2} \right) \right|.$$ (18) We set the parameters of the simulation for an actual ad operation environment. The parameters included simulator type, total number of rounds T, number of keywords N, number of bid price candidates $|\mathcal{B}|$ , budget B, and number of rounds of accumulated $\log T'$ . We conducted several experiments in which these settings were varied. The parameters of the experiment with the sponsored search simulator are shown in Table 3 and those with the iPinYou simulator in Table 4. Budget B is expressed as a ratio of the ad cost when the bid price for all keywords is set to the all-round maximum. For the accumulated logs, bid prices were determined by a random algorithm, and the logs were the same for all algorithms. For simulations when the accumulated logs are from an algorithm other than Random, please refer to subsection 5.3.5. <span id="page-18-1"></span>Table 2 Characteristics of each likelihood function | Likelihood function | Impression | Cost per impression | |---------------------|-----------------------------|---------------------------------| | 1 | Consider search volume | Constant multiple of bid price | | 2 | Cubic function of bid price | Constant multiple of bid price | | 3 | Consider search volume | Quadratic function of bid price | | 4 | Cubic function of bid price | Quadratic function of bid price | <span id="page-19-0"></span>**Table 3** Parameters of the experiment with the sponsored search simulator | Setting | T | N | $ \mathcal{B} $ | В | T' | |-----------|----|------|-----------------|-----|----| | Setting 1 | 30 | 100 | 20 | 1/3 | 30 | | Setting 2 | 30 | 1000 | 20 | 1/3 | 30 | | Setting 3 | 30 | 100 | 200 | 1/3 | 30 | | Setting 4 | 30 | 100 | 20 | 1/6 | 30 | | Setting 5 | 60 | 100 | 20 | 1/3 | 30 | | Setting 6 | 30 | 100 | 20 | 1/3 | 1 | As an evaluation metric for the experiment, we utilize the total number of conversions on the simulator in the case of the Sponsored Search simulator and the total number of clicks on the simulator in the case of the iPinYou simulator. We ran the experiment five times with different random states for all settings and averaged the results. Our method was implemented entirely in Python, and the Bayesian modeling package NumPyro [34] was used for Bayesian inference. #### 5.2 Algorithms We compared the following nine algorithms in our experiments. - Random is an algorithm that randomly selects bid prices. - **Greedy** is an algorithm that solves an optimization problem using previous log data to determine bid prices. In this algorithm, only bid prices that have been previously selected are used as candidates for optimization. In other words, optimization problem (12) is optimized while excluding bid prices that have never been selected from the variables of the optimization problem. As $\hat{u}_i^j$ , $\hat{c}_i^j$ of the bid prices that have been selected so far, we used the average number of conversions and ad costs in the log data. - $\epsilon$ -greedy is an algorithm that selects a random bid price with probability $\epsilon$ and solves the optimization problem with probability $1-\epsilon$ using log data so far as well as Greedy to determine the bid price. The algorithm performs the exploitation with probability $1-\epsilon$ and the exploration with probability $\epsilon$ . We adopted $\epsilon=0.1$ in our experiment. - **k-NN** is an optimization method that predicts the number of conversions and ad costs for each bid price candidate using the k-nearest neighbor method [35]. The <span id="page-19-1"></span>**Table 4** Parameters of the experiment with the iPinYou simulator | Setting | T | N | $ \mathcal{B} $ | В | T' | |-----------|----|-----|-----------------|-----|----| | Setting A | 30 | 94 | 20 | 2/3 | 12 | | Setting B | 30 | 94 | 20 | 2/3 | 54 | | Setting C | 30 | 175 | 20 | 2/3 | 12 | | Setting D | 30 | 175 | 20 | 2/3 | 54 | | Setting E | 30 | 71 | 20 | 2/3 | 30 | <span id="page-20-0"></span>**Table 5** WAIC in log data for setting 1 | | Function 1 | Function 2 | Function 3 | Function 4 | |----------------------|------------|------------|------------|------------| | Prior distribution A | 6.29 | 6.37 | 6.11 | 6.17 | | Prior distribution B | 6.29 | 6.36 | 6.07 | 6.14 | optimization procedure is the same as the optimization subroutine in Section [4.3.](#page-13-3) We set hyperparameter *k* (the number of neighborhoods to be utilized) to *k* = 10 in our experiments. In addition, k-NN randomly selects bid prices if the number of data so far is less than *k*. - **AdComB-UCB** and **AdComB-TS** are modifications of the algorithms proposed by Nuara et al. [\[17\]](#page-30-10). These algorithms, like the proposed method, consist of three subroutines: update subroutine, exploration subroutine, and optimization subroutine. In the update subroutine, the distribution of conversions and ad costs are estimated by a Gaussian process instead of Bayesian estimation, and an RBF kernel is used as the kernel. In the selection subroutine, the mean and variance obtained from the Gaussian process are used to select the function, and the function used for optimization is determined by UCB for AdComB-UCB and by Thompson sampling for AdComB-TS. In this paper, we modified the formulation and algorithm because, unlike in [\[17](#page-30-10)], the daily budget for each bidding target cannot be set. Although [\[17](#page-30-10)] estimates the number of clicks and click value (equivalent to conversion rate in our setting) by a Gaussian process in the update subroutine, and optimization is performed using dynamic programming in the optimization subroutine, AdComB-UCB and AdComB-TS estimate the number of conversions and ad costs by a Gaussian process in the update subroutine, and optimization is performed in the optimization subroutine using a general-purpose integer programming solver. - **Bayesian AdComB-MEAN** is a modification of our proposed method to take the average in the exploration subroutine. - **Bayesian AdComB-PT** and **Bayesian AdComB-TS** are the algorithms of our proposed method. The same hyperparameters were used for Bayesian AdComB-MEAN, Bayesian AdComB-PT, and Bayesian AdComB-TS. We optimized the variational parameters using Adam [\[36\]](#page-31-4) with a learning rate of 0.001 and 100,000 steps. The number of samples for the latent variable in the exploration subroutine was set to 10,000, the number of samples for ad cost and number of conversions (clicks in the case of the iPinYou simulator) for each bid price to 10,000, and *q* = 70 for Bayesian AdComB-PT. #### **5.3 Results** In this section, we present and discuss the results of two preliminary experiments and three simulations. <span id="page-21-1"></span>**Table 6** WAIC in log data for setting 2 | | Function 1 | Function 2 | Function 3 | Function 4 | |----------------------|------------|------------|------------|------------| | Prior distribution A | 6.27 | 6.37 | 6.07 | 6.17 | | Prior distribution B | 6.26 | 6.35 | 6.04 | 6.19 | ## <span id="page-21-0"></span>**5.3.1 Preliminary Experiment 1: Comparison of Probabilistic Models** In the update subroutine of the proposed method described in Section [4.1,](#page-7-0) the probabilistic model (prior distribution, likelihood function) in the process of generating advertising metrics is selected from several candidates based on the WAIC in the log data, if the log data accumulated so far exists. In Preliminary Experiment 1, the WAIC of each probability model in the log data available in each setting is measured. The Python library arviz [\[37](#page-31-5)] was used to calculate the WAIC. The WAIC for all combinations of likelihood functions and prior distributions in the sponsored search simulator considered in Section [4.1](#page-7-0) are shown in Tables [5,](#page-20-0) [6,](#page-21-1) and [7.](#page-21-2) We use the log data available for setting 1 in Table [5,](#page-20-0) setting 2 in Table [6,](#page-21-1) and setting 3 in Table [7,](#page-21-2) with the best WAIC shown in bold. As the log data for settings 4 and 5 are the same as that for setting 1, and setting 6 has only one round of log data, no experiments were performed using the log data available for those settings. Note that *C* = 3 was utilized as the hyperparameter for prior distribution B. Among the three settings examined in the experiment, likelihood function 3 with prior distribution B had the best WAIC, and likelihood functions 3 and 4 tended to have a better WAIC than likelihood functions 1 and 2. This can be attributed to the high expressiveness of the ad cost generation process. WAIC tended to be better for likelihood function 3 than for likelihood function 4 and for likelihood function 1 than for likelihood function 2. This finding demonstrates the validity of modeling that considers search volume (an advertising metric that is not actually observed) as a latent variable. As for prior distributions, prior distribution B tended to have a better WAIC than prior distribution A for all likelihood functions, presumably because some parameters were determined by maximum likelihood estimation, resulting in a better fit to the data. The WAIC results for all combinations of likelihood functions and prior distributions in the sponsored search simulator considered in Section [5.1](#page-14-2) are listed in Tables [8–](#page-22-0)[12.](#page-24-0) Note that the log data available in settings A–E correspond to Tables [8,](#page-22-0) [9,](#page-22-1) [10,](#page-23-0) [11](#page-23-1) and [12,](#page-24-0) respectively, with the best WAIC shown in bold. <span id="page-21-2"></span>**Table 7** WAIC in log data for setting 3 | | Function 1 | Function 2 | Function 3 | Function 4 | |----------------------|------------|------------|------------|------------| | Prior distribution A | 6.28 | 6.37 | 6.08 | 6.17 | | Prior distribution B | 6.28 | 6.36 | 6.06 | 6.14 | <span id="page-22-0"></span>**Table 8** WAIC in log data for setting A | | Function 1 | Function 2 | Function 3 | Function 4 | |----------------------|------------|------------|------------|------------| | Prior distribution A | 4.93 | 4.92 | 4.97 | 4.91 | | Prior distribution B | 5.03 | 4.65 | 4.88 | 4.80 | The design of the stochastic models in the iPinYou simulator was similar to that of the sponsored search simulator, but WAIC trends for each stochastic model in the sponsored search simulator were similar for all settings of log data, whereas in the iPinYou simulator, WAIC trends for each probability model differed across settings. In terms of the overall trend, as in the case of the sponsored search simulator, the WAIC of likelihood function 3 was better than that of likelihood function 4 , the WAIC of likelihood function 1 was better than that of likelihood function 2 , and the WAIC of prior distribution B was better than that of prior distribution A . However, the opposite trend was observed for the former in setting A and for the latter in some of the likelihood functions in settings A, D, and E. This difference is presumably due to differences in the distribution of advertising metrics across the data. Utilizing the above experimental results as a basis, we use likelihood function 3 with prior distribution B in settings 1–6, likelihood function 4 with prior distribution B in setting A, likelihood function 1 with prior distribution B in setting B, likelihood function 3 with prior distribution B in settings C and D, and likelihood function 3 with prior distribution A in setting E. #### **5.3.2 Preliminary Experiment 2: Computation Time for Optimization** The proposed method formulates the bid price optimization as integer programming problem [\(12\)](#page-14-1) and solves it with a generic integer programming solver. The same formulation is also used to optimize integer programming problems for all comparison methods except Random. Note that in the Greedy and -greedy formulations, the selectable bid prices are limited to those that have been selected before. In Preliminary Experiment 2, we investigate the robustness of integer programming problem [\(12\)](#page-14-1) with respect to size by measuring the computation time of the optimization while changing the parameters that determine the size, namely, the number of keywords *N* and the number of possible bid prices |*B*|. This experiment was conducted using a sponsored search simulator that allows the number of keywords to be easily changed. We fixed *T* = 1, *B* = 1/3 and measured the <span id="page-22-1"></span>**Table 9** WAIC in log data for setting B | | Function 1 | Function 2 | Function 3 | Function 4 | |----------------------|------------|------------|------------|------------| | Prior distribution A | 4.21 | 4.30 | 4.32 | 4.42 | | Prior distribution B | 4.10 | 4.18 | 4.21 | 4.39 | <span id="page-23-0"></span>Table 10 WAIC in log data for setting C | | Function 1' | Function 2' | Function 3' | Function 4' | |-----------------------|-------------|-------------|-------------|-------------| | Prior distribution A' | 4.67 | 4.86 | 4.56 | 4.63 | | Prior distribution B' | 4.65 | 4.83 | 4.49 | 4.62 | time taken to find the optimal solution using a general-purpose integer programming solver for all combinations of $N \in \{10, 50, 100, 1000\}$ , $|\mathcal{B}| \in \{10, 20, 200, 1000\}$ . The estimated number of conversions and ad cost in integer programming problem (12), $\hat{u}_i^j$ , $\hat{c}_i^j$ , was sampled by Eq. (19), where $u_i(b_j)$ , $c_i(b_j)$ are the true number of conversions and ad costs incurred when bidding on keyword i at bid price $b_j$ . Equation (19) indicates that the true values of the number of conversions and ad cost are subject to noise generated from a normal distribution with a standard deviation of 1/3 of the true value. This noise represents the error in the estimation. In the experiment, $\hat{u}_i^j$ , $\hat{c}_i^j$ were sampled five times and optimized for each $\hat{u}_i^j$ , $\hat{c}_i^j$ . <span id="page-23-2"></span> $$\hat{u}_i^j \sim \mathcal{N}\left(u_i(b_j), u_i(b_j)/3\right)$$ $$\hat{c}_i^j \sim \mathcal{N}\left(c_i(b_j), c_i(b_j)/3\right).$$ (19) The results representing the average number of seconds taken to find the optimal solution are shown in Table 13. As we can see, the calculation of the optimization subroutine is fast. In the actual operation of sponsored advertising, the number of keywords handled is several hundred at most, and the number of possible bid price candidates is usually only a few dozen. Furthermore, in the setting of this paper, the bid price optimization algorithm is executed only once a day, so the results in Table 13 are fast enough. #### 5.3.3 Experiment 1: Sponsored Search Simulator The results of the experiments with the six settings of Table 3 using the sponsored search simulator are shown in Table 14. These results represent the % improvement when the total number of conversions in the Random simulation is set to 100 %, with the best number in each setting shown in bold. These results confirm that the proposed method, Bayesian AdComB-PT, performs better than the existing algorithms in all settings. Bayesian AdComB-MEAN, which is a modification of the proposed method to take the average in the exploration subrou- <span id="page-23-1"></span>Table 11 WAIC in log data for setting D | | Function 1' | Function 2' | Function 3' | Function 4' | |-------------------------|-------------|-------------|-------------|-------------| | Prior distribution A' | 4.07 | 4.14 | 4.04 | 4.11 | | Prior distribution $B'$ | 4.32 | 4.07 | 3.98 | 4.01 | <span id="page-24-0"></span>**Table 12** WAIC in log data for setting E | | Function 1 | Function 2 | Function 3 | Function 4 | |----------------------|------------|------------|------------|------------| | Prior distribution A | 5.47 | 5.79 | 4.49 | 5.45 | | Prior distribution B | 5.45 | 5.79 | 4.52 | 5.42 | tine, also outperformed the existing algorithms, which indicates that the framework of the proposed method other than the selection subroutine is also effective. In contrast, Bayesian AdComB-TS, which selects points from a distribution by Thompson sampling, has an unstable performance and performs worse than Bayesian AdComB-MEAN on average. This is possibly because the variance of the distribution estimated by Bayesian inference is large, and the shape of the function determined by the bandit algorithm is far from the actual shape. We should be able to solve this problem by imposing constraints on the sampling of points from the distribution. For the existing methods, Greedy outperformed Random for all settings. This result strengthens the validity of the formulation of optimization problem [\(12\)](#page-14-1), as Greedy can be regarded as using only the optimization subroutine of the proposed method. Greedy also outperformed -greedy for all settings except setting 6. This result suggests that a completely random search leads to a worse cumulative reward, as the search is to some extent improved by the log data. The k-NN, which calculates ad costs and number of conversions for all bid price candidates by using the k-nearest neighbor method and considering the relationship between large and small bids, performed the same optimization as the proposed method, but its performance was comparable to that of Greedy. This is presumably due to the low prediction accuracy of ad costs and conversions when bids are made at bid prices that have never been selected in the log data using the k-nearest neighbor method due to the high uncertainty. While AdComB-UCB performed well for all settings, the performance of AdComB-TS was not stable across settings. This result is similar to that of the proposed Bayesian AdComB method and suggests the possibility of increased variance in performance due to the selection of function values by sampling when utilizing the framework consisting of update subroutines, selection subroutines, and optimization subroutines used by these methods in our problem setting. This suggests the possibility of increased variance. Next, we examine the influence of the simulator hyperparameters. Note that the indices in this experiment are relative, so a precise discussion is difficult. Setting <span id="page-24-1"></span>**Table 13** Computation time of optimization subroutine for each | Table 13<br>Computation time of<br>optimization subroutine for each<br>parameter (s) | | 10 | 50 | 100 | 1000 | |--------------------------------------------------------------------------------------|------|------|------|------|-------| | | 10 | 0.01 | 0.02 | 0.04 | 0.31 | | | 20 | 0.01 | 0.04 | 0.06 | 0.61 | | | 200 | 0.06 | 0.28 | 0.55 | 5.73 | | | 1000 | 0.29 | 1.60 | 3.10 | 37.62 | <span id="page-25-0"></span>**Table 14** Results of Experiment 1 | Algorithm | Setting 1 | Setting 2 | Setting 3 | Setting 4 | Setting 5 | Setting 6 | |----------------------|-----------|-----------|-----------|-----------|-----------|-----------| | Random | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | | Greedy | 23.0 | 21.8 | 20.5 | 57.4 | 22.1 | 2.4 | | -greedy | 21.6 | 20.5 | 19.1 | 49.5 | 21.4 | 10.3 | | k-NN | 22.7 | 21.9 | 20.3 | 57.2 | 22.0 | 16.2 | | AdComB-UCB | 23.2 | 22.4 | 20.5 | 57.2 | 24.1 | 14.4 | | AdComB-TS | 23.1 | 22.5 | 21.3 | 48.1 | 23.8 | 11.3 | | Bayesian AdComB-MEAN | 24.0 | 22.7 | 22.3 | 60.4 | 24.1 | 18.9 | | Bayesian AdComB-PT | 25.1 | 22.9 | 23.2 | 64.1 | 24.4 | 19.4 | | Bayesian AdComB-TS | 23.3 | 23.1 | 21.9 | 61.1 | 24.1 | 14.9 | 2 features an increased total number of keywords, but Bayesian AdComB-TS and AdComB-TS have a higher relative performance among all methods compared to the other settings. This may be due to the fact that the sampling bias is compensated for compared to a smaller total number of keywords. Setting 4 is a setting where the budget is halved, but the improvement from Random for all methods is greater than in the other settings. This is presumably because the methods other than Random take budget constraints into account. In setting 6, where there are fewer rounds in the log data, the performances of Greedy, -greedy, AdComB-UCB, AdComB-TS, and Bayesian AdComB-TS are significantly lower, suggesting that these methods should be used on their own without the log data. It is probably also necessary to increase the number of explorations, such as bidding with a random bid price with a certain probability. ### **5.3.4 Experiment 2: iPinYou Simulator** The results of the experiments with the five settings of Table [4](#page-19-1) using the iPinYou simulator are shown in Table [15.](#page-25-1) These results represent the % improvement when the <span id="page-25-1"></span>**Table 15** Results of Experiment 2 | Algorithm | Setting A | Setting B | Setting C | Setting D | Setting E | |----------------------|-----------|-----------|-----------|-----------|-----------| | Random | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | | Greedy | 4.96 | 3.18 | 6.68 | 5.73 | 5.22 | | -greedy | 4.65 | 3.40 | 5.51 | 6.28 | 4.78 | | k-NN | 6.04 | 3.68 | 6.46 | 5.63 | 5.37 | | AdComB-UCB | 4.94 | 6.71 | 6.64 | 7.35 | 4.45 | | AdComB-TS | 4.36 | 7.47 | 5.92 | 7.54 | 5.11 | | Bayesian AdComB-MEAN | 8.16 | 6.82 | 6.71 | 7.92 | 6.11 | | Bayesian AdComB-PT | 5.35 | 7.16 | 6.79 | 8.01 | 6.51 | | Bayesian AdComB-TS | 5.64 | 5.54 | 6.25 | 7.96 | 6.23 | <span id="page-26-1"></span>**Table 16** Results of Experiment 3 | Algorithm | Setting 1 | Setting 5 | Setting A | Setting C | |----------------------|-----------|-----------|-----------|-----------| | Random | 0.00 | 0.00 | 0.00 | 0.00 | | Greedy | 21.1 | 22.1 | 4.36 | 0.05 | | -greedy | 19.5 | 21.8 | 2.87 | 0.96 | | k-NN | 21.3 | 22.3 | 4.41 | 0.05 | | AdComB-UCB | 21.3 | 22.1 | 3.37 | 5.34 | | AdComB-TS | 16.8 | 21.7 | 3.19 | 5.67 | | Bayesian AdComB-MEAN | 23.1 | 23.8 | 6.76 | 6.30 | | Bayesian AdComB-PT | 24.2 | 24.0 | 7.50 | 6.79 | | Bayesian AdComB-TS | 22.1 | 22.6 | 5.52 | 5.09 | total number of clicks in the Random simulation is set to 100 %, with the best number in each setting shown in bold. For Experiment 2, Bayesian AdComB-PT also showed a good performance, while setting A exhibited a lower performance than Bayesian AdComB-MEAN. A possible cause could be insufficient budget digestion due to overestimating ad costs. The instability of the performance of Bayesian AdComB-TS and AdComB-TS is the same as in Experiment 1 and is presumably due to the large variance of the advertising metric, as in Experiment 1. The reason for the highest performance of AdComB-TS in setting B is also considered to be the same. As a whole, the reason for the smaller improvement % from Random compared to Experiment 1 can be attributed to the irregular noise of the advertising metric. Since the iPinYou simulator is built directly using real data, it is strongly influenced by factors that cannot be observed by advertisers (such as time series [data?] (e.g., day of the week and time) and user attributes), which may make it difficult to approximate the function for the bid price of each advertising metric. Another possible factor is that in the iPinYou simulator, the number of impressions is the only observable intermediate advertising metric before leading to the number of clicks in the objective function. #### <span id="page-26-0"></span>**5.3.5 Experiment 3: Disproportionate Log Data** In this experiment, we examine the performance of each algorithm when the available log data measures are not Random and the bid prices of the log data are biased. Since the bid prices of available log data are rarely random in the case of Internet advertising, the settings used in this experiment are realistic. The experiments were conducted for settings 1 and 5 of the sponsored search simulator and settings A and C of the iPinYou simulator. The log data measures were used for the first five rounds of bidding with Random and for the remaining rounds with k-NN. The results are shown in Table [16.](#page-26-1) These results represent the % improvement when the total number of conversions (clicks for iPinYou simulator) in the Random simulation is set to 100 %, with the best number in each setting shown in bold. The results of the Random simulation do not depend on the log data strategy, so they can be compared with the results of the same settings in Experiments 1 and 2. The performance of each algorithm was lower in settings 1, A, and C than in similar settings in Experiments 1 and 2. This may be due to the fact that the measures in the log data are not Random, and the bid prices in the log data are biased toward specific values, so there is little information on other bid prices. On the other hand, for setting 5, there is little difference between the results of Experiment 1 and the performance of each algorithm. This may be due to the fact that the total number of rounds in setting 5 is 60, which is twice the number of rounds in the other settings, and the bias in the log data has little effect on the overall results. For Experiment 3, the proposed method, Bayesian AdComB-PT, also performed well for all settings. It also showed a smaller performance drop than Bayesian AdComB-MEAN from the results of Experiments 1 and 2. These findings suggest the validity of using a selection subroutine that considers the balance between utilization and search instead of using averages. In setting C, the performances of Greedy, -greedy, and k-NN were noticeably worse than in Experiment 2. The reason may be that the number of rounds of log data was too small to search for bid prices that would result in a large number of clicks. # <span id="page-27-0"></span>**6 Conclusion** In this paper, we proposed an algorithm for bid price optimization at the keyword level for sponsored search advertising. The framework consists of Bayesian inference, a bandit algorithm, and online optimization. The update subroutine uses Bayesian estimation to update the model, which utilizes the keyword bid price as input and predicts the number of conversions, ad cost, and other advertising metrics for the keyword as a distribution. Bayesian estimation is used to make predictions that take into account the high level of uncertainty, which that is a challenge unique to Internet advertising. In the exploration subroutine, a bandit algorithm is used to determine the function to be utilized for optimization. The optimization subroutine uses the function determined in the selection subroutine to perform optimization with a general-purpose integer programming solver. By using the function determined by the bandit algorithm, the bid price optimization is performed while considering how to maximize the cumulative reward. We also constructed two simulators using real data from sponsored search ads and the iPinYou dataset, which is an open dataset. In preliminary experiments, we used log data available in multiple settings of these two simulators to measure the WAIC of the multiple stochastic models considered in this paper and discussed the validity of the stochastic models. We also measured the computation time of the optimization subroutine of the proposed method by changing the size of the optimization problem and confirmed that it is fast enough. Experiments using the sponsored search simulator confirmed the effectiveness of the proposed method, and the performance of each method for each simulator setting was discussed. Experiments using the iPinYou simulator also confirmed the effectiveness of the proposed method, suggesting that it is highly scalable. Experiments with different log data measures in these simulators confirmed the effectiveness of the proposed method in more realistic settings. The first aspect of future prospects for this research is to refine the optimization algorithm of the proposed method. One possible direction for algorithm refinement is the use of boosting machines and global Bayesian optimization theory. Boosting machines can be used to update subroutines. NGBoost [\[38](#page-31-6)] can estimate distributions in the same way as in this paper, treating the parameters of the conditional distribution as targets for a multi-parameter boosting algorithm. Global Bayesian optimization theory could be used to make the update subroutine and the optimization subroutine theoretically consistent. Žilinskas and Calvin [\[39](#page-31-7)] considered a global optimization problem where the objective function was assumed to be a black box and expensive. Their proposed method is not directly applicable to this study as it does not consider the exploration-exploitation dilemma, but we believe it can be applied by using Bayesian. The second is to extend the proposed method to be adaptable to more realistic environments. Factors affecting advertising metrics not considered in this paper include keyword match types and text characteristics, time-series trends, and time differences between when clicks and conversions occur. Features such as keyword match type, text length, and abstraction level affect the click rate and conversion rate of keywords. Ramaboa and Fish [\[40](#page-31-8)] and Yang et al. [\[41](#page-31-9)] asserted that the click and conversion rates tend to be higher for keywords with an exact match type than for keywords with a partial match type. Du et al. [\[22](#page-30-17)] classified keywords into three types (keywords related to a company's services, keywords related to competitors' services, and general keywords with a high level of abstraction), in addition to keyword match type, and investigated the impact on performance (e.g., click rates). The proposed method can be applied by manually classifying keywords based on the advertising groups to which they belong or by automatically classifying them by acquiring distributed representations of words and clustering them and then hierarchizing the probability model so that some latent variables are shared by keywords in the same group. In this paper, we focused on the optimization of bid prices for keywords with a fixed match type, but it is possible to extend the optimization to include the match type and to propose new keywords. As for the time-series trends, these time-series characteristics may arise in the click rate and search volume of advertisements because the attributes of users who visit a site differ depending on the day of the week and the season. Zhang et al.'s [\[42\]](#page-31-10) analysis of the iPinYou dataset, which we also used for the experiments in this paper, showed that there are characteristics of click rates by day of the week and by time of day that are specific to advertisers. A possible application of the proposed method would be to analyze the time-series characteristics from the available log data and reflect the results as latent variables in a probabilistic model. Conversions do not necessarily occur at the same time as clicks—they may occur days or even weeks after the click. Chapelle [\[43](#page-31-11)] proposed a conversion rate prediction method for display advertising that takes into account the time difference until a conversion occurs. Vernade et al. [\[44](#page-31-12)] defined the bandit problem, in which there may be a delay in the timing of getting a reward, and proposed a bandit algorithm to solve it. Although the setting in this paper is one where conversion delays do not occur, we expect that these methods can be extended to the case where conversion delays occur by extending them to the setting in this paper. In addition, in the actual operation of sponsored search advertising, practical constraints are often imposed on the ratio of conversions to ad cost, etc. In this paper, we only considered budget constraints. Yang et al. [\[45](#page-31-13)] addressed the bid price optimization problem for impression-based display advertising, in which a maximum cost-per-click constraint is imposed in addition to the budget constraint. The method proposed in this paper is based on PID control, which is a classical feedback control method. He et al. [\[46](#page-31-14)] proposed a reinforcement learning-based bidding optimization method that can take into account constraints such as the upper bound of the costper-impression and the lower bound of the click rate in addition to the constraints of [\[45](#page-31-13)]. The method proposed in this paper uses a probabilistic model including each advertising metric, which enables estimation of the distribution of advertising metrics other than conversions and ad cost. As such, it is possible to select a function for each advertising metric in a selection subroutine and to consider constraints other than budget constraints in an optimization subroutine. Furthermore, by changing the hyperparameters in the selection subroutine, the priority of each constraint can be considered. By adding these extensions to the proposed method and verifying its effectiveness in a realistic environment rather than in a simulation, we aim to develop a method that will assist advertisers in their advertising operations. **Author Contributions** K.M. drafted the original manuscript and made substantial contributions to the implementation of the work. K.K made significant contributions to the conception and design of the work. K.I. made substantial contributions to the data analysis and interpretation. K.N. revised the draft of the work critically for important intellectual content. All authors have approved the submitted version of the manuscript and agreed to be accountable for any part of the work. **Data Availability** The iPinYou dataset used in this paper can be downloaded from [https://contest.ipinyou.](https://contest.ipinyou.com/) [com/.](https://contest.ipinyou.com/) ## **Declarations** **Competing Interests** The authors declare no competing interests. <span id="page-29-0"></span>**Open Access** This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the mat[erial. If](https://www.insiderintelligence.com/content/tv-ad-spending-2022) mat[erial is not included in the article's Creative Commons licenc](https://www.insiderintelligence.com/content/tv-ad-spending-2022)e and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to o[btain permission directly from the](https://www.iab.com/wp-content/uploads/2022/04/IAB_Internet_Advertising_Revenue_Report_Full_Year_2021.pdf) cop[yright holder. To view a copy of this licence, visit](https://www.iab.com/wp-content/uploads/2022/04/IAB_Internet_Advertising_Revenue_Report_Full_Year_2021.pdf) http://creativecommons.org/licenses/by/4.0/. # <span id="page-29-2"></span><span id="page-29-1"></span>**Re[ferences](https://doi.org/10.1145/2648584.2648590)** - <span id="page-29-4"></span><span id="page-29-3"></span>1. [eMarketer \(2022\) TV Ad spending 2022 - insider intelli](https://advertising.amazon.com/en-us/library/videos/campaign-bidding-sponsored-products)gence trends, forecasts & statistics. https:// www.insiderintelligence.com/content/tv-ad[-spending-2022. Accessed 23 Apr 2023](https://support.google.com/google-ads/answer/6167118) - <span id="page-29-5"></span>2. IAB (2022) Iab internet advertising revenue report full year 2021. https://www.iab.com/wp-content/ uploads/2022/04/IAB\_Internet\_Advertising\_Revenue\_Report\_Full\_Year\_2021.p[df. Accessed 23 Apr](https://localiq.com/blog/search-advertising-benchmarks/) [2023](https://localiq.com/blog/search-advertising-benchmarks/) - <span id="page-30-0"></span>3. Liao H, Peng L, Liu Z et al (2014) iPinYou global RTB bidding algorithm competition dataset. Proceedings of the 8th International Workshop on Data Mining for Online Adv[ertising. pp 1–6.](https://doi.org/10.1145/3219166.3219208) https:// [doi.org/10.1145/26](https://doi.org/10.1145/3219166.3219208)48584.2648590 - <span id="page-30-3"></span>4. Amazon Ads (2023) How does bidding work with amazon ads? https://advertising.amazon.com/enus/library/videos/campaign-bidding-sponsored-products. Accessed 23 Apr 2023 - <span id="page-30-4"></span>5. Google Ads (2023) About quality score. https://support.google.com/google-ads/answer/6167118. Accessed 23 April 2023 - <span id="page-30-5"></span>6. LocaliQ (2022) Search advertising benchmarks for every industry [2022 data]. https://localiq.com/ blog/search-advertising-benchmarks/. Accessed 23 Apr 2023 - <span id="page-30-1"></span>7. Feng Z, Podimata C, Syrgkanis [V \(2018\) Learning to bid without knowing](https://doi.org/10.1145/2339530.2339716) your value. Proceedings of the 2018 ACM Conference on Economics and Computation. pp 505–522. https://doi.org/10.1145/ 3219166.3219208 - <span id="page-30-2"></span>8. Abhishek V, Hosanagar K (2013) Optimal bidding i[n multi-item multislot sponsored search au](https://doi.org/10.1145/3357292.3357307)ctions. Oper Res 61(4):855–873 - 9. Thomaidou S, Liakopoulos K, Vazirgiannis M (2014) Toward an integrated framework for automated development and optimization of online advertising campaigns. Intell Data Anal 18(6):1199–1227 - <span id="page-30-6"></span>10. Zhang W, Zhang Y, Gao B et al (2012) Joint optimization of bid and budget allocation in sponsored search. Proceedings [of the 18th ACM SIGKDD International](https://doi.org/10.1145/1134707.1134736) Conference on Knowledge Discovery and Data Mining. pp 1177–1185. https://doi.org/10.1145/2339530.2339716 - <span id="page-30-8"></span><span id="page-30-7"></span>11. Li H, Lei Y, Yang Y (2019) Bidding strategies on Adgroup and keyword levels in search engine advertising: a comparison study. Proceedings of the 2019 2nd International Conference on Information Management and Management Sciences. pp 23–27. https://doi.org/10.1145/3357292.3357307 - <span id="page-30-9"></span>12. Auer P, Cesa-Bianchi N, Freund Y et al (2002) The nonstochastic multiarmed bandit problem. SIAM J Comput 32(1):48–77 - <span id="page-30-10"></span>13. Rusmevichientong P, Williamson DP (2006) An adaptive algorithm for selecting profitable keywords for search-based advertising services. Proceedings of the 7th ACM Conference on Electronic Commerce. pp 260–269. https://doi.org/10.1145/1134707.1134736 - <span id="page-30-12"></span><span id="page-30-11"></span>14. Symitsi E, Markellos RN, Mantrala MK (2022) Keyword portfolio optimization in paid search advertising. Eur J Oper Res 303(2):767–778 - 15. Yang Y, Zhang J, Qin [R et al \(2012\) Budget strategy in uncertain enviro](https://proceedings.mlr.press/v28/chen13a.html)nments of search auctions: a preliminary investigation. IEEE Trans Serv Comput 6(2):168–176 - <span id="page-30-13"></span>16. Avadhanula V, Colini Baldeschi R, Leonardi S et al (2021) Stochastic bandits for multi-platform budget optimization in online advertising. Proceedings of [the Web Conference 2021:2805–2817](https://dl.acm.org/doi/10.5555/3104322.3104451) - <span id="page-30-14"></span>17. Nuara A, Trovò F, Gatti N et al (2022) Online joint bid/daily budget optimization of internet advertising campaigns. Artif Intell 305:103663 - <span id="page-30-17"></span>18. Badanidiyuru A, Kleinberg R, Slivkins A (2018) Bandits with knapsacks. J ACM 65(3):1–55 - <span id="page-30-18"></span>19. Chen W, Wang Y, Yuan Y (2013) Combinatorial multi-armed bandit: general framework and applications. Proceedings of the 30th International Conference on International Conference on Machine Learning. pp 151–159. https://proceedings.mlr.press/v28/chen13a.html - <span id="page-30-16"></span>20. Srinivas N, Krause A, Kakade S et al (2010) Gaussian process optimization in the bandit setting: no regret and experimental design. Proceedings of the 27th International Conference on International Conference on Machine Learning. pp 1015–1022. https://dl.acm.org/doi/10.5555/3104322.3104451 - <span id="page-30-19"></span><span id="page-30-15"></span>21. Agarwal A, Hosanagar K, Smith MD (2011) Location, location, location: an analysis of profitability of position in online advertising markets. J Mark Res 48(6):1057–1073 - <span id="page-30-20"></span>22. Du X, Su M, Zhang X et al (2017) Bidding for multiple keywords in sponsored search advertising: keyword categories and match types. Inf Syst Res 28(4):711–722 - 23. Ghose A, Yang S (2009) An empirical analysis of search engine advertising: sponsored search in electronic markets. Manage Sci 55(10):1605–1622 - <span id="page-30-21"></span>24. Hou L (2015) A hierarchical Bayesian network-based approach to keyword auction. IEEE Trans Eng Manage 62([2\):217–225](https://doi.org/10.1145/2623330.2623633) - <span id="page-30-22"></span>25. Yang H, Ormandi R, Tsao HY et al (2016) Estimating rates of rare events through a multidimensional dynamic hierarchical Bayesian framework. Appl Stoch Model Bus Ind 32(3):340–353 - <span id="page-30-23"></span>26. Yang S, Ghose A (2010) Analyzing the relationship between organic and sponsored search advertising: positive, negative, or zero interdependence? Mark Sci 29(4):602–623 - <span id="page-30-24"></span>27. Watanabe S, Opper M (2010) Asymptotic equivalence of Bayes cross validation and widely applicable information criterion in singular learning theory. J Mach Learn Res 11(12):3571–3594 - <span id="page-31-0"></span>28. Zhang W, Yuan S, Wang J (2014) Optimal real-time bidding for display advertising. Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and D[ata Mining. pp](https://papers.nips.cc/paper_files/paper/2011/hash/e53a0a2978c28872a4505bdb51db06dc-Abstract.html) 1077–1086. [https://doi.org/10.1145/2623330.2623633](https://papers.nips.cc/paper_files/paper/2011/hash/e53a0a2978c28872a4505bdb51db06dc-Abstract.html) - <span id="page-31-1"></span>29. Hoffman MD, Blei DM, Wang C et al (2013) Stochastic variational infe[rence. J Mach Learn Res](https://www.gurobi.com) 14(1):1303–1347 - <span id="page-31-2"></span>30. Metropolis N, Rosenbluth AW, Rosenbluth MN et al (1953) Equation of state calculations by fast computing machines. J Chem Phys 2[1\(6\):1087–1092](http://arxiv.org/abs/1912.11554) - <span id="page-31-3"></span>31. Auer P, Cesa-Bianchi N, Fischer P (2002) Finite-time analysis of the multiarmed bandit problem. Mach Learn 47(2):235–256 - <span id="page-31-4"></span>32. Chapelle O, Li L (2011) An empirical evaluation of Thompson sampling. Proceedings of the 24th International Conference on Neural Informatio[n Processing Systems. pp 2249–2257.](https://doi.org/10.48550/arXiv.1412.6980) https://papers. nips.cc/paper\_files/paper/2011/hash/e53a0a2978c28872a4505bdb51db06dc-Abstract.html - <span id="page-31-6"></span><span id="page-31-5"></span>33. Gurobi Optimization, LLC (2022) Gurobi optimizer reference manual. https://www.gurobi.com. Accessed 23 Apr 2023 - <span id="page-31-7"></span>34. Phan D, Pradhan N, Jankowiak M (2019) Composable effects for flexible and accelerated probabilistic programming in numpyro. Preprint at http://arxiv.org/abs/1912.11554 - <span id="page-31-8"></span>35. Fix E, Hodges JL (1989) Discriminatory analysis. nonparametric discrimination: consistency properties. International Statistical Review/Revue Internationale de Statistique 57(3):238–247 - <span id="page-31-9"></span>36. Kingma DP, Ba J (2014) Adam: a method for stochastic optimization. Proceedings of the 3rd International Conference on Learning Representations. https://doi.org/10.48550/arXiv.1412.6980 - <span id="page-31-10"></span>37. Kumar R, Carroll C, Hartikainen A et al (2019) Arviz a unified library for exploratory analysis of Bayesian models in python. J Open Source Softw 4(33):1143 - <span id="page-31-11"></span>38. D[uan T, Anand A, Di](http://arxiv.org/abs/1407.7073)ng DY et al (2020) NGBoost: natural gradient boosting for probabilistic prediction. International Conference on Machine Learning. PMLR, pp 2690–2700 - 39. Žilinskas A, Calvin J (2019) Bi-objective decision making in global optimization based on st[atistical](https://doi.org/10.1145/2623330.2623634) [models. J Global Optim 74:599–60](https://doi.org/10.1145/2623330.2623634)9 - <span id="page-31-12"></span>40. Yang S, Pancras J, Song YA (2021) Broad or exact? Search ad matching decisions with keyword specificity and position. Decis Support Syst 143:113491 - <span id="page-31-13"></span>41. Ramaboa KK, Fish P (2018) Keyword length and matching options as indicators of search intent in sponsored search. Inf Process Manage 54(2):175–183 - 42. Zhang W, Yuan S, Wan[g J et al \(2014\) Real-time bidding benchmark](https://doi.org/10.1145/3292500.3330681)ing with iPinYou dataset. Preprint at arXiv:1407.7073 - <span id="page-31-14"></span>43. Chapelle O (2014) Modeling delayed feedback in display advertising. Proceedings of the 20th ACM SIGKDD International [Conference on Knowledge Discovery and D](https://doi.org/10.1145/3447548.3467199)ata Mining. pp 1097–1105. https:// doi.org/10.1145/2623330.2623634 - 44. Vernade C, Cappé O, Perchet V (2017) Stochastic bandit models for delayed conversions. Proceedings of the 33rd Conference on Uncertainty in Artificial Intelligence. https://hal.science/hal-01545667 - 45. Yang X, Li Y, Wang H et al (2019) Bid optimization by multivariable control in display advertising. Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. pp 1966–1974. https://doi.org/10.1145/3292500.3330681 - 46. He Y, Chen X, Wu D et al (2021) A unified solution to constrained bidding in online display advertising. Proceedings of the 27th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. pp 2993–3001. https://doi.org/10.1145/3447548.3467199