Reacting To Variations In Product Demand An Application For Conversion Rate Cr Prediction In Sponsored Search
ABSTRACT
Section titled “ABSTRACT”In online internet advertising, machine learning models are widely used to compute the likelihood of a user engaging with product related advertisements. However, the performance of traditional machine learning models is often impacted due to variations in user and advertiser behavior. For example, search engine traffic for florists usually tends to peak around Valentine’s day, Mother’s day, etc. To overcome, this challenge, in this manuscript we propose three models which are able to incorporate the effects arising due to variations in product demand. The proposed models are a combination of product demand features, specialized data sampling methodologies and ensemble techniques. We demonstrate the performance of our proposed models on datasets obtained from a real-world setting. Our results show that the proposed models more accurately predict the outcome of users interactions with product related advertisements while simultaneously being robust to fluctuations in user and advertiser behaviors.
KEYWORDS
Section titled “KEYWORDS”Search based advertising; machine learning; conversion prediction. Computing methodologies → Supervised learning by regression; Learning linear models; • Applied computing → Online shopping
1 INTRODUCTION
Section titled “1 INTRODUCTION”Digital advertising can be performed in multiple forms i.e. contextual advertising, display based advertising and search-based advertising [19]. In this manuscript we are interested in the promotion of products through a search-based advertising service. Search based advertising has been of great interest considering the numbers of products sold worth million of dollars in a year [10]. In such advertising, textual/image based advertisements are placed next to their search results and performance is evaluated with a cost-per-click (CPC) billing, which implies that the search engine is paid every time the advertisement is clicked by a user. The search engine typically matches products which are close to the intent of the user (as expressed by the search query) and select products which have the highest bid.
From an advertisers standpoint, an effective advertisement bidding strategy requires determining the probability that an advertisement click will originate a conversion. Conversion can be defined as either a sale of the product or some corresponding action (i.e. filling of forms or watching a video). Development of effective advertisement bidding strategies require sophisticated machine learning models to compute the likelihood of a user engaging with product related advertisements. Such machine learning models are typically developed using features drawn from a variety of sources: product information consisting of product categories, type, price, age, gender, prior user information including whether a user is new customer vs returning customer, and attributes of the search request including day, time and client device type.
Typically, Generalized Linear Models (GLMs) [12] are widely used to model conversion prediction tasks for multiple reasons: (1) Predictions for billions of search products are made on a daily basis and hence the inference or the likelihood of the user engagement for any product needs to be computed within a fraction of a second (2) GLMs facilitate a quick update of the model parameters as newer data is available. (3) Extreme sparsity of the data i.e. minute fraction of nonzero feature values per data point.
However, traditional GLMs are often limited in their ability to model variations in product demand, originating either due to user buying behavior or advertiser selling behavior (sales). Example of such variations in product demand include : Increase in demand for online florists around Valentine’s day, Mother’s day, etc., the introduction of a new product into the market (e.g., a new iphone model) or even a competitor that decided to lower some prices.
The problem becomes relevant when there is a surge in product demands as advertisers miss opportunities because the machine learning models often under-predict user engagement levels with respect to product advertisements. Similarly, when there is a drop in product demand, advertisers overspend because the models overpredict user responses to product advertisements. This usually stems from the fact that traditional machine learning models are slow to incorporate the sudden variations arising due to increase in user buying behavior or advertiser selling behavior. Such biased models in turn lead to significant revenue loss.
To overcome the challenges associated with variations in product demand, in this manuscript, we propose three novel approaches: Firstly, we extend the baseline model by adding novel features which capture variations in product demand. Secondly, we propose models in conjunction with importance weighting [18], wherein data from the recent past is weighted more as compared to data from the distant past during model training, and lastly we propose mixture models i.e. models consisting of our original model along with a model trained on more recent data. We then demonstrate the superior performance of our proposed models w.r.t the baseline model in a real world setting.
2 RELATED WORK
Section titled “2 RELATED WORK”Several interesting machine learning research have been performed in the domain of contextual advertising, sponsored search advertising [6] and display advertising [3, 13]. Current state-of-the-art conversion rate (CR) prediction methods range from logistic regression [3], to log-linear models [1] and to a combination of log-linear models with decision trees [7]. More complex modeling techniques such as deep learning, ensemble methods and factorization machines have also been widely used for such tasks.
Within the realm of deep learning, Zhang et al. [20] modeled the dependency on user’s sequential behaviors into the click prediction process through Recurrent Neural Networks (RNN). They further concluded that using deep learning techniques led to significant improvement in the click prediction accuracy. On similar lines, Jiang et al. [8] proposed deep architecture model that integrates deep belief networks (DBN) with logistical regression to deal with the problem of CTR prediction for contextual advertising. In their work, they used DBN to generate non-linear embeddings from original data (users’ information, click logs, product information and pages information) and then they used these embeddings as features into a regression model for CTR prediction problems.
Ensemble models have also been widely used for CTR prediction problems. In particular, He et al. [7] proposed a model which combines decision trees with logistic regression and observed that the joint model outperforms either of these methods thereby leading to a significant impact to the overall system performance. They concluded that the superior performance was a result of utilizing the right features i.e. those capturing historical information about the user or the advertisement. Juan et al. [9] proposed Field aware Factorization Machines for classifying large sparse data. They hypothesized that feature interactions seems to be crucial for Click-Through-Rate (CTR) predictions and discussed how degree-2 polynomial mappings and factorization machines [16] handle feature intersections. Richardson et al.[17] proposed the use of features comprising of information about product advertisements, product description, and advertisers to learn a model that accurately predicts the CTR for new advertisements.
To explore the effect of keyword queries on CTR prediction, Regelson et al. [15] hypothesized that keyword terms have a different likelihood of being clicked and hence proposed a novel CTR prediction algorithm to reflect the role of keyword queries. Their algorithm consisted of clusters comprising on keyword terms and observed that clustered historical data leads to accurate CTR estimation. To analyze the effect of other factors towards CR prediction, Chen and Yan [4] proposed a probabilistic factor model to study the impact of position bias under the hypothesis that higher positions advertisements usually get more clicked and Cheng et al. [5] proposed user-specific and demographic-based features that reflect the click behavior of individuals and groups and hence proposed a framework for the personalization of click models in sponsored search.
3 CRITEO PREDICTIVE SEARCH
Section titled “3 CRITEO PREDICTIVE SEARCH”Criteo Predictive Search (CPS) is a recent product from Criteo that was launched at the end of 2016 on selected markets. CPS uses machine learning to automate all aspects of Google Shopping
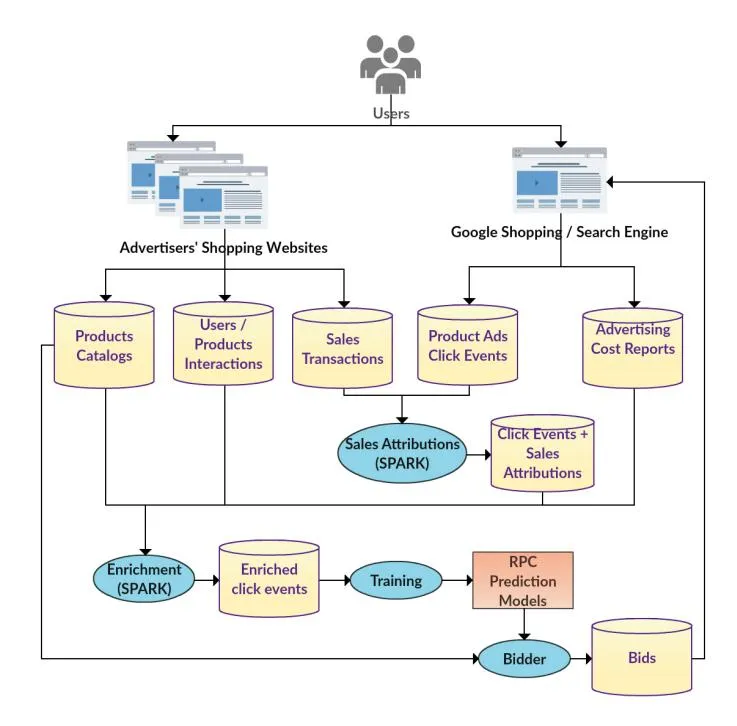
Figure 1: Criteo Predictive Search Data Processing Pipeline
Campaign optimization i.e. bidding, retargeting lists and product matching.
When a Google Shopping user searches for products, Google Shopping selects a list of product advertisements to be embedded in the search results page. Google determines which product advertisements to be displayed to the user by weighing how closely the advertised product matches the user’s query intent, the probability that an advertisement will be clicked by the user, and the bid amount by the advertiser. Google will only charge (second-price auction) for a displayed advertisement if that advertisement is clicked by a user.
CPS combines different types of data to train machine learning models for predicting the return per ad-click (RPC). CPS uses these models to produce daily contextualized bids for every product in an advertiser’s product catalog. These bids are conditioned by different contexts which are determined by the advertised products, users classes, device types, and negative-keywords query filters. The computed bids are optimized to maximize an advertiser’s returnon-investment (ROI) under given cost constraints.
Figure 1, depicts the CPS data processing pipelines. CPS collects data from two sources. From advertisers it collects anonymized data about users interacting with advertiser’s product pages. Also from advertisers it collects detailed data about sales transactions, including information about the buying user, the products being sold and the amount paid. From Google Shopping an Adwords, CPS collects data about ad-click events, including the advertised product, the clicking user, and contextual information (e.g., device type). Also from AdWords it collects daily advertisers’ cost reports, which consists on advertisement costs aggregated by product.
A process called attribution, aims to match sales transactions with the corresponding ad-click event if any. The purpose of sales attribution is to determine the total return attributed to an ad-click, which can be zero if an ad did not originated any sales. The average return-per-click (RPC) is the target that our ML models attempt to predict.
Click events together with their attributed sales information are enriched with product related information from advertisers’ catalogs (e.g., product price, product category) and with statistics about users / products interactions collected from advertisers’ shopping websites (e.g., the number of pages views in the last week for a particular product). Click events data is also enriched with average cost-per-click information computed from AdWords cost reports.
The enriched click events data is used to train a series of machine learning models needed to predict return-per-clicks (RPC). These models are later used by the Bidder to compute the following’s day optimal bid for every product in the advertisers’ catalogs.
4 BACKGROUND
Section titled “4 BACKGROUND”In this section, we would discuss the baseline technique used to model the likelihood of the user engagement with a product advertisement along with the metrics used to evaluate the performance of the models (i.e. proposed models along with the baseline model). Next, we would provide an overview of the real world dataset used to evaluate the performance of our proposed models. Lastly, we discuss the longitudinal model evaluation protocol followed in this manuscript.
4.1 Baseline Model
Section titled “4.1 Baseline Model”We use L2-regularized logistic regression as our baseline approach to model the likelihood of a user engaging with product related advertisement. Specifically, the likelihood of engagement , can be expressed via the link function of a GLM (logistic regression) as follows:
(1)
The model coefficients can be obtained by minimizing the regularized logistic loss, denoted by Negative Log-Likelihood (NLL), as defined below:-
(2)
where in,
- denotes the regularization parameter.
- w denotes the coefficient vector.
- yi denotes the label (1 indicates conversion and -1 indicates no-conversion).
- xi denotes the covariates comprising of information about the product (type, gender, age, attributes, description, color), user(new vs old), etc.
L2-regularized logistic regression was chosen as our baseline approach, as it is quick to update model parameters in the presence of new data instances, billions of inferences can be computed in a reasonable amount of time and the model can be trained on massively sparse datasets comprising millions of explanatory variables. L2-regularized logistic regression is also the method being used currently in production.
4.2 Metrics
Section titled “4.2 Metrics”4.2.1 Log Likelihood Normalized (LLHN). We want our models to predict the probability that an advertisement click will end up in a sale or a conversion. To evaluate our models we want to measure how far the predicted probabilities are from the actual conversion probabilities. Conventional metrics like accuracy, precision, recall and F1-Score, which are usually used to evaluate classification systems, are not sufficiently precise for our purposes. Instead, we would like to rely on metrics related to the likelihood of the test data under the evaluated models.
Given a dataset and a model the likelihood is the probability to observe this dataset assuming the model is true.
Here our dataset is denoted by pair for i = 1..n where the are the features vectors and the are the labels.
We assume that the are independent conditionally on the so we can write
where is the probability predicted by a model.
As the likelihood is positive and that the logarithm is an increasing function, maximizing the likelihood is the same as maximizing the log-likelihood (LLH), and the log-likelihood is a sum which is more practical.
Log-likelihood (LLH), as a metric, is not normalized and hence it cannot be used to compare performances based on different datasets. To overcome this limitation we introduce Log-Likelihood-Normalized which is denoted as LLHN. The LLHN of model corresponds to its LLH relative to the LLH of a naive model.
The naive model is the model that predicts a constant ‘c’ which is the probability that on the test dataset.
and the naive model (naive) does
The LLH(naive) of the naive model is defined as:-
The LLHN is defined as :-
A positive LLHN indicates that our model is better than the naive model. For example, a LLHN value of 0.13 means that our model is 13% “better” than the naive model. A negative LLHN indicates that our model is worse than the naive model. A zero LLHN indicates that our model is equal to the naive model. Ideally, we would like
4.2.2 LLHN-Uplift. The LLHN-Uplift of a model can be defined as the following:
the LLHN value to be as high as possible.
where in
- LLHN(model) denotes the log-likelihood of any proposed model w.r.t naive model.
- LLHN(baseline) denotes the log-likelihood of the baseline model (L2-regularized logistic regression) w.r.t the naive model.
A positive LLHN-Uplift indicates that our model is better than the baseline model. For example, a LLHN-Uplift value of 0.15 means that our model is 15% “better” than the baseline model. A negative LLHN-Uplift indicates that our proposed model is worse than the baseline model. A zero LLHN-Uplift indicates that our model is equal to the baseline model.
4.3 Data
Section titled “4.3 Data”We train our models from CPS traffic logs of click events which combine several sources of information, including attributes of the product being advertised (e.g., product id, price, category, brand, retailer), user shopping behavior information (e.g., engagement level), attributes of the click event (e.g., event time, device), and advertisement performance information (e.g., number of sales and revenue generated). To train models for predicting conversion probabilities we label each event with the event outcome. That is whether that event originated in a conversion or not.
Currently, these logs include several thousand daily events on average. Our models are trained, several times within a day to predict conversion probabilities for millions of advertised products. To train a model to predict conversion probabilities for each product on a particular day we include event’s data spanning a couple of days prior to the day whose conversion probabilities we want to predict. Sample CPS dataset has also been publicly released (http://research.criteo.com/criteo-sponsored-search-conversion-log-dataset/).
4.4 Longitudinal Model Evaluation
Section titled “4.4 Longitudinal Model Evaluation”In this manuscript, we simulate the conditions from the production setting. In the production setting, models are trained everyday to make prediction based on most recent data. Then, for each day in our test dataset we train a corresponding model using only data from a period (last couple of days or weeks) preceding the test day. We then compare the outcome of each test event with the outcome predicted by our trained model to evaluate the efficacy of our model. As an illustration, to make predictions about the user engagement level for the product advertisements on February 23rd, we will train a model build on logs from February 1st until
February 22nd. Similarly, to make predictions on February 24th, we will train a model which is build on traffic logs from February 2nd until February 23th.
5 PROPOSED MODELS
Section titled “5 PROPOSED MODELS”In this section, we would be discussing the techniques used to model the engagement of a user with product related advertisement, while being responsive to changes in user buying or product selling behavior.
5.1 Historic Conversion Rate Feature Model (HCRFM)
Section titled “5.1 Historic Conversion Rate Feature Model (HCRFM)”The first proposed model is an extension of our baseline model in the sense that the model is obtained by adding features which are indicative of the variation in product demand in conjunction with the existing features. The rationale being that the addition of novel features might help the models to better accommodate the effects of changes in user buying or product selling behavior. These features are derived from past aggregate conversion rates at an advertiser level. A higher value of this feature indicates that an advertiser’s products are in demand, whereas a low value of this feature indicates the demand for an advertiser’s products is on decline.
This new conversion rate feature is derived from the function CR(a, d) that computes the conversion rate for advertiser ‘a’ on the calendar day ‘d’ for the ‘ith’ data point
(3)
where in,
- denotes the advertiser corresponding to the event
- denotes the calendar day of the event
Once such features have been constructed, then the modified regularized logistic loss is used to obtain the coefficient parameter .
(4)
5.2 Time Decay Weighting Model (TDWM)
Section titled “5.2 Time Decay Weighting Model (TDWM)”To incorporate the effects of changing catalog and user behavior over time, we hypothesize that models built on data from recent past might be a better fit as compared to models built on data from distant past. In our second proposed model (TDWM) the weight of each data point is given by a time decay function. Data points from the recent past are weighted more as compared to data points from the distant past. To compute the model parameters, the loss function of the baseline model (i.e. logistic regression) is slightly altered and is denoted by weighted-negative-log-likelihood (WNLL).
We define:
WNLL = (5)
Each data point is weighted by , an exponential time decay function with a half life of 5 days. Half-life is defined as the time
taken for a data point to reduce its weight by 50%. The exponential decay function is expressed as,
d(t_i) = 2^{-\frac{\operatorname{age}(t_i)}{5}} \tag{6}
where denotes the time and is the difference expressed in days between and a reference time . We chose the half life to be 5 days based on experimental evaluation.
Figure 2 shows the uplift in LLHN as function of the half life decay. The LLHN uplift is the average of the uplift obtained on five different 7-day periods across all advertisers. The x-axis indicates different half-live values ranging from 3 to 30 days. The y-axis represents the average LLHN-Uplift across five different 7-day periods. As observed, the half-live value of 5 days has the maximum LLHN-Uplift.
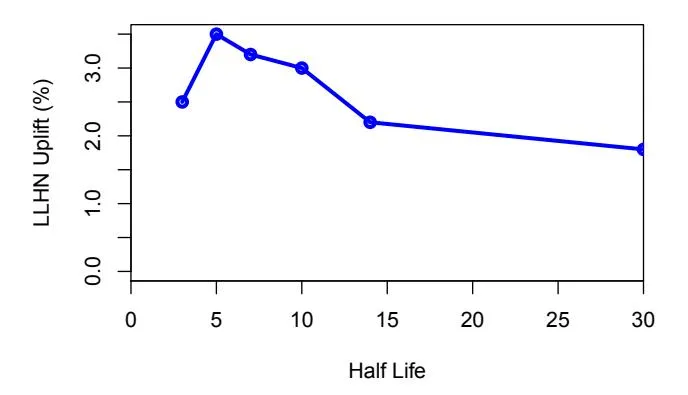
Figure 2: Uplift in LLHN as a function of the half life decay.
5.2.1 Parameter Estimation. We analyze the learning setup proposed in [3] where limited memory BFGS [11, 14] (L-BFGS) is warm-started with stochastic gradient descent [2] (SGD). For both algorithms, we multiply the gradient of the loss of each example by , where is the weight associated with the example i computed by the decay function.
Impact on the regularization parameter. In the case of switching from log loss (NLL, equation-2) to the weighed log loss (WNLL, equation-5) the value of the hyper-parameter for NLL needs to be adapted to WNLL. To do that, we use the following simple rule that adapts depending on the value of the importance weights used, i.e. of the average value of the decay function:
(7)
5.3 Mixture of Long-Term and Short-Term Model (MLTSTM)
Section titled “5.3 Mixture of Long-Term and Short-Term Model (MLTSTM)”Our third proposed model (MLTSTM) is a mixture of long-term and Short-Term models. In this model, the prediction is a weighted average of the prediction from two models, a Short-Term and a Long-Term model. The difference (Short-Term vs Long-Term) lies in the timespan of the data used to train such models. The Short-Term model is trained on data from the recent past whereas the
Long-Term model is trained on data from recent as well as distant past.
The model prediction (denoted by ) is a weighted average of the prediction from two models, a Short-Term and a Long-Term model.
(8)
where in,
- w1 denotes the weight parameter obtained from the Short-Term model
- w2 denotes the weight parameter obtained from the Long-Term model
- E(yi/xi, w1) is obtained from the Short-Term model trained on data from recent past
- E(yi/xi, w2) is obtained from the Long-Term model trained on data from recent as well as distant past
- denotes the average weighting factor and ranges from 0 to 1
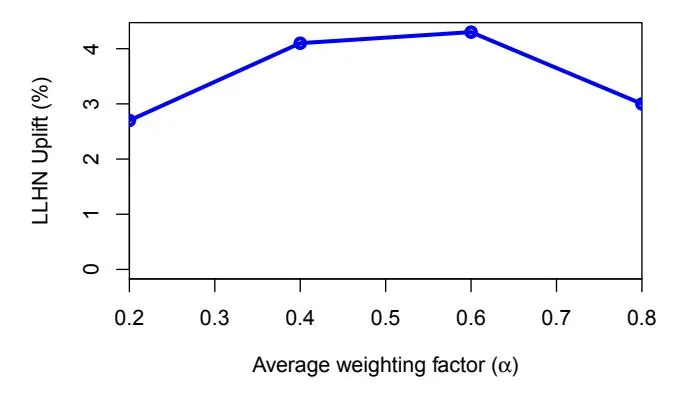
Figure 3: LLHN-Uplift as a function of the average weighting factor .
Figure 3, shows LLHN-Uplift as a function of the average weighting factor . The x-axis indicates different values of . The y-axis is the average LLHN-Uplift across five different 7-day periods. As observed, corresponding to , we observe the best LLHN-Uplift.
6 EXPERIMENTS AND RESULTS
Section titled “6 EXPERIMENTS AND RESULTS”In this section we will first compare the performance of the proposed models when there is considerable variation in product demand against the performance when there is no considerable variations. We carried out this experiment on a controlled group of advertisers who have experienced variations in product demand. Next, we will evaluate the performance of the proposed models during a period known to have high incidence of variations in product demand, namely Black Friday. Both experiments were performed offline based on event logs collected by Criteo’s Predictive Search (see Section 3).
6.1 Evaluating Responsiveness to Variations in Product Demand
Section titled “6.1 Evaluating Responsiveness to Variations in Product Demand”The purpose of this experiment is to compare the responsiveness of the proposed models when there is considerable variation in product demand against the performance when there is no considerable variations. Our hypothesis is that the more pronounced the variation in product demand, the greater the LLHN-Uplift we will observe from the proposed models. Because performances vary significantly across different advertisers, we will compare performances only within single advertisers to avoid introducing additional noise.
Table 1: Traffic volume for the advertisers included in the comparison study of Section 6.1 (daily averages).
| Advertiser | Events | Sales | CR (%) |
|---|---|---|---|
| Advertiser 1 | 21500 | 250 | 1.2 |
| Advertiser 2 | 5500 | 100 | 1.8 |
| Advertiser 3 | 850 | 20 | 2.4 |
| Advertiser 4 | 14550 | 1150 | 7.9 |
| Advertiser 5 | 5500 | 100 | 1.8 |
The aim of this experiment is to compare the performance of the proposed models across periods with different levels of variations in product demand. To carry out this experiment we need a working definition of level of variation in product demand.
We define a metric to measure the level of variation in product demand for an advertiser on a given (narrow) period of time as the ratio between the conversion rate of two periods, one shorter period in the numerator and a longer period in the denominator. We call this metric the Normalized Variation Index (NVI). For the study reported, in this manuscript our NVI metric relied on a seven-day period in the numerator and its preceding 30-day period in the denominator. More formally:
V_d^a = \frac{\operatorname{CR}_{[d,d+6]}^a}{\operatorname{CR}_{[d-30,d-1]}^a} \tag{9}
where denotes the NVI for advertiser a on a period beginning on day d, and is the conversion rate for advertiser a over the period .
Intuitively, the NVI metric indicates the degree at which an advertiser’s conversion rate over a narrow period of time has deviated from a historic conversion rate, which is represented by the normalizing factor in the denominator of the NVI definition. According to this definition, an NVI value close to ‘1’ indicates a period with little or no variation, an NVI value grater than ‘1’ indicates a surge in product demand and an NVI value lower than ‘1’ indicates a drop in product demand. Furthermore, the farther away an NVI value is from ‘1’, it indicates the more extreme the variation in product demand is.
We rely on the NVI metric to select a set of test cases appropriate for this study from the CPS event logs. We wanted to test our hypothesis that the proposed models will be more accurate than the baseline model during periods of extreme variation in product demand. However, we also wanted to test how the proposed models
Table 2: LLHN-Uplift of the proposed models for advertiser’s different levels of variation in product demand
| Model | Adv. 1 | Adv. 2 | Adv. 3 | Adv. 4 | Adv. 5 | ||
|---|---|---|---|---|---|---|---|
| Extreme Variation | |||||||
| HCRFM | 54.3 | 81.6 | 180.1 | 13.8 | 229.4 | ||
| TDWM | 70.5 | 47.3 | 257.5 | 20.1 | 361.6 | ||
| MLTSTM | 90.1 | 124.6 | 340.2 | 25.6 | 596.6 | ||
| Average Variation | |||||||
| HCRFM | 2.4 | 0.9 | -6.0 | 56.2 | 37.2 | ||
| TDWM | 7.0 | -2.7 | 22.0 | 198.0 | 73.4 | ||
| MLTSTM | 7.7 | -0.7 | 11.1 | 217.3 | 79.1 | ||
| Moderate Variation | |||||||
| HCRFM | 0.1 | -1.7 | 1.9 | -18.2 | -1.2 | ||
| TDWM | 6.2 | -9.8 | -9.6 | 6.7 | -6.9 | ||
| MLTSTM | 4.2 | -8.1 | -14.4 | -4.8 | -5.6 |
compare to the baseline on periods of average and moderate variation. In order to carry out these tests we defined three different conditions of interests for this study based on how extreme an NVI value is. The three conditions are extreme variation, average variation and moderate variation. These conditions were defined as follows:
(10)
Where f(a,d) denotes the level of variation in product demand for advertiser a during period d, is the NVI of advertiser a over period d as defined by equation (9). The four range boundary constants 0.05, 0.07, 0.29, and 0.34 were chosen based on a distribution of NVI values for all advertisers and all periods within a 3 months worth of events logs data. These boundaries corresponded to the quantiles 0.20, 0.25, 0.75, and 0.80 respectively.
We then scanned our events logs to select a set of advertisers that have experienced periods in all three different levels of variation in product demand. While selecting advertisers we also procured to obtain a diverse set of advertisers, which are representative of different sale markets and traffic volume levels. Table 1, lists the daily average number of events and conversions for each one of the selected advertisers for this study.
Figure 4, plots the changes in NVI over time for the five advertisers selected for this study. The plots also identify the three regions corresponding to the three conditions of interest for this study, extreme (blue), average (yellow) and moderate (pink). For each advertiser, the three time periods selected to represent the three conditions of interest for this study are indicated by a small square on top of the NVI plot. For example, we can observe that for Advertiser 1 (Figure 4a), the variation on product demand is almost neutral (NVI value close to 1) during the first few weeks of December up to December 16. Then the product demand starts to drop until reaching an extreme NVI level of 0.6 on December 23. This means that during the 7-day period starting on December 23, CR is down at a 60% of this advertiser’s historic CR.
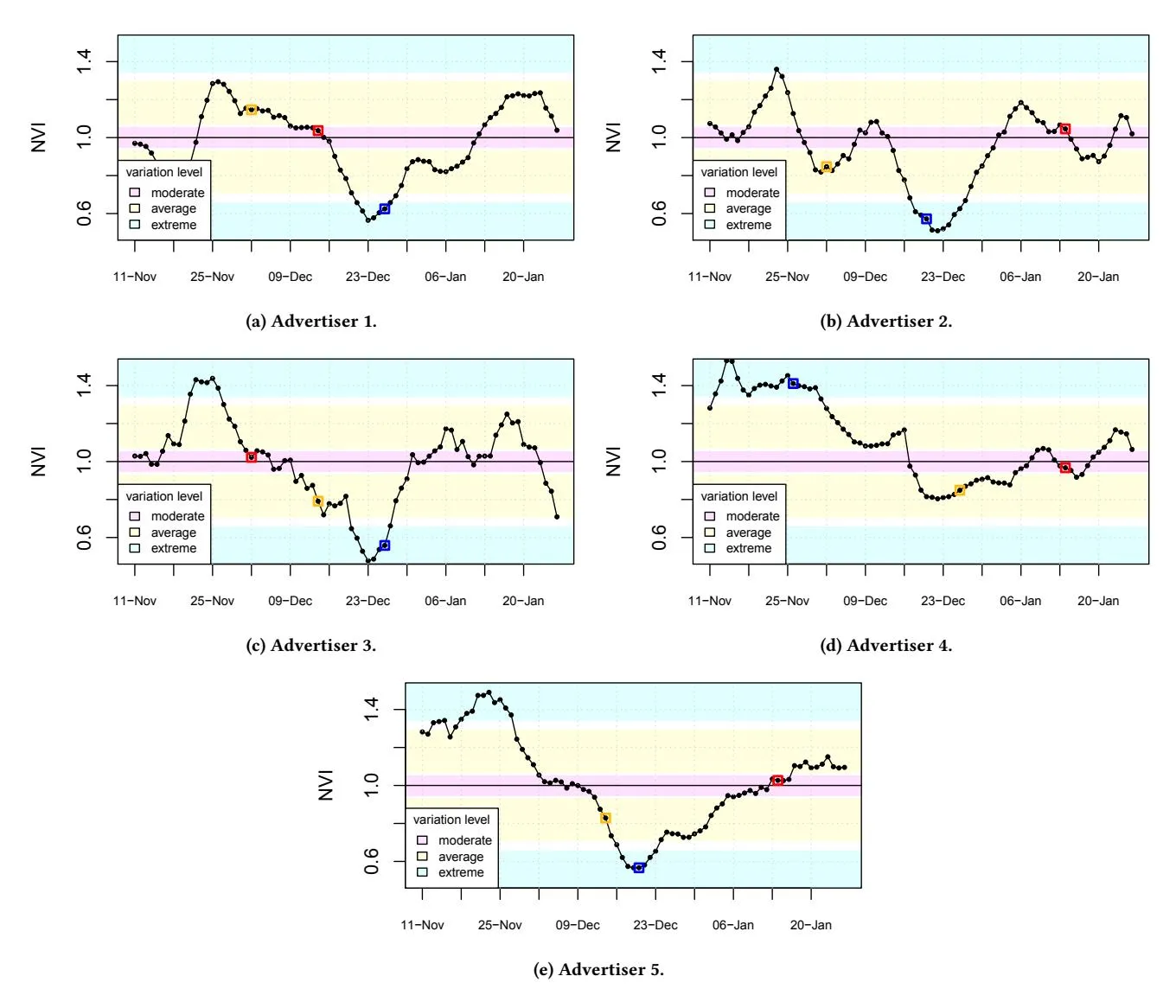
Figure 4: Advertisers normalized variation index (NVI) over time.
Table 2, compares the proposed models performance for five advertisers on periods of extreme, average, and moderate variation in product demand. The table indicates the LLHN-Uplift of the proposed models compared to the baseline. We observe that for most advertisers, the more extreme the variation in product demand the better the performance of the proposed models in relation to the baseline. We also observe that most of the time the performance of the MLTSTM model dominates under the extreme and average conditions and HCRFM model does best under the moderate conditions. Sometimes, under moderate conditions the performance of the proposed models is worse than the baseline. However, the loss in performance during moderate conditions are less pronounced than the gains in performance during extreme conditions. Both conditions, moderate and extreme, are equally rare under this experimental settings.
6.2 Black Friday season
Section titled “6.2 Black Friday season”The constraints imposed by the study described in Section 6.1, determined that only a small sample of advertisers were eligible, which might bring into question the significance of its results. Experiments discussed in this section, aim to compensate for the limitations of the above study by bringing a more comprehensive sample of advertisers at the expense of performing a direct comparison across different levels of variation in product demand.
In this study we evaluated the proposed models on all of U.S. advertisers during a 7-day period that included Black Friday. The rationale for this study is the belief that a significant fraction of these advertisers for the U.S. market will experience extreme variations during the selected period.
Table 3, shows the LLHN-Uplift of the proposed models when aggregating across all U.S. advertisers during the selected period. Models TDWM and MLTSTM show a positive uplift, although a modest one. The largest uplift was 3.20% for model MLTSTM. Although this uplift might seem small, we should take into account that the impact of the proposed models might have been diluted when considering it in the aggregated context. The proposed models were conceived specifically to improve the prediction performance during periods of steep variations in product demand. However, our aggregated sample includes several advertisers that have not experienced variations in product demand.
Table 3: LLHN-Uplift of the proposed models during a Black Friday week over all US advertisers..
| Model | LLHN-Uplift (%) |
|---|---|
| HCRFM | 0.2 |
| TDWM | 2.9 |
| MLTSTM | 3.2 |
Table 4: Performance (LLHN-Uplift) of the proposed models during a Black Friday week for the top US advertisers.
| Advertiser | Extremeness | HCRFM | TDWM | MLTSTM |
|---|---|---|---|---|
| 1 | 1.81 | 62.1 | 239.4 | 409.2 |
| 2 | 0.94 | -2.9 | 117.6 | 136.2 |
| 3 | 0.41 | 0.7 | 15.7 | 18.2 |
| 4 | 0.40 | 0.5 | -2.7 | -7.2 |
| 5 | 0.36 | 0.3 | 5.9 | 1.2 |
| 6 | 0.25 | 0.0 | 7.4 | 6.7 |
| 7 | 0.17 | -0.6 | 10.3 | 10.8 |
| 8 | 0.12 | 0.9 | -0.1 | -1.0 |
| 9 | 0.11 | 0.3 | -0.8 | -0.6 |
| 10 | 0.02 | 0.5 | 2.3 | 4.3 |
Table 4, on the other hand, presents a more focused analysis. It shows the performance of the proposed models for each of our top ten U.S. advertisers in terms of traffic volume. The table lists advertisers in NVI extremeness decreasing order. Here, NVI extremeness is where is the NVI metric as defined in equation (9). In general, we can observe that the more extreme the NVI the better the performance of the proposed models are relative to the performance of the baseline model.
Alternatively, in Figure 5, we present individual scatter plots for the proposed models. For each proposed model, we present the NVI extremeness on the x-axis and LHHN-Uplift on the Y-axis. As depicted in the graphs, we observe that for model MLTSTM, LLHN-Uplift is very high for the advertiser which has high NVI extremeness values. Similar, is the trend observed for the scatter plot obtained from the model TDWM. Such high LLHN uplifts can be attributed to the fact that these models i.e. TDWM and MLTSTM are better able to handle variations in user buying or product selling behavior as compared to the HCRFM model.
7 CONCLUSION
Section titled “7 CONCLUSION”In this work, we proposed three CR prediction models which are robust to variations in product demand. In the first model (HCRFM) we extended the baseline model by adding novel features which are indicative of variation in product demand. The second technique (TDWM) consists of a model in conjunction with importance weighting [18], where in data from the recent past is weighted more as compared to data from the distant past during model training, and lastly we propose mixture models (MLTSTM) i.e. models consisting of our original model along with a model trained on more recent data.
In this work we also defined a novel metric to measure the variation in the product demand of an advertiser on a given (narrow) period of time and observe the different variations as exhibited by multiple advertisers over time. Using this metric, we observe the performance of the proposed models over an advertisers different variation conditions i.e. moderate, extreme and average. We observed that for most advertisers, the more extreme the product demand variation condition the better the performance of the proposed models w.r.t the baseline model.
Further, to evaluate the performance of the proposed models during periods of high variation, we evaluated the performance of the proposed models on all of U.S. advertisers during a 7-day period that included Black Friday (high product variation season) and observe the positive uplift in LLHN obtained by using the TDWM and MLTSTM models. We also analyze the performance of the proposed models on each of our top ten U.S. advertisers during the Black-Friday period and observed that maximum uplift was associated with the advertiser which experiences the highest product demand variation.
Our results demonstrate that our proposed models (i.e. HCRFM, TDWM and MLTSTM) can help us to better model the engagement between the user and product related advertisement. These models achieve it by weighing data samples in the recent past a bit higher as compared to the data samples from the distant past. Such modeling can then help us to avoid over-predicting the engagement levels when there is a drop in product demand and to avoid underpredicting the engagement levels when there is a surge in product demand. In future, we would like to explore non-linear modeling techniques such as Gradient Boosting Decision Trees (GBDTs) and Convolution Neural Networks (CNNs) to compute the engagement between the user and product advertisement subject to the constraints (i.e. fast update of the model parameters given new data, computing inferences for billion of products in minute fraction of time, model training on extremely sparse datasets).
REFERENCES
Section titled “REFERENCES”- Deepak Agarwal, Rahul Agrawal, Rajiv Khanna, and Nagaraj Kota. 2010. Estimating rates of rare events with multiple hierarchies through scalable log-linear models. In Proceedings of the 16th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 213–222.
- [2] Léon Bottou. 2010. Large-scale machine learning with stochastic gradient descent. In Proceedings of COMPSTAT’2010. Springer, 177–186.
- [3] Olivier Chapelle, Eren Manavoglu, and Romer Rosales. 2015. Simple and scalable response prediction for display advertising. ACM Transactions on Intelligent Systems and Technology (TIST) 5, 4 (2015), 61.
- [4] Ye Chen and Tak W Yan. 2012. Position-normalized click prediction in search advertising. In Proceedings of the 18th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 795–803.
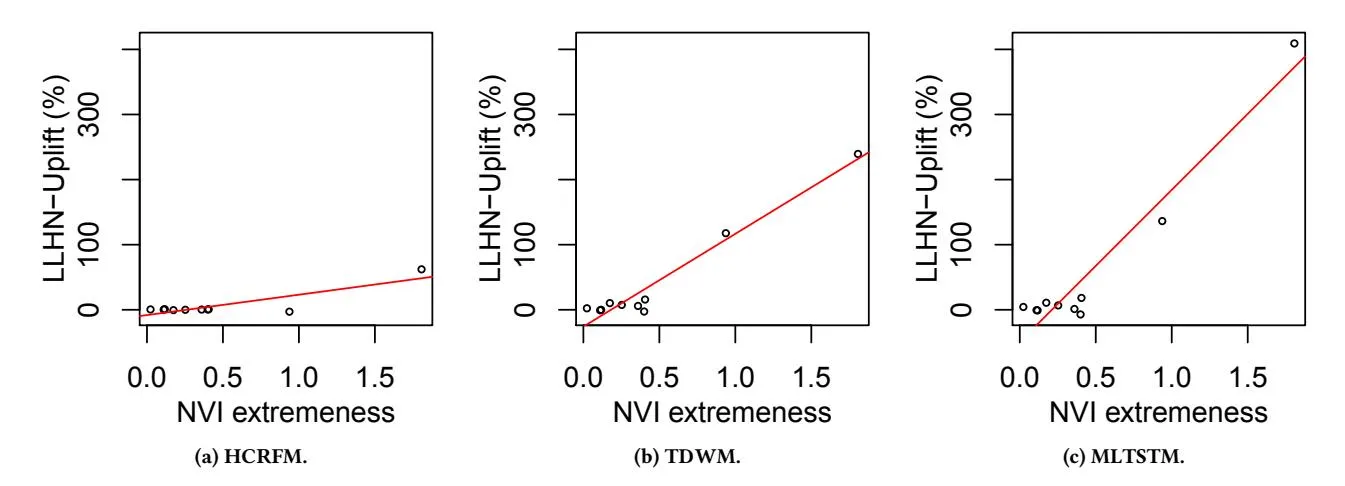
Figure 5: Relationship between normalized variation index (NVI) and LLHN-Uplift during Black Friday period for the 10 advertisers.
- [5] Haibin Cheng and Erick Cantú-Paz. 2010. Personalized click prediction in sponsored search. In Proceedings of the third ACM international conference on Web search and data mining. ACM, 351–360.
- [6] Daniel C Fain and Jan O Pedersen. 2006. Sponsored search: A brief history. Bulletin of the Association for Information Science and Technology 32, 2 (2006), 12–13.
- [7] Xinran He, Junfeng Pan, Ou Jin, Tianbing Xu, Bo Liu, Tao Xu, Yanxin Shi, Antoine Atallah, Ralf Herbrich, Stuart Bowers, et al. 2014. Practical lessons from predicting clicks on ads at facebook. In Proceedings of the Eighth International Workshop on Data Mining for Online Advertising. ACM, 1–9.
- [8] Zilong Jiang. 2016. Research on ctr prediction for contextual advertising based on deep architecture model. Journal of Control Engineering and Applied Informatics 18, 1 (2016), 11–19.
- [9] Yuchin Juan, Yong Zhuang, Wei-Sheng Chin, and Chih-Jen Lin. 2016. Fieldaware factorization machines for CTR prediction. In Proceedings of the 10th ACM Conference on Recommender Systems. ACM, 43–50.
- [10] Mervyn King, Jill Atkins, and Michael Schwarz. 2007. Internet advertising and the generalized second-price auction: Selling billions of dollars worth of keywords. The American economic review 97, 1 (2007), 242–259.
- [11] Dong C Liu and Jorge Nocedal. 1989. On the limited memory BFGS method for large scale optimization. Mathematical programming 45, 1 (1989), 503–528.
- [12] Peter McCullagh. 1984. Generalized linear models. European Journal of Operational Research 16, 3 (1984), 285–292.
- [13] H Brendan McMahan, Gary Holt, David Sculley, Michael Young, Dietmar Ebner, Julian Grady, Lan Nie, Todd Phillips, Eugene Davydov, Daniel Golovin, et al. 2013. Ad click prediction: a view from the trenches. In Proceedings of the 19th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 1222–1230.
- [14] Jorge Nocedal. 1980. Updating quasi-Newton matrices with limited storage. Mathematics of computation 35, 151 (1980), 773–782.
- [15] Moira Regelson and D Fain. 2006. Predicting click-through rate using keyword clusters. In Proceedings of the Second Workshop on Sponsored Search Auctions, Vol. 9623.
- [16] Steffen Rendle. 2010. Factorization machines. In Data Mining (ICDM), 2010 IEEE 10th International Conference on. IEEE, 995–1000.
- [17] Matthew Richardson, Ewa Dominowska, and Robert Ragno. 2007. Predicting clicks: estimating the click-through rate for new ads. In Proceedings of the 16th international conference on World Wide Web. ACM, 521–530.
- [18] Flavian Vasile, Damien Lefortier, and Olivier Chapelle. 2016. Cost-sensitive learning for utility optimization in online advertising auctions. arXiv preprint arXiv:1603.03713 (2016).
- [19] Robbin Lee Zeff and Bradley Aronson. 1999. Advertising on the Internet. John Wiley & Sons, Inc.
- [20] Yuyu Zhang, Hanjun Dai, Chang Xu, Jun Feng, Taifeng Wang, Jiang Bian, Bin Wang, and Tie-Yan Liu. 2014. Sequential Click Prediction for Sponsored Search with Recurrent Neural Networks.. In AAAI. 1369–1375.